16.1 Advisor ウィザードを使う
Advisor ウィザードを使うには:
- Analysis タブにある SigmaStat グループから Advisor をクリックします。
- Advisor Wizard が現れたら、これから行う内容とお持ちのデータ形式に関する質問に答えます。次のパネルに進むには Next をクリックします。前のパネルに戻るには Back を、提示される検定を表示するには Finish を、Advisor Wizard を閉じるには Cancel をクリックします。
- Advisor Wizard で検定が提案されたら、Run をクリックしてその検定を実行します。提案された検定ごとに Select Data パネルが表示されますので、お持ちのデータの検定を行いたいワークシート列を選択してください。
本セクションの残りの部分では、各ダイアログボックスに表示される質問に対する答えを説明します。
- これから行うことを選択してください
- データはどのように測定されていますか?
- お持ちのデータには、生存時間に影響を及ぼす潜在的な危険因子が含まれていますか?
- 被験者1人に対して複数の処理を適用しましたか?
- 群または処理の数は幾つですか?
- お持ちのデータの種類は何ですか?
- これから行う予測の種類は何ですか?
- 使用する曲線の種類は何ですか?
- 独立変数はどのように指定しますか?
- 独立変数を SigmaPlot で選ぶ方法はどうしますか?
- 研究は後向きですか、それとも、前向きですか?
1. これから行うことを選択してください
(Select what you need to do)
お持ちのデータにふさわしい検定を割り当てる最初のステップは、遂行したい内容を指定することです。Advisor Wizard では、まずはじめに以下に示すどれが必要かが質問されます:
- 基本統計量を使ってデータを説明する (Describe your data with basic statistics)。単一または複数列のデータに関する記述統計量をリストで表示したい場合は、このオプションを選択します。詳細は、基本統計量でデータを説明する をご覧ください。
- 群や処理を比較して有意差を検定する (Compare groups or treatments for significant differences)。データを比較して有意差を検定したい場合は、このオプションを選択します。例えば、異なる薬剤処置を受けた人々の平均血圧を比較したいような場合です。比較対象となるデータには、異なる群から収集されたデータ、同一被験者に異なる処理を行ったデータ、異なる群の分布や比率があります。Next をクリックします。お持ちのデータがどのような方法で測定されたかが質問されます。詳細は、2. データはどのように測定されていますか? をご覧ください。
- 傾向の予測、相関関係の検出、または、曲線のあてはめを行う (Predict a trend, find a correlation, or fit a curve)。単一または複数の独立変数をもとに、従属変数を予測する回帰を使用したい場合、または、2変数間の関連性の強さを相関係数で説明したい場合は、このオプションを選択します。例えば、ある動物の体重からその平均カロリー摂取量を予測できるかどうかを調べたい場合は、このオプションを選択します。Next をクリックします。お持ちのデータがどのような方法で測定されたかが質問されます。詳細は、2. データはどのように測定されていますか? をご覧ください。
- 実験計画に必要なサンプルサイズを決定する (Determine the sample size for an experimental design)。これから実行したい実験に必要なサンプルサイズを決めたい場合は、このオプションを選択します。Next をクリックします。お持ちのデータがどのような方法で測定されたかが質問されます。詳細は、2. データはどのように測定されていますか? をご覧ください。
- 実験計画の感度を決定する (Determine the sensitivity of an experimental design)。これから実行したい実験の効果を検出するための検出力、すなわち検定能力を決定したい場合は、このオプションを選択します。Next をクリックします。お持ちのデータがどのような方法で測定されたかが質問されます。詳細は、2. データはどのように測定されていますか? をご覧ください。
- 処理と事象との間の関連性の強度を測定する (Measure the strength of association between a treatment and an event)。ある処理やある危険因子と、母集団のメンバーで発生する特定の事象との間の関連性の強度を測定したい場合は、このオプションを選択します。Next をクリックします。これから行う研究が後ろ向き (retrospective) か前向き (prospective) かが質問されます。詳細は、11. 研究は後向きですか、それとも、前向きですか? をご覧ください。
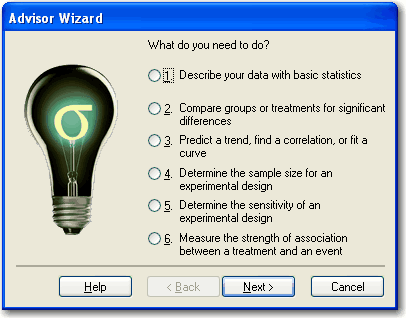
図 2.1:アドバイザー・ウィザード
2. データはどのように測定されていますか?
(How are the data measured?)
これから行う検定を決定するためには、殆どのプロシージャで、検定に使用するデータがどのような形で測定 (計量) されたかに答える必要があります。
データ測定の手段には4つの方法が考えられます:
- 数値データとして (By numeric values)。お持ちのデータが数字を使って連続的な尺度で測定されている場合は、By numeric values を選択します。数値 (numeric value) とは、例えば、高さ、重さ、濃度、年齢など、値と値の間に算術的に計算可能な関係が存在する任意の測定データが該当します。
- 複数の群や処理間の違いを比較する場合は、同一個体に反復測定を行ったかどうかが質問されます。詳細は、4. 被験者1人に対して複数の処理を適用しましたか? をご覧ください。
- 傾向を予測する場合は、これから実行したい予測のタイプを選択するよう求められます。詳細は、7. これから行う予測の種類は何ですか? をご覧ください。
- 実験計画におけるサンプルサイズや感度 (sensitivity) を決定する場合は、群や処理が幾つあるかが質問されます。詳細は、5. 群または処理の数は幾つですか? をご覧ください。
- 順序や順位として (By order or rank)。お持ちのデータが順序関係をあらわす順位尺度 (rank scale) で計量されており、値と値の間に算術的に計算可能な関係が存在しない場合は、By order or rank を選択します。
例えば、臨床ステータスでは、次のような順序尺度で測定されることが多くあります。健常 = 1、調子が悪い = 2、病気 = 3、入院中 = 4、死亡 = 5。このような格付け (ratings) は、死亡していることが健常であることよりも状態が悪いことをあらわすものですが、死亡が健常より状態が5倍悪いことをあらわしているのではありません。
- 複数の群や処理間の違いを比較する場合は、同一個体に反復測定を行ったかどうかが質問されます。詳細は、4. 被験者1人に対して複数の処理を適用しましたか? をご覧ください。
- 傾向を予測する場合は、Finish をクリックします。Advisor により、スピアマンの順位相関 (Spearman Rank Correlation) を計算するよう提案されます。詳細は、スピアマンの順位相関 をご覧ください。
- 測定の比率や件数として (例:男性対女性) (By proportion or number of observations (for example, male vs. female))。カテゴリ別の件数や個体数をカウントする名義尺度 (nominal scale) でお持ちのデータが測定されており、カテゴリ間 (民主党員と共和党員など) に関連性が存在しない場合は、By proportion or number of observations in categories を選択します。
- 複数の群や処理間の違いを比較する場合は、同一個体に反復測定を行ったかどうかが質問されます。詳細は、4. 被験者1人に対して複数の処理を適用しましたか? をご覧ください。
- 傾向を予測する場合は、Finish をクリックします。SigmaPlot により Multiple Logistic Regression を実行するよう提案されます。Run をクリックすると検定が実行され、Cancel をクリックすると Advisor Wizard を終了し、ワークシートに戻ります。この検定に関する詳細は、Help をクリックしてください。詳細は、多重ロジスティック回帰 をご覧ください。
- 実験計画におけるサンプルサイズや感度 (sensitivity) を決定する場合は、データがどのような形式であるかが質問されます。詳細は、6. お持ちのデータの種類は何ですか? をご覧ください。
- 生存時間として (By survival time)。お持ちのデータがある事象 (event) の発生時間に対応する測定値の場合は、By survival time. を選択します。ここで言う事象には、一般に死 (death) があてはまりますが、モーター故障や移植血管閉鎖といった、死以外の事象についても同様に有効です。
- 生存データの統計量を説明したい場合や、複数の生存群の有意差を比較したい場合は、お持ちのデータに生存時間に影響を及ぼす潜在的な危険因子が含まれているか否かが質問されます。
- 複数の生存群の有意差を比較する場合は、生存時間の精度が後になるほど低いかどうかが質問されます。
3. お持ちのデータには、生存時間に影響を及ぼす潜在的な危険因子が含まれていますか?
(Does your data include potential risk factors that may affect survival time?)
- いいえ (No)。考慮するデータの精度が全て均質である場合は、No を選択します。Advisor Wizard によって提案されるのは、LogRank 検定の使用です。詳細は、ログランク生存分析 をご覧ください。
- はい (Yes)。生存時間の精度が初期に比べて後の方が低いと考える場合は、Yes を選択します。例えば、打ち切りの値が時間が後になるほど多くなる場合は、これに該当します。Advisor Wizard によって使用が提案される検定は、この事例の場合、Gehan-Breslow 検定となります。詳細は、ゲーハン=ブレスロー生存分析 をご覧ください。
4. 被験者1人に対して複数の処理を適用しましたか?
(Did you apply more than one treatment per subject?)
複数の群や処理を比較したり、サンプルサイズや検出力を決定する場合、お持ちのデータが連続的な数値尺度で測定されているのであれば、既に行われた測定、あるいは、これから行う測定の対象が同一被験者であるか、それとも、異なる被験者であるかを必ず指定します。Yes または No を選択したら、Next をクリックします。
- はい (Yes)。測定値が同一の被験者に対して異なる処理が行われたものである場合は、Yes と答えます。同一個体に対する単一または複数の異なる処理や状態の変化について、事前と事後で比較するときは Yes を選択してください。
例えば、実験の被験者のコレステロール値について食生活の変化による効果を検定したり、政治討論の前と後における同一有権者の世論調査を行う場合は、Yes を選択します。
- 複数の群を算術または順位尺度で比較する場合は、群や処理の数を指定するよう指示されます。詳細は、 5. 群または処理の数は幾つですか?, をご覧ください。
- 群の比率や分布をカテゴリで比較する場合は、Finish をクリックします。SigmaPlot により マクネマーの検定を実行するよう提示されます。詳細は、マクニマーの検定 をご覧ください。このプロシージャの結果については、その解説を表示させることもできます。詳しくは、マクニマーの検定の結果を解釈する をご覧ください。
- いいえ (No)。測定値がそれぞれ異なる被験者から得られたものである場合は、No と答えます。異なる群の間に違いが存在するか否かを調べる場合、例えば、3つの異なる集団からなるゾウの体重を比較するような場合は、測定を繰り返していることにはなりません。Yes を選択するのは、同一個体に対する単一または複数の処理について、事前と事後の結果を比較する場合のみとなります。
- 複数の群を算術または順位尺度で比較する場合は、群や処理の数を指定するよう指示されます。詳細は、5. 群または処理の数は幾つですか? をご覧ください。
- 群の比率や分布をカテゴリで比較する場合は、お持ちのデータがどのような種類かが尋ねられます。詳細は、6. お持ちのデータの種類は何ですか? をご覧ください。
5. 群または処理の数は幾つですか?
(How many groups or treatments are there?)
群や処理を比較したり、サンプルサイズや検出力を決定する場合、お持ちのデータが連続的な数値または順位尺度 (rank scale) として測定されているのであれば、SigmaPlot によって、それに関係する処理または条件の数が尋ねられます。群の数を指定した後に、さらに幾つかの質問に答えるか、途中で検定を決定させることがます。
| ※ Tip |
| Finish をクリックすると検定が提示され、Run をクリックするとそれが実行されます。Back をクリックして前のダイアログボックスに戻ったり、Cancel をクリックしてワークシートに戻ったり、あるいは、Help をクリックして Advisor Wizard の使用に関する情報を調べることも可能です。 |
以下に示すいずれかを選択してください:
- One (1つ)。異なる実験群が1つしかない場合は、このオプションを選択します。詳しくは、一標本 t 検定 をご覧ください。
- Two (2つ)。異なる実験群が2つある場合、または、被験者が2つの異なる処理を受ける場合は、このオプションを選択します。
例えば、男女間のホルモン濃度の違いを比較する場合や、個体における薬剤治療の前後の変化を測定する場合は、群は2つになります。
- 異なる2群を算術尺度で比較する場合は、独立の t 検定 (対応のない t 検定) が SigmaPlot により提示されます。詳しくは、対応のない t 検定 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることもできます。詳しくは、t 検定の結果を解釈する をご覧ください。
- 算術尺度による2群の比較に対するサンプルサイズや検出力を決定する場合は、t 検定のサンプルサイズまたは検出力の計算を実行するよう SigmaPlot により提示されます。この検定の検出力を決定することもできます。詳しくは、検出力とサンプルサイズの計算 をご覧ください。
- 異なる2つの処理を受ける同一被験者を算術尺度で比較する場合は、SigmaPlot により対応のある t 検定 (Paired t-test) の実行が提示されます。詳しくは、対応のある t 検定 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることもできます。詳しくは、対応のある t 検定の結果を解釈する をご覧ください。
- 2つの処理を受ける同一被験者の算術尺度による比較に対してサンプルサイズや検出力を決定する場合は、対応のある t 検定のサンプルサイズまたは検出力の計算を実行するよう SigmaPlot により提示されます。詳しくは、検出力とサンプルサイズの計算 をご覧ください。
- 2つの異なる群を順位尺度で比較する場合は、SigmaPlot により、マン=ホイトニーの順位和検定 (Mann-Whitney Rank Sum Test) の実行が提示されます。詳しくは、マン=ホイトニーの順位和検定 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることもできます。詳しくは、順位和検定の結果を解釈する をご覧ください。
- 2つの異なる処理を受ける同一被験者を順位尺度で比較する場合は、SigmaPlot によりウィルコクソンの符号付き順位検定 (Wilcoxon Signed Rank Test) を実行するよう提示されます。詳しくは、ウィルコクソンの符号付き順位検定 をご覧ください。このプロシージャで得られた結果を表示させることもできます。詳しくは、符号付き順位検定の結果を解釈する をご覧ください。
- Three or more (3つ以上)。比較する群が3つ以上の異なる群である場合、または、3つ以上の異なる処理を受ける同一被験者の応答を比較する場合は、このオプションを選択します。
例えば、民族の多様性について異なる5つの都市からデータを収集する場合、または、個々の被験者を一連の4つの食事変更の下に置き、その血清コレステロール値の変化を測定する場合、3つ以上の群を分析する場合です。
- 3つ以上の異なる群を算術尺度で比較する場合は、SigmaPlot により一元配置分散分析 (One Way ANOVA) の実行が提示されます。詳しくは、一元配置分散分析 (ANOVA) をご覧ください。
- 3つ以上の異なる群の算術尺度による比較に対してサンプルサイズや検出力を決定する場合は、SigmaPlot により一元配置分散分析 (One Way ANOVA) のサンプルサイズ計算が提示されます。詳しくは、検出力とサンプルサイズの計算 をご覧ください。
- 3つ以上の異なる処理を受ける同一被験者を算術尺度で比較する場合は、SigmaPlot により反復測定一元配置分散分析 (One Way Repeated Measures ANOVA) が提示されます。詳しくは、一元配置反復測定分散分析 (ANOVA) をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳細は、一元配置反復測定分散分析の結果を解釈する をご覧ください。
- 3つ以上の異なる群を順位尺度で比較する場合は、SigmaPlot によりクラスカル=ウォリスの順位に基づく分散分析 (Kruskal-Wallis ANOVA on Ranks) が提示されます。詳しくは、クラスカル=ウォリスの順位に基づく分散分析 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳細は、順位に基づく分散分析の結果を解釈する をご覧ください。
- 3つ以上の異なる処理を受ける同一被験者を順位尺度で比較する場合は、SigmaPlot によりフリードマンの順位に基づく反復測定分散分析 (Friedman Repeated Measures ANOVA on Ranks) が提示されます。詳しくは、フリードマンの順位に基づく反復測定分散分析 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳細は、順位に基づく反復測定分散分析の結果を解釈する をご覧ください。
- 考慮する群や処理の組み合わせが2つあります (例:異なる都市の男性と女性) (There are two combinations of groups or treatments to consider (for example, males and females from different cities))。各実験の被験者が、異なる2つの実験因子によって影響を受ける場合、または、異なる2つの処理を同時に受ける場合は、このオプションを選択します。なお、因子の水準の違い、例えば、ジェンダーで言えば男性と女性については、異なる因子としては考慮しない点に注意してください。
例えば、男性と女性のみを比較する場合の因子は、1つしかないことになります。しかし、男性と女性を国別で比較する場合は、ジェンダーと国籍という因子が2つ存在することになります。
- 3つ以上の異なる群を算術尺度で比較する場合は、SigmaPlot により、二元配置分散分析 (Two Way ANOVA) を実行するよう提示されます。詳しくは、二元配置分散分析 (ANOVA) をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳細は、二元配置分散分析の結果を解釈する をご覧ください。
- 反復する3つ以上の処理を受ける同一被験者を算術尺度で比較する場合は、SigmaPlot により、反復測定二元配置分散分析 (Two Way Repeated Measures ANOVA) が提示されます。なお、反復処理される因子は片方でも両方でも構いません。詳しくは、二元配置反復測定分散分析 (ANOVA) をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、二元配置反復測定分散分析の結果を解釈する をご覧ください。
- 考慮する群の組み合わせが3つあります (There are three combinations of groups to consider)。各実験の被験者が異なる3つの実験因子によって影響を受ける場合、または、異なる3つの処理を同時に受ける場合は、このオプションを選択します。なお、因子の水準の違い、例えば、ジェンダーで言えば男性と女性、国籍で言えばイタリア人とドイツ人については、異なる因子としては考慮しない点に注意してください。
例えば、イタリアとドイツ出身の男性と女性を比較するだけなら因子は2つのみです。しかし、異なる国籍の男女を、異なる食生活で比較する場合は、ジェンダー、国籍、食生活という因子が3つ存在することになります。
このオプションを選択すると、SigmaPlot により三元配置分散分析 (Three Way ANOVA) の実行が提示されます。詳しくは、三元配置分散分析 (ANOVA) をご覧ください。
- これは2変数間の関連性の尺度です (This is a measure of the association between two variables)。検出力またはサンプルサイズを決定する場合は、このオプションも同時に表示されます。SigmaPlot により、相関係数の検出力またはサンプルサイズの計算を実行するよう提示されます。
6. お持ちのデータの種類は何ですか?
(What kind of data do you have?)
カテゴリ別の割合で配置されるデータの種類には、2つの場合があり得ます。
| ※ Tip |
| お持ちのデータの種類を指定した後は、Finish をクリックして提示される検定を表示させるか、Back をクリックして前のパネルに戻るか、あるいは、Cancel をクリックして Advisor Wizard を終了し、ワークシートに戻ることができます。Run をクリックすると検定を実行し、Cancel をクリックするとワークシートに戻ります。また、提示された検定に関する情報を Help をクリックして調べることもできます。 |
以下のいずれかを選択します:
- 分割表 (A contingency table)。お持ちのデータが分割表の形式である場合は、このオプションを選択します。分割表とは、幾つかのカテゴリに分類される異なる群の観測数を表示する手段です。例えば、共和党または民主党の候補者に投票した男女別の数をこれであらわします。カテゴリ分けされた群の期待および予測分布の間に差があるかどうかを調べる場合に、このようなテーブルを使用します。
分割表では、その行と列に群とカテゴリを使用し、各組の観測数をそれぞれのセルに配置します。詳しくは、分割表 をご覧ください。
分割表を選択した場合は、SigmaPlot により分割表のカイ二乗分析 (Chi-Square Analysis of Contingency Tables) を実行するよう提示されます。詳しくは、分割表のカイ二乗分析 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、 分割表のカイ二乗分析の結果を解釈する をご覧ください。
- 観測の割合 (Observed proportions)。2群のサンプルサイズと、1カテゴリに分類される各群の割合をあらわすデータをお持ちの場合は、このオプションを選択します。このデータは、あるカテゴリに分類される異なる2群の割合の間に差があるかどうかを調べる場合に使用します。詳しくは、z 検定のデータを配置する をご覧ください。
このオプションを選択した場合は、SigmaPlot により割合の比較 (Compare Proportions) が提示されます。詳しくは、z 検定を使って割合を比較する をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、割合の比較結果を解釈する をご覧ください。
7. これから行う予測の種類は何ですか?
(What kind of prediction do you want to make?)
連続的な数値尺度で測定されたデータをお持ちで、それを使って傾向を予測したり、相関を求めたり、あるいは、曲線のあてはめを行う場合は、これから実行しようとする予測の種類が質問されます。単一または複数の独立変数から1つの従属変数の予測を試みる場合、選択できる目標は3種類あります。実行する予測の種類を選択したら、そこで使用する検定の種類について追加の質問や提案が SigmaPlot により提示されます。
以下に示すいずれかを選択します:
- データに直線を当てはめる (Fit a straight line through the data)。この答えを選択すると、お持ちのデータの関係を最もうまく説明する直線 y =p0+p1x の傾きと切片が求められます。ここで、y は従属変数、x は独立変数です。
このオプションを選択したら、Finish をクリックして検定を表示させます。SigmaPlot により提示されるのは、線形回帰 (Linear Regression) の実行です。詳しくは、単純線形回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、単純線形回帰の結果を解釈する をご覧ください。
- データに曲線を当てはめる (Fit a curved line through the data)。この答えを選択すると、独立変数と従属変数との間に直線関係を仮定せずに独立変数から従属変数を予測する方程式が求められます。データに曲線を当てはめるを選択した場合、使用したい曲線の種類について SigmaPlot により質問されます。詳しくは、8. 使用する曲線の種類は何ですか? をご覧ください。
幾つかの独立変数から従属変数を予測する。線形関係 y =b0+b1x1+b2x2+b3x3+ … bkxk を使用して複数の独立変数から従属変数を予測したい場合は、このオプションを選択します。ここで、 y は従属変数、x1, x2, x3…, xk は k 個の独立変数、b1, b2, b3…, bk は回帰係数です。xi の値が変動すると、それに応じて y の値も比例的に増減します。
このオプションを選択すると、独立変数を指定する方法について SigmaPlot により質問されます。詳しくは、9. 独立変数はどのように指定しますか? をご覧ください。
- 変数対の間の関連の強さを測定する (Measure the strength of association between pairs of variables)。このオプションを選択すると、従属変数と独立変数を指定せずに、ある変数の値が別の変数の値をどれだけうまく予測するかが求められます (例えば、ある変数が増加または減少したとき、別の変数が増加または減少する尤度)。
このオプションを選択したら、Finish をクリックします。SigmaPlot によりピアソンの積率相関 (Pearson Product Moment Correlation) を計算するよう提示されます。
8. 使用する曲線の種類は何ですか?
(What kind of curve do you want to use?)
曲線を使用してある変数の予測をそれ以外の単一または複数の変数から試みる場合は、使用する曲線の種類について質問されます。
以下に示すいずれかを選択します:
- 独立変数が1つの多項式曲線 (A polynomial curve with one independent variable)。独立変数 x から従属変数 y を、次式であらわされる k 次の多項式曲線を使用して予測したい場合は、このオプションを選択します。
y =b0+b1x+b2x2+ … bkxk ここで、b0, b1, b2, …, bk は回帰係数です。
このオプションを選択したら、Finish をクリックします。SigmaPlot により多項式回帰 (Polynomial Regression) を実行するよう提示されます。詳しくは、多項式回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、インクリメント型多項式回帰の結果を解釈する をご覧ください。また、Order Only の Polynomial Results の解釈に関する情報を表示させることも可能です。詳しくは、次数のみの多項式回帰の結果を解釈する をご覧ください。
- 一般的な非線形方程式 (A general nonlinear equation)。お持ちのデータを非線形関数で説明したい場合は、このオプションを選択します。よく使われる非線形関数には、上昇および下降する指数および対数曲線、ロジスティックシグモイド曲線、ある極大値や極小値に近づく双曲線があります。
このオプションを選択したら Finish をクリックします。SigmaPlot により非線形回帰 (Nonlinear Regression) の使用が提示されます。
非線形回帰 (Nonlinear Regression) では、ダイアログボックスを使って最大 10 までの独立変数を使用できる一般的な任意の非線形方程式を指定したら、反復計算の最小二乗アルゴリズムを使用して、その回帰モデルのパラメータが求められます。
9. 独立変数はどのように指定しますか?
(How do you want to specify the independent variables?)
複数の独立変数を使って従属変数を予測する場合、その独立変数の選択には2つの方法があります。従属変数と独立変数は、この回帰プロシージャの実行時にワークシートの列として選択されています。
以下のいずれかを選択します:
- 選択したすべての独立変数を方程式に含める (Include all selected independent variables in the equation)。単一の方程式を計算する際、そこで使用する独立変数が従属変数の予測に有意に寄与するか否かにかかわらず、選択したすべての独立変数を使用する場合は、このオプションを選択します。
このオプションを選択したら、Finish をクリックします。SigmaPlot により多重線形回帰 (Multiple Linear Regression) を実行するよう提示されます。詳しくは、多重線形回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、多重線形回帰の結果を解釈する をご覧ください。
- 方程式に含める最良 (“best”) の変数を SigmaPlot に選択させる (Let SigmaPlot select the “best” variables to include in the equation)。選択した独立変数の候補を SigmaPlot で篩い分けし、従属変数の予測に有意に寄与するものだけを含めたい場合は、このオプションを選択します。これを選択したら、独立変数の選択方法について質問されます。詳しくは、10. 独立変数を SigmaPlot で選ぶ方法はどうしますか? をご覧ください。
10. 独立変数を SigmaPlot で選ぶ方法はどうしますか?
(How do you want SigmaPlot to select the independent variable?)
ある変数の値を別の変数から予測する際、その回帰方程式の値の予測に寄与する変数の候補を SigmaPlot で篩い分け (screen) したい場合、選択できる方法は3種類あります。
- 独立変数を逐次的に方程式に加えてゆく (Sequentially add new independent variables to the equation)。このオプションを選択すると、独立変数の無い状態から、変数を徐々に加えてゆき、従属変数の予測能力がそれ以上改善しなくなるところで方程式の独立変数を選択します。変数はモデルに寄与する予測能力の大きさの順に追加されます。
前進型の段階的回帰 (Forward stepwise regression) で生成されるモデルの予測能力は、その回帰方程式の残差平方和 (residual sum of squares) を小さくする能力によって測定されます。
このオプションを選択したら、Finish をクリックします。SigmaPlot によって、前進型の段階的回帰 (Forward Stepwise Regression) が提示されます。詳しくは、段階的線形回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、段階的回帰の結果を解釈する をご覧ください。
- 独立変数を逐次的に方程式から除外する (Sequentially remove independent variables from the equation)。このオプションを選択すると、まずはじめに全ての独立変数を方程式に含め、それらを1つずつ除外していくことで方程式の独立変数を選択します。まずはじめに、従属変数の予測の寄与が最も小さい変数が方程式から除外されます。この消去プロセスは、従属変数を予測するモデルの能力が指定した水準を下回るまで続けられます。
後退型の段階的回帰 (backwards stepwise regression) で生成されるモデルの予測能力は、その回帰方程式の残差平方和 (residual sum of squares) を小さくする能力によって測定されます。
このオプションを選択したら、Finish をクリックします。SigmPlot により後退型の段階的回帰 (Backward Stepwise Regression) が提示されます。詳しくは、段階的線形回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、段階的回帰の結果を解釈する をご覧ください。
- 独立変数の全ての組み合わせの可能性を考慮してその中から最良のサブセットを選択する (Consider all possible combinations of the independent variable and select the best subset)。回帰モデルの全ての可能な組合せを SigmaPlot で評価し、従属変数を予測する最良の “best” モデルを取り出したい場合は、このオプションを選択します。
このオプションを選択したら、Finish をクリックします。SigmaPlot によりベストサブセット回帰 (Best Subset Regression) が提示されます。詳しくは、ベストサブセット回帰 をご覧ください。このプロシージャで得られた結果に関する説明を表示させることも可能です。詳しくは、ベストサブセット回帰の結果を解釈する をご覧ください。
SigmaPlot は、Best Subsets Regression Options ダイアログボックスで指定した条件を使用して、従属変数を予測する最良 “best” の独立変数の集合を選択します。
11. 研究は後向きですか、それとも、前向きですか?
(Is your study retrospective or prospective?)
処理 (治療) と事象 (病気の発生) との間の関係の強度を測定する際、処理効果が事象の観測後に決定される場合と、処理群と対照群が事象の観測前に抽出されている場合があります。
以下のいずれかを選択します:
- 処理効果が事象の観測後に決定される (A treatment effect is to be determined after an event has been observed)。処理の効果が事象の観測後に決定される後向きの研究 (retrospective study) には、このオプションを選択します。詳しくは、オッズ比検定 をご覧ください。
- 処理群と対照群が事象の観測前に抽出されている (A treatment and a control group have been sampled before an event is observed)。処理群と対象群が事象の観測前に抽出されている前向きの研究 (prospective study) には、このオプションを選択します。詳しくは、相対危険度検定 をご覧ください。