バージョン 13 の新機能
統計解析
時系列解析における ARCH & GARCH モデル
時系列解析の改良点
- 最尤法の各種アルゴリズム (BHHH, BFGS, Newton‐Raphson) を用いた ARCH および GARCH モデルのフィッティング。収束基準に各種オプションを選択可能。
- パラメータ推定を用いた誤差分散の予測
- Jarque‐Bera 法による誤差の正規性検定
- ARCH 効果を検討する McLeod-Li 検定と Lagrange Multiplier 検定
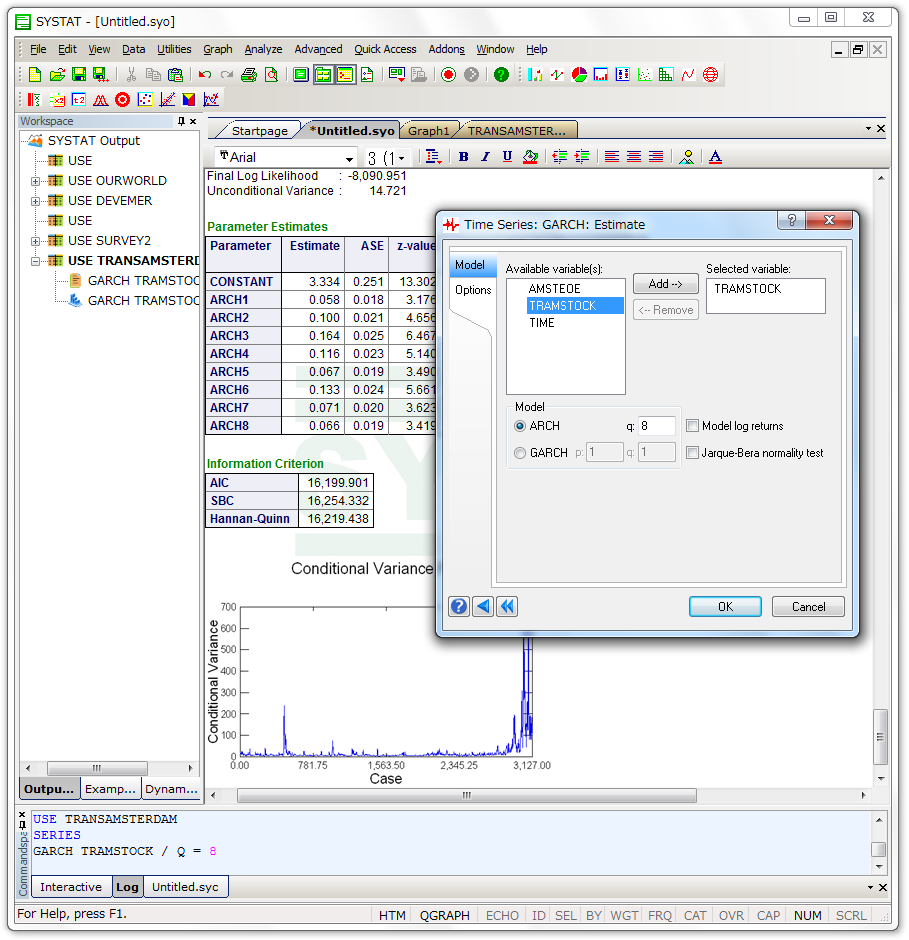
従来の時系列および計量経済学モデルでは、時系列の条件付き分散は常に不変であると考えられていましたが、これは必ずしもそうなるわけではありません。ARCH および GARCH モデルは過去の変動を使用して時系列の分散をモデル化します。
| 金融データは乱高下することがしばしばありますが、ARCH および GARCH モデルを使えばこれらをうまく説明し、理解することができます。 |
ベストサブセット回帰
SYSTAT の回帰分析ツール集に以下の機能が追加されました:
- 複数の予測変数(データセットに含まれる1から総数までの範囲)の中から最適なモデルを発見(予測変数を選択)。
- 最適モデルの判断基準に R二乗、調整済み R二乗、Mallows の Cp、MSE、AIC、AICC、BIC を利用し、
- 上記基準で絞り込まれた最適モデルのいずれかをユーザーが選択し、データセット(学習セットと同一又は異なるセット)に完全な回帰分析を実行できます。
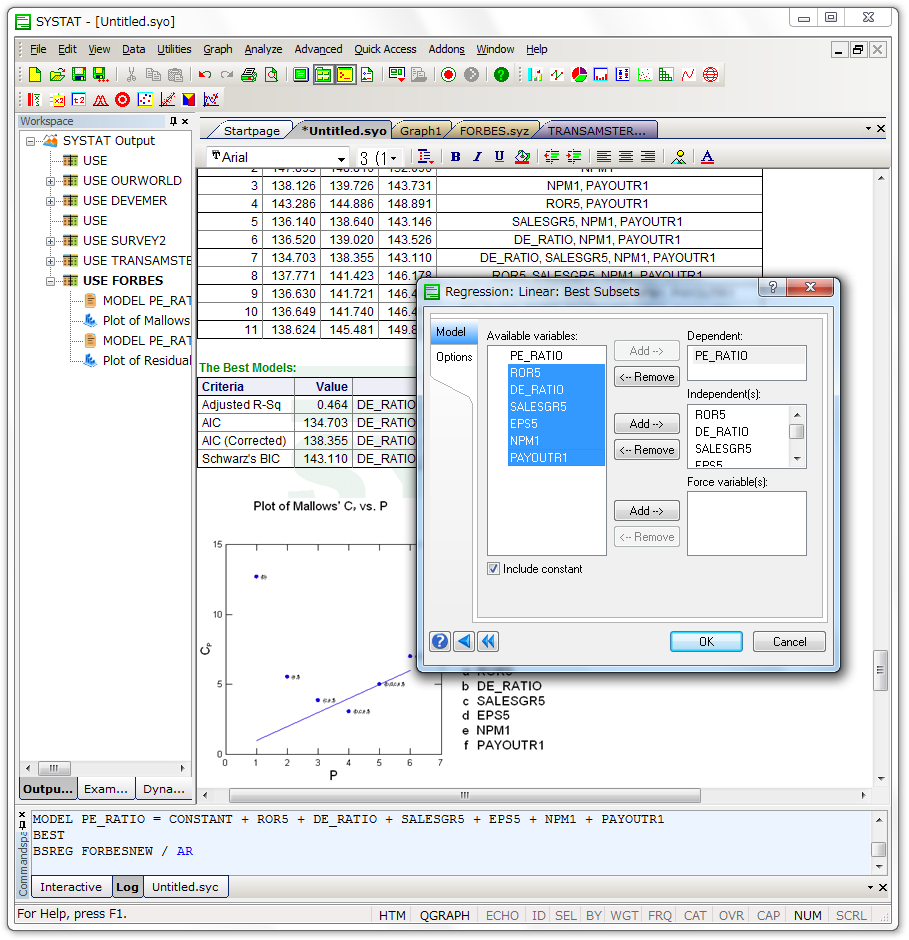
試行セットから少数の予測変数を選択することができます。重回帰モデルで予測力をむやみに犠牲にすることなく、予測実験の節約ができます。
| どの予測変数が最も有効であるかが必ずしも明白ではない経済学、生態学、環境科学などの分野での活用に効力を発揮します。 |
確証的因子分析 (CFA)
因子分析の一部として、確証的因子分析 (CFA) 機能が新たに追加されました:
- CFA モデルのパラメータ推定に最大尤度、一般化最小二乗、加重最小二乗法を選択可能。
- 以下に示す各種適合度指標を用いてデータに対する仮説因子モデルの適合度を検討できます。適合度指標 (GFI)、二乗平均平方根残差 (RMR)、倹約性適合度指標 (PGFI)、AIC、BIC、マクドナルドの確実性尺度、非標準適合度指標 (NNFI)。
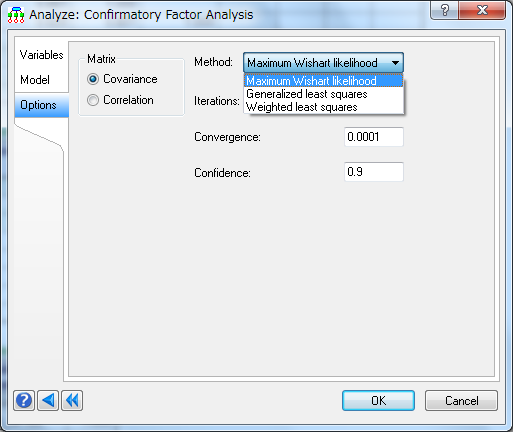
確証的因子分析 (CFA) は、与えられたデータの仮説因子構造の妥当性を調べます。
CFA は、性格検査、知能検査、世論調査などの検定の開発や、理論の検証に利用されます。
| 社会科学者、行動科学者、教育科学者および生物学、経済学、マーケティング、医学研究などの分野で利用されます。 |
基本統計の環境変数
STSTAT の基本統計モジュールに環境変数が新たに加わりました。
- 任意のセッション、任意のデータファイル、任意の変数ごとに算出された各種統計量を格納する変数です。
環境変数をその後の変換命令で直接利用することで、算出された統計量をもとに処理を進めることができます。
| 基本統計はメモリに記憶され、与えられたセッションの任意の時点で容易に呼び出し、印刷や後続する処理に利用することができます。 |
仮説検定のアップデート
仮説検定では以下の機能が強化されました:
- 多変量データの平均ベクトルについての検定:
- ホテリングの1標本 T2 検定。多変量データの平均ベクトルが既知のベクトルと等しいかどうかを検定。
- ホテリングの2標本 T2 検定。2つの多変量データの平均ベクトルが等しいかどうか検定。
- 2標本 z-検定、2標本 t-検定、2分散の検定において、2つの標本データが異なる列に配置されている入力データを選択するオプション。現行のインデックス型配置に加え、このオプションを選択できます。
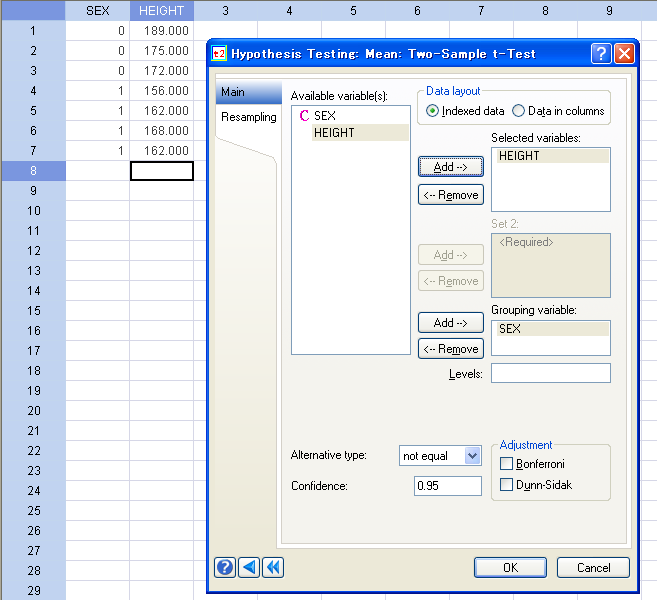
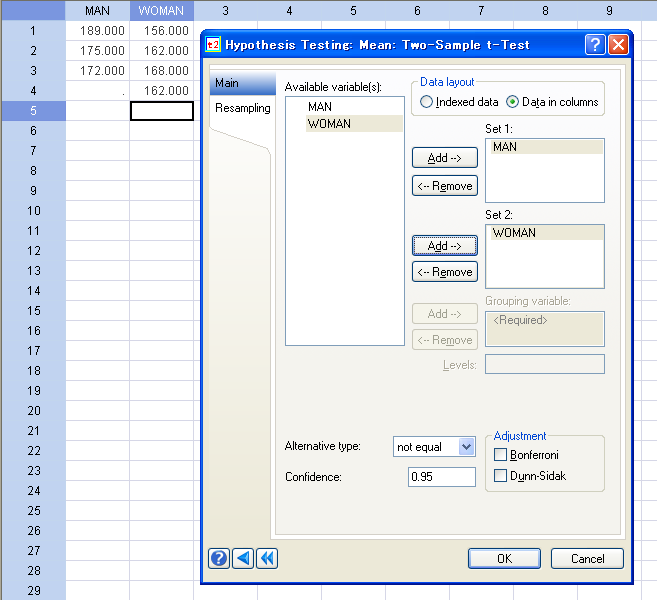
多変量正規性を仮定する平均ベクトル (1標本又は2標本) についての検定を簡単に直接実行できます。2標本検定についてのデータ入力が一層便利になりました。
| 多変量検定をより手軽に実行できます。SYSTAT で2標本検定を実行する場合、データを編集しなおす必要はありません。 |
新しい基本統計
SYSTAT に以下の基本統計が新たに加わりました:
- トリム平均のための標準誤差と信頼区間
- ウィンザライズド平均とその標準誤差と信頼区間
- 標本のモード
- 四分位範囲
いずれもロバストな統計です。トリム(刈り込み)平均は、極端な値を除外して計算を行います。ウィンザライズド平均は、極端な値を除外し、最も近くにある有効な値に置き換えて計算処理を実行します。
| 外れ値によって算術平均や標準偏差などの標準的な統計では正確さを欠いてしまうような場合に役立つ統計機能です。 |
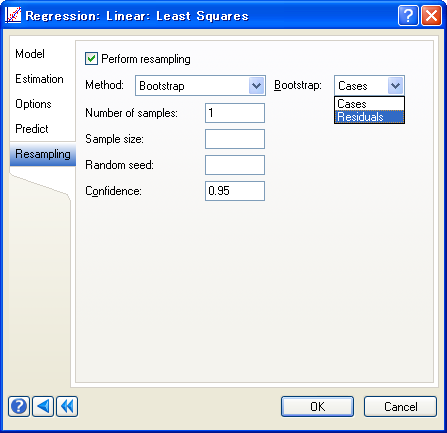
ブートストラップ分析のアップデート
- 仮説検定機能にブートストラップベースの p-値が新たに加わりました。平均 (1標本 z-検定、1標本 t-検定、2標本 z-検定、2標本 t-検定、対応のある t-検定、ポワソン)、および分散 (1群、2群および複数群) についての検定すべてで利用することができます。
- 最小二乗回帰でブートストラップを実行する場合、残差を選択できるようになりました。回帰係数、バイアス、標準誤差および信頼区間のブートストラップ推定は、これらをもとに計算されます。
分布仮説がなくてもブートストラップを用いて単変量検定を実行できます。
| ブートストラップは現代のデータ解析に欠かすことのできない手法です。その利用は今日ますます拡大しています。 |
新しいノンパラメトリック検定
ノンパラメトリック検定に以下の機能が追加されました:
- 順序性のあるデータの違いを検討する Jonckheere‐Terpstra 検定
- 対照群と処置群を検討する Fligner‐Wolfe 検定
- 以下に示す2つの一対比較検定
- Dwass‐Steel‐Critchlow‐Fligner
- Conover‐Inman
処置群に順序性がある場合は、Jonckheere‐Terpstra 検定が Kruskal‐Wallis 検定よりも適しています。Fligner‐Wolfe 検定は、新しい処置群と対照処置群(基準処置)の効果を比較するのに役立ちます。Dwass‐Steel‐ Critchlow‐Flinger と Conover‐Inman は多重比較検定です。
| 毒物学など、治療法を構築する医学・生物学分野で役立つ検定です。 |
多項式回帰
SYSTAT ではひとつの独立変数につき最大で8次の多項式回帰を利用できます:
- 自然多項式形式と直交多項式形式
- 全モデルについての適合度統計 (R二乗および調整済み R二乗) および ANOVA と p値。ユーザーの指定した次数ではじまり、最終的に線形 (次数 =1) で終了する。
- Quick Graphs として計算結果に付随する信頼区間と予測区間をあらわすプロットと、残差対予測値のプロットが出力されます。
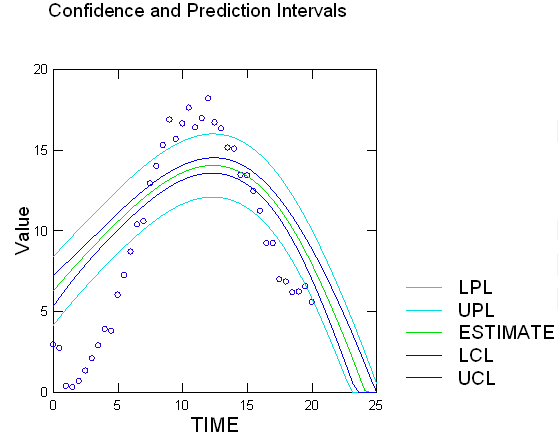
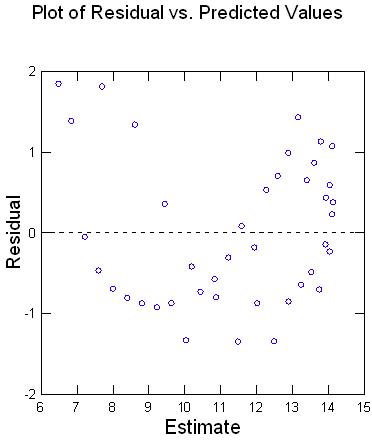
多項式回帰は、従属変数と独立変数の関係が曲線を示す場合に利用されます。
| 単純な線形式にくらべてより役立つ予測式を開発するのに役立ちます。 |
分散分析のアップデート
分散分析に新しく追加された機能:
- 中央値に基づいて分散の均一性を検定する Levene の検定
- 解析に必要な要因だけを分類する SUBCAT コマンド
中央値に基づく Levene の検定は、統計的検出力を保持しつつ様々なタイプの非正規データに対してロバスト性を発揮します。SUBCAT コマンドは特定の解析を実行するときだけ作用します。
| あるデータについて、その分布が何に基づくかあらかじめ分かっている場合、中央値も基にする Levene の検定を使えば、それとは別の分布を選ぶことになるかも知れません。SABCAT コマンドは後続の解析に影響を及ぼしません。 |
クロス集計のアップデート
クロス集計の一部として以下に示す機能が追加されました:
- 相対危険度:相対危険度は 2×2 分割表において、行または列に定義された2群の結果が正(ポジティブ)であるケースの比率です。相対危険度は2値変数の関連性を評価するのに広く利用されます。
- モード:一元配置表(度数分布)のはじめの N 分類のみをリストとして表示させるオプションが提供されます。XTAB 内の PLENGTH コマンドに MODE=N オプションを追加することでこれを実行できます。
- 結果の保存:
- Multiway: Standardize で指定されたすべての列を保存
- 保存された結果ファイルの列に対応する入力変数の値ラベル
- 分割表タイプにもとづいて適切に分類され、統計量が再編成されたアウトプット。
相対危険度は、ある特性をもたらす2群間の相対的な危険度を評価するものです。モードオプションを使えば、度数の多いカテゴリに焦点を絞り込むことができます。
| 相対危険度は開発中の薬品の効果を評価する臨床試験で役に立ちます。 |
クラスター解析のアップデート
クラスター解析において、保存された結果を含むデータファイルに値ラベルがある場合、データファイルを入力してもそれが保持されます。
値ラベルは、定義されたカテゴリに関する役立つ情報を提供します。
| 保存されたデータと同じ値ラベルを手動で定義する必要がなくなります。 |
フィッティング分布のアップデート
SYSTAT 13 では、最尤法を使用して以下の分布パラメータを評価できます:
- ベータ分布
- カイ二乗分布
- アーラン分布
- ガンマ分布
- ゴンペルツ分布
- ガンベル分布
- ロジスティック分布
- 対数ロジスティック分布
- 負の二項分布
- ワイブル分布
- Zipf 分布
最尤法は、従来使用されていたモーメント法に比べて良い結果をもたらします。
| この機能により、前バージョンで利用していた手法よりも良い結果がもたらされます。 |
最小二乗回帰のアップデート
パラメータ推定と共に標準誤差と信頼区間を保存する機能が最小二乗回帰に追加されました。
SYSTAT データファイルに標準誤差と信頼区間が保存されます。
| 保存された統計データは必要があれば別の計算に利用できます。 |
ロジスティック回帰のアップデート
ロジスティック回帰の機能向上により、2値モデル、多項式モデル、条件付きモデル、離散選択モデルを従来よりも直感的な方法で解析できるようになります:
- 2値、多項式、条件付き、離散選択モデルそれぞれについてユーザーインターフェースとコマンドライン構造が簡素化され、操作性が向上しました。
- 2値および多項式応答モデルにおいて基準レベルを設定できるオプションを追加。
- セット毎に1つのケースと任意数のコントロールをもつ一致したサンプルのケース-コントロール研究を分析するための容易なデータ入力。
- 離散選択モデルにおける2種類のデータ配置の入力: 「Choice set」と「By choice」 。選択の特性に応じて個人の選択をモデル化。
- 生データ配置においては、変数をグループ化して名前を付けた選択集合 (choice set) を定義できます。変数は作成、編集、削除することができます。
- By choice フレームワークにおいては、あらかじめ定義された選択集合 (choice set) を分析のデータに利用できます
ユーザーインターフェースが分かりやすくなり、データ入力がさらにフレキシブルになりました。
| 金融モデリングやマーケットリサーチの分野で今日ますますその利用が広がっているロジスティック回帰機能が使いやすく便利になりました。 |
混合モデルのアップデート
混合モデルの計算速度が前バージョンにくらべて著しく向上しました。
大規模データの分析で時間を節約できます。
| 大規模データの分析で時間を節約できます。 |
グラフィックス
RGB 値を色表現に使用
赤・緑・青の各色成分の値によって色彩を指定できるようになりました。グラフ要素、軸、枠の色指定に利用できます。
あらかじめ用意された色集合のみに使用する色を制限する必要はありません。
| RGB の値を設定するだけで任意の色を使用できます。 |
ダイアログボックスによるサーフェス・グラデーションの色指定
ダイアログボックスからグラデーションのスタイルを指定することができるようになりました。関連するグラフタイプのダイアログボックスに用意された Surface および Line style タブで利用することができます。
グラデーションのスタイルを容易に指定することができます。コマンドを憶える必要はありません。
| ダイアログボックスのインターフェースを通じて簡単にグラデーションのスタイルを設定できます。 |
ドット(サマリー)チャートにおけるラベルドット
ドット (サマリー) チャートのドットにラベルを付けることのできるオプションが新たに追加されました。
ドットに対応する値を簡単に読み取ることができます。
| ドットチャートの機能向上。 |
組み込み色
SYSTAT の組み込み色が前バージョンの12色から45色に増えました。
定義済みの色数の選択肢が増加しました。
| 利用できる色の選択肢が広がりました。 |
重ね合わせグラフ、円グラフ、積み上げグラフのための色
重ね合わせグラフ、円グラフ、積み上げ棒グラフにおいて、隣接する要素間のコントラストが高くなるような色指定が可能になりました。
| 隣接するグラフ要素を容易に識別することができます。 |
グループ化変数を考慮する積み上げ棒グラフ
グループ化された棒グラフの場合、棒を積み上げることができるようになりました。積み上げられたグラフは、グループ毎に描画され、すべてのグラフは同一の枠内に配置されます。
グループ化変数がある場合には、オプションを選択するだけで積み上げ棒グラフを直接描画できます。
| グループ別に処理する必要はありません。 |
プロットに表示されるボーダーの個別指定
ボーダーの表示法を個別にすることができるようになりました。
二次元プロットにおける任意のボーダーについて、それを非表示にしたり、2つのボーダーにそれぞれ異なる表示法を指定することができます。
| グラフ表示がフレキシブルになりました。 |
円グラフの複数スライス表示
円グラフから複数のスライスを切り出すことができるようになりました。スライスとして切り出す数を指定することも、すべてのスライスを切り出すこともできます。
| スライスを一つしか切り出すことができないという制限は解除されました。 |
数値ケースに基づくラベル
プロット、多変量表示およびマップ内のラベル設定で数値変数を指定できるようになりました。グラフ要素にラベルを付ける際、前バージョンまでは文字列変数のみしか利用することができませんでした。
ラベルに文字列変数しか利用できないという制限が解除されました。
| 数値ケースに基づくラベルを指定することができます。 |
GUI (GRAPHICAL USER INTERFACE)
自動非表示スペース
画面右上の自動非表示ボタンをクリックすることで、ワークスペースとコマンドスペースを非表示にすることができます。
→
Viewspace で利用できる作業空間をこれによって広げることができます。
| 1画面により多くの出力結果やデータ情報、より大きなグラフを表示させることができます。 |
選択トークン
新しいタイプのトークン用ダイアログボックスを使用して選択トークンを指定することができるようになりました。ダイアログボックスでは、2~10の選択肢を設定することができます。いずれの選択肢も SYSTAT のコマンドスクリプトとリンクさせることができます。これにより、ユーザーの選択によって対応するスクリプトを実行させることができます。ひとつの SYSTAT コマンドスクリプトに複数のスクリプト (最大10) を組み込み、与えられた解析について様々なシナリオを用意してスクリプトを対応させることも可能です。ユーザーの選択により任意のセットを実行することができます。
対話型の入力を含む複雑なコマンドスクリプトを作成できるので、実行時にふさわしい適切な選択肢を用意しておくことによって様々な可能性を実現させることができます。
| SYSTAT コマンド言語はこの機能の追加によって一段とパワフルなものになります。 |
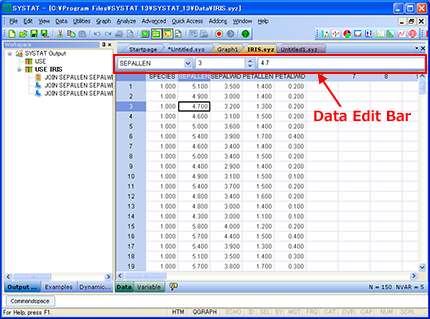
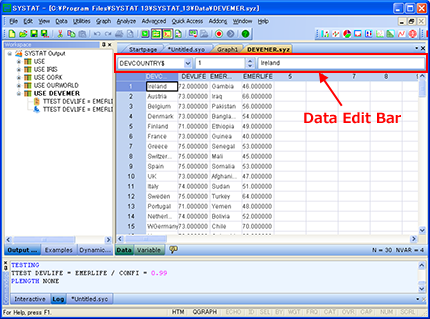
Data Edit Bar の実装
Data/Variable Editor に Data Edit Bar というツールバーが新たに組み込まれました。
Data Editor 内のセルを自由に行き来したり、データを表示・編集することができます。
| データのナビゲーションと編集がより便利になりました。 |
データファイル情報
Data/Variables タブの隣にある File Comments ボタンをクリックして、データファイルに関するコメントを入力・編集することができます。既に入力されたデータファイルのコメントを確認したい場合は、ボタンにマウスを置くだけでその内容が表示されます。
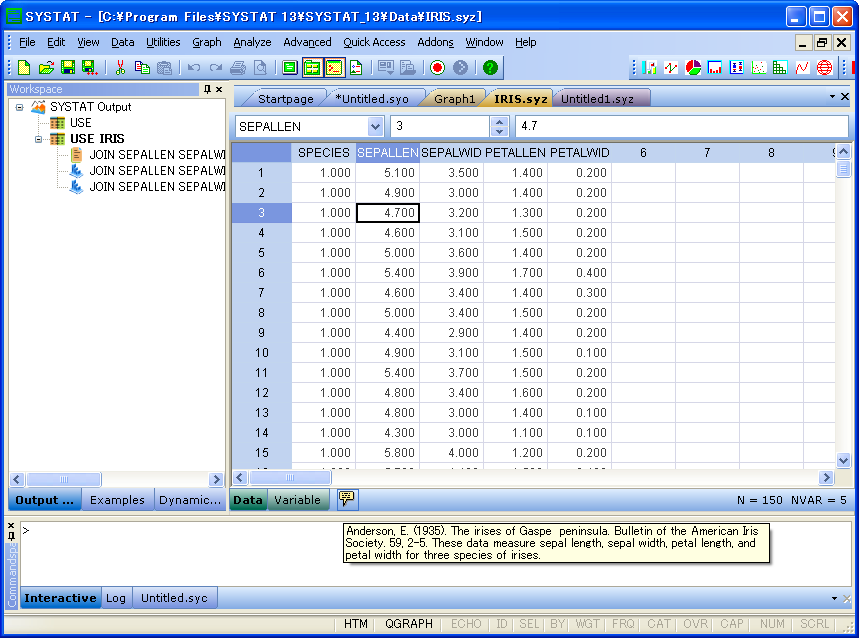
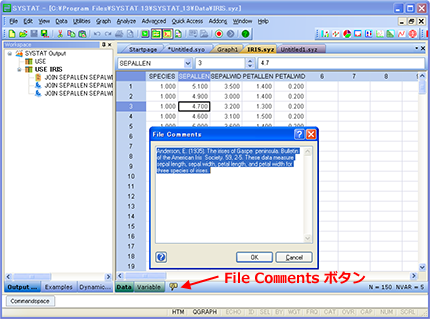
既にファイルコメントがある場合はその内容を即座に確認することができます。コメントの編集はマウスをクリックするだけで実行できます。
| データファイルのコメントに簡単にアクセスできます。 |
デフォルトのコマンドファイル保存形式
SYSTAT の前バージョンではコマンドファイルを Unicode 形式で、それ以前のバージョンでは ANSI 形式で保存していました。新しいバージョンではこの保存形式を選択することができるようになりました。Edit: Options ダイアログを使ってデフォルトで保存されるコマンドファイルの形式を設定することも可能です。
目的の形式をマウスで選択するだけで、コマンドファイルをいずれかの形式で保存することができます。
| コマンドファイルをユーザーの好きな形式で保存することができます。 |
データのドラッグ&ドロップ
コンテンツのドラッグをサポートしている外部エディタから、SYSTAT の Data Editor にテキストをドラッグ&ドロップすることができるようになりました。SYSTAT の Commandspace に入力されたテキストをドラッグ&ドロップすることも可能です。
データを手動でコピーする必要はありません。ウェブサイトやリッチテキストエディタから直接データを渡すことができます。
| ファイル形式にかかわらずデータをインポートすることができます。 |
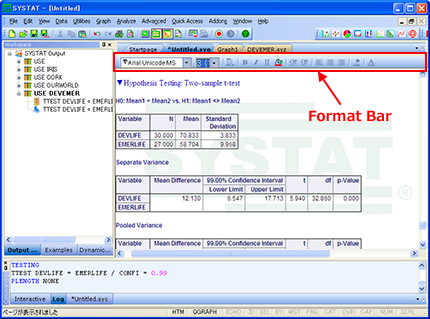
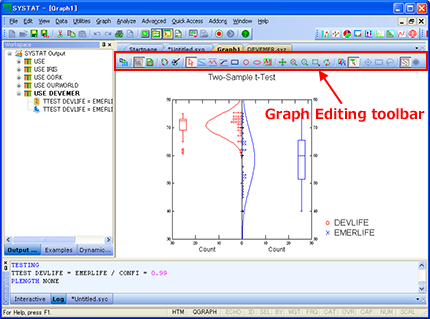
埋め込み型ツールバー
Format Bar、Data Edit Bar、Graph Editing toolbar がそれぞれ Output Editor、Data Editor、Graph Editor タブに埋め込まれるようになりました。
ツールバーは、Viewspace の特定タブと関連のあるもののみが表示されます。
| ツールバー領域に余計なツールバーを配置する必要がないため、SYSTAT のウィンドウには必要な情報だけが表示されるようになります。 |
旧形式のコマンドファイルの活用
- 一行目に VERSION コマンドを挿入すればレガシーなコマンドファイルを直接開いて実行することができます。構文は VERISON n で、n は 11 または 12 となります。
- これとは別に、Translate Legacy Commands ダイアログボックスと SYSTAT Command Translator を使って変換したいコマンドファイルのバージョンを 11 または 12 に指定することも可能です。
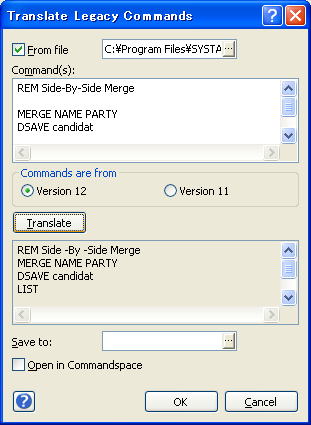
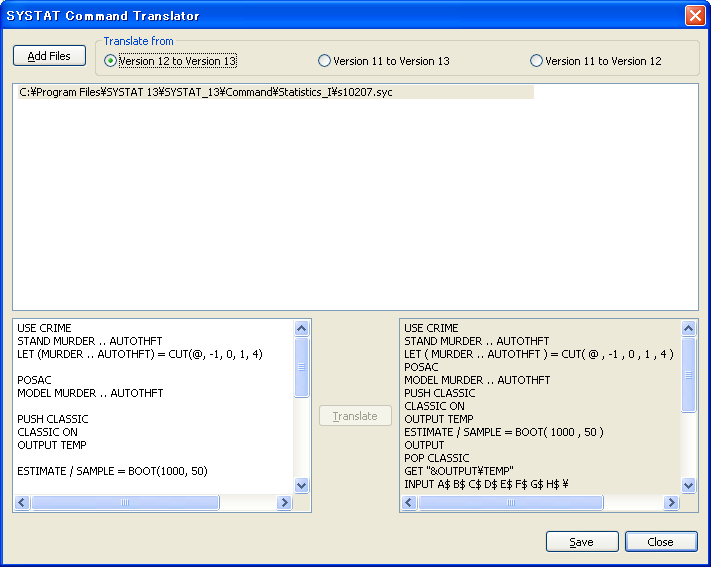
レガシーなコマンドファイルを実行することができます。変換しなおして個別に保存する必要はありません。
| 変換されたコマンドファイルを個別に保存しなくてもいいので、それだけ領域を節約できます。ほとんどの場合、新たに構文を理解する必要はありません。 |
View Toolbars
SYSTAT のツールバーを View メニューから呼び出すことができるようになりました。呼び出されたツールバーに対応するメニュー項目にはチェックマークが付きます。
ツールバーをとても手軽に表示させることができます。
| Customize ダイアログボックスを開かなくてもツールバーを呼び出すことができます。 |
Windows XP スタイルのフリッカーフリーグリッド
- SYSTAT の Data/Variable Editor グリッドが Windows Desktop で適用される Windows XP テーマに対応しました。
- グリッドコントロールを含む Data: Transform: If Then Let や Data: Select Cases などのダイアログボックス、Color、Fill、Symbol、Label、Surface、Line Style などのグラフに関連するダイアログボックスのタブは共通の外観と操作性をもつようになりました。
- グリッドはすべてフリッカフリーです。
SYSTAT のウィンドウは Windows のインターフェースと完全に調和します。Data/Variable Editor で画面をスクロールしても目に負荷がかかりません。
| これにより使い易さはもちろん、外観もスタイリッシュになりました。 |
文字列データにおける前後空白の削除
Data Editor で入力・編集する文字列データの前後にあるスペースを自動的に削除するかどうかを指定できるようになりました。Edit: Options ダイアログの Data タブでこのオプションを選択できます。
文字列の前後にあるスペースをそのままにしておくか、削除するかのいずれかを選択できます。手動で空白を挿入したり削除する必要はありません。
| 文字列の前後にスペースが含まれるとそれらは個別のグループとして処理されます。 |
自動補完コマンド
- Commandspace の Interactive タブまたはバッチ (Untitled) タブにテキストを入力すると、コマンドの引数、オプション、オプション値が自動的に補完されます。引数となるのはファイル名、変数名、組み込み関数名または特定のキーワードです。
- スペースを含むファイル名またはパス名を選択すると、それらは自動的に引用符で囲まれます。関数名の後には自動的に括弧が付けられます。
コマンドのキーワードやファイル名、変数名を正確に覚えておく必要はありません。
| コマンドやスクリプトを非常に簡単に構築できます。 |
コマンドの色分け
- コマンドキーワードの色分けはデフォルトを指定するオプションで設定できるようになりました。Edit: Options ダイアログの General タブを使ってこれを指定できます。
- 変数名は黒、コマンド引数は紫、オプション値は緑にそれぞれ色分けされます。
使用するコマンドファイルが大きい場合は、このオプションを無効にしておくことで処理を高速にすることができます。このオプションを無効にしておけば、コマンドやコマンドファイルに変更を加える際、アンドゥやリドゥを使用することができます。変数名とオプション値を識別しやすくなります。

| コマンドファイルを高速に開けます。様々な種類のコマンドキーワードを簡単に見分けられるので、それだけ読みやすくなります。 |
ダイアログボックスのタブ分類
SYSTAT のダイアログボックスのタブが縦方向の配置になりました。
これまでより多くのタブにマウスをワンクリックするだけでアクセスすることができるようになります。
| ダイアログボックスの占める画面領域が縦方向に狭まることで、モニタの縦横比に近くなります。 |
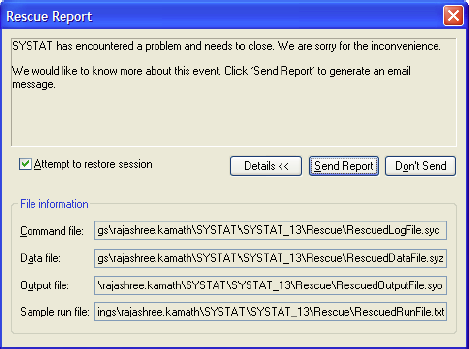
復旧レポート
- 強制終了したセッションの復旧を試みる機能が追加されました。
- Send Report をクリックすると、復旧できたファイルが自動的に Email メッセージに添付されます。
復旧ファイルを特定の場所へ手動で保存したり、それを開いて添付する必要はありません。
| 強制終了のレポートをダイレクトに送信できるようになります。 |
ショートカットキー
以下のショートカットキーがデフォルトで追加されました:
- Ctrl + Q : SYSTAT を終了する
- Alt + backspace : アンドゥ
- Ctrl + Alt + Enter : Variable Properties を開く
- Ctrl + K : Workspace を表示する
ショートカットキーを使って上記の操作を簡単に実行することができます。
ステータスバー
ステータスバーに以下の改良がなされました:
- ステータスバーの PAGE をクリックしてページ幅を Narrow、Wide、None に切り替えることができるようになりました。
- ステータスバーから Insert、Caps Lock、Num Lock、Scroll Lock などキーボードの状態を切り替えることができるようになりました。

ページ幅の設定、キーボードの設定をワンクリックで変更できます。
テーマ
SYSTAT のテーマに以下の機能が追加されました:
- Download Themes 機能にダイアログボックスのインターフェースが追加されました。インストールしたいテーマをダイアログボックスから選択することができます。
- テーマファイルにバージョンが付き、SYSTAT のサーバーに新しいバージョンのテーマがアップされたらいつでもそれを更新することができます。
- テーマを適用する際は、現在使用中のテーマを保存するかどうかのダイアログが表示されます。
新しいテーマに関する情報を確認した後、ダウンロードしたいテーマだけを選択することができます。GUI のカスタマイズで思わぬ失敗を防ぐことができます。
| フレキシビリティと安全性が向上しました。 |
データファイルを閉じる手段
Data Editor の右クリックメニューまたは CLOSE コマンドを使用して、データファイルを閉じることができるようになりました。CLOSE filename を実行すると指定したファイルを閉じることができます。CLOSE / ALL を実行するとアクティブなデータファイルを除くすべてのファイルを閉じることができます。
現在のセッションで不要なデータファイルを閉じることができます。コマンドファイルを使用してデータファイルを閉じることもできます。
| セッション中に不要なデータファイルをメモリ内に開かないで済みます。アクティブなデータファイルを上書きすることもできます。 |
デフォルトの変数形式
Data Editor で新規に追加する数値変数のデフォルト形式を設定できるようになりました。
数値変数の形式は、数値の出力形式とは別に設定できます。
| ユーザーによるデフォルトの変数形式を制御できます。 |
View モードでデータファイルを保存
データファイルを View モードで保存することができるようになりました。保存したい「View モード」のタブを選択し、Standard ツールバーの Save ボタンをクリックするか、File > Save をクリックするだけです。
データファイルを保存する前にアクティブにする必要はありません。
ビジネスオブジェクトのインポート
データソースに「Business Objects Universe」を(ODBC や Excel など他のデータソースを選択するのと同様に)利用できるようになりました。Business Objects はデータウェアハウスの構築に必要な定義済みレポート、アドホックなレポート作成、ダッシュボード、抽出、変換、オペレーションのロードをサポートするビジネスインテリジェンス・プラットフォームの組織です。「Business Objects Universe」は、ビジネスエンドユーザーとデータベースモデルの複雑な基盤の間をとりもつ「セマンティックレイヤ」です。エンドユーザーはユニバースを実行することで、権限を与えられたすべてのデータベースにアクセスすることができます。この機能を使えば、Business Objects プラットフォームにログインして、クエリを実行するユニバースを選択したり、クエリを構築したり、得られたデータを SYSTAT 内で処理することができるようになります。
サードパーティ製品を使用しなくても、Business Objects 形式の大規模なデータセットを直接インポートし、解析することができます。
| 新しいデータインポート機能の追加です。 |
Data/Variable エディタのコピー・ペースト機能
セルのいずれか一つをコピーして、列にペーストできるようになりました。
同一のデータを続けて入力する場合、それらをひとつひとつ手動で入力しなくて済みます。
複数のデータファイルを開く機能
SYSTAT の従来のバージョンでは、未修整のデータファイルを複数取り扱う場合、アウトプットの並び順はインプットデータファイル毎になるようグローバルオプションで定められていました。新しいバージョンでは、この2つのオプションが切り離され、デフォルトでは、複数の未修整データファイルを開いてもそのアウトプットは処理を行った順に表示されるようになりました。従来までの単一のアクティブデータファイルによる作業を続けたい場合は、SYSTAT のグローバルオプションで他のデータファイルを開く際にアクティブデータファイルを閉じる (close the active data file when another is opened) を選択できます。この設定とは別に、アウトプットを処理を行った順にするか、インプットデータ毎に分けて並べるよう設定こともできます (Organize output based on input data file)。
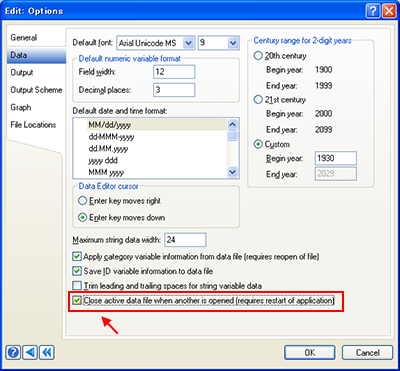
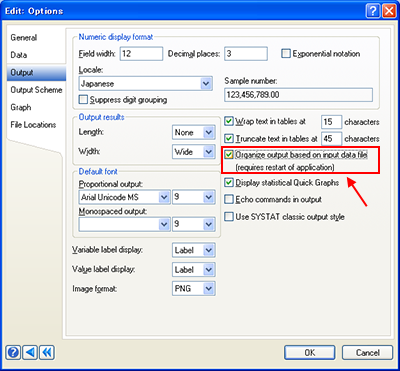
ユーザーはデータファイルを複数開き、それらを編集することができます。
別のデータファイルを開く前に既にあるデータファイルを保存する必要はありません。
一回のセッションで、複数のファイルのいずれか一つをアクティブにして、処理を続けることができます。
一回のセッションで複数のデータファイルをに開いても、アウトプットを処理を行った順に並べることができます。
| ひとつのデータファイルでしか作業できなかった制限がこれにより解除されました。 |
変数の再コード化
SYSTAT に ELSE オプションが追加されました。与えられた値集合以外の値を、指定された値に再コード化することのできるオプションです。ある変数を別な変数に再コード化する場合は、古い変数にある再コード化されない値がすべて継承されますが、再コード化されない値を継承したくない場合にはこの ELSE オプションを使用します。
ユーザーはある特定のレベルを再コード化し、その後、特定の値または文字列に残りのレベルが再コード化されるよう指定することができます。
| 特定の値を欠損値や固定値、文字列に再コード化する場合に役立ちます。 |
セッティングの保存と回復
以下のセッティングを保存することができるようになりました:
- アクティブなデータファイル
- 値ラベルの表示形式
- 変数ラベルの表示形式
保存されたセッティングは、セッション中にいつでも元に戻すことができます。
上記セッティングをそれぞれ手動で呼び出す必要がなくなりました。
| 上記のグローバルセッティングは必要があればいつでも切り替えることができます。 |
ロケールと桁区切り
Output エディタで数字を表示させる場合、 SYSTAT で使用するロケール(地域別定義)を選択することができるようになりました。SYSTAT は Data Editor に入力された数値形式をこの設定にもとづいて判別します。デフォルトのロケールは、Windows のコントロールパネルにある地域と言語のオプションで指定されたものがシステムのデフォルトとなります。
選択したロケールの小数点と桁区切り記号を使用して数字を入力することができます。異なるロケール間でデータやアウトプットをやりとりする場合、ユーザーは受け手側のロケールに合わせてアウトプットを保存することができます。桁区切りをしないよう設定することも可能です。
| データの交換が容易になり、ロケールから独立させることができます。 |
ノードとリンクの見出し
NODE コマンドを使用して Output Organizer のノードと折り畳み型リンクの見出しを設定できるようになりました。
ノード見出しをカスタマイズしたり抑制することができます。
| アウトプットのカスタマイズ性が広がります。 |
ACTIVE コマンド
ACTIVE コマンドでビューモードのファイルをアクティブにすることができるようになりました。ディスクからファイルを開くことはありません。
コマンドラインインターフェースを通じてデータファイルをアクティブにすることができます。
| SYSTAT のコマンド言語が一層強化されました。 |
組み込み関数
パワフルな関数ライブラリを一層強化する以下の新しい組み込み関数が追加されました:
- 数学関数: ACSH, ASNH, CASE, CEIL, COLUMN, COSH, EVEN, FLOOR, NCASE, NVAR, ODD, ROUND, SINH
- 多変量: COMPLETE
- グループと間隔: BOF, BOG, EOF, EOG, NCAT
- 文字列: CHR$, CODE, ISNUM, LEN
- 日付と時間: FDAYM, FDAYW, LDAYM, LDAYW, MON
- 統計: BGCF, BGDF, BGIF, BGRN, EMCF, EMDF, EMIF, EMRN, GDCF, GDDF, GDIF, GDRN, P5CF, P5DF, P5IF, P5RN, P6CF, P6DF, P6IF, P6RN, PECF, PEDF, PEIF, PERN
新たに加わった関数を使用して高度なコマンドスクリプトを記述することができます。
| 新たに加わったこれらのコマンドにより SYSTAT のコマンド言語が一層強化されました。 |
FOCUS コマンド
Data Editor、Graph Editor、Output Editor の表示を切り替える FOCUS コマンドが新たに加わりました。コマンドスクリプトで使用すれば表示させたいページを Viewspace に表示させることができます。
コマンドラインのインターフェースを使用して Viewspace にあるタブ表示を切り替えることができるようになりました。コマンドスクリプトで連続したコマンドを実行する際、いずれかのビュアーが必要な場合にこのコマンドを利用できます。
| SYSTAT のコマンド言語はこのコマンドの追加により一層強化されました。 |
マクロ
SYSTAT のコマンドスクリプトでマクロを定義し、呼び出すことができるようになりました。マクロは DEFMACRO と ENDMACRO コマンドの間に挟まれた一連の命令文です。複数のコマンドを実行する様々な場面でマクロを利用することができます。
スクリプトの反復ブロックを回避できます。
| コマンドスクリプトがコンパクトで分かりやすいものになります。 |
PAGE NONE
PAGE NONE コマンドを使用することでページ幅を無制限に設定できるようになりました。
この設定によりテーブルの折り返しを回避することができます。
| プレゼンテーション用のアウトプットを用意する際にこの機能が役立ちます。 |
バージョン 12 で追加された機能
SYSTAT は、統計ソフトにグラフ機能を融合させたパイオニア的ソフトウェアで、Leland Wilkinson 博士によって初版がリリースされて以来 20 年間、大勢の研究者、科学者にその使いやすさが支持されています。SYSTAT 12 はこの伝統を引き継ぎ、さらなるグラフ機能の強化と、操作性、カスタマイズ性の向上を実現しました。
SYSTAT 12 では、カスタマイズが容易で、様々な革新的機能を盛り込んだ新しいユーザーインターフェースを採用しました。また統計機能も複合モデル解析、ロバスト回帰、部分最小二乗法回帰 (PLSR)、応答曲線最適化、確率分布などに新機能を追加しました。最先端の統計解析機能を利用することができます。
SYSTAT 12 は高機能ですが、統計解析の専門家だけではなく、入門者でも容易に扱えるパッケージです。解析結果は、出版品質で出力することができます。また、マニュアルは新たに 900 ページが追加され、統計解析の学習にも適しています。
統計解析の新機能
複合モデル解析では、分散成分モデル、階層的混合モデルなどの線形混合モデルの機能が強化され、標準偏差、信頼区間、仮説検定とともに固定および可変パラメータ、分散成分の推定を行うことができます。繰り返し測定、成長曲線、経度データなどの独立した不均一のデータを取り扱うことができます。
ロバスト回帰では、2つの手法が追加されました。n データポイントから h ポイントを取り出し、それらの剰余の2乗和を最小にする最小2乗トリム(LTS)法、および剰余のスケール推定子に基づいて推定するスケール法です。これにより、サンプルの重み付けおよび重み付き最小2乗推定量など、ロバストな解析が可能になりました。
部分最小2乗法回帰は、データの応答および予測変数から潜在的な要因を導き出し、予測変数に関する応答因子の回帰方程式を作り出します。SYSTAT は、もっともよく使われている2つの手法、すなわち非線形反復部分最小2乗法 (NIPALS)、簡易最小2乗法 (SIMPLS) が搭載されています。回帰係数の標準誤差は、Jackknife 法で計算されます。回帰モデルの検証には、交差検証法を使用します。
より複雑な線形モデルの分析
- 回帰分析、分散分析、GLM (一般線形モデル) といった線形モデル分析の適用範囲が大きく広がりました。相関データ (correlated data)、群データ (clustered data)、依存データ (dependent data) および異分散データ (heteroscedastic data) を取り扱うことができます。SYSTAT の混合モデル分析(Mixed Model Analysis)を使うと、分散成分モデル(variance components models)、階層型混合モデル(hierarchical mixed models)、混合回帰(mixed regression)など、様々なタイプの線形混合効果モデル(linear mixed effects models)の分析を実行できます。固定効果パラメータの推定、分散成分の推定、ランダム効果の予測、などタイプの異なる推定を実行できます。これらはいずれも、信頼区間と仮説検定が付きます。
多重線形回帰の適用範囲の拡張
- データセットが多数の予測因子からなり、ケースの数よりも多い場合は、部分最小二乗回帰 (PLS: Partial Least-Squares Regression) を使います。SYSTAT は、2つの標準アルゴリズム NIPALS と SIMPLS を提供します。推定された回帰係数の標準誤差を得るには、Jackknife プロシージャを使います。あてはめられた回帰を検定するには、2種類の交差検定プロシージャ(leave-one-out / random exclusion)のいずれかを使います。
- 標準多重線形回帰プロシージャで、あるデータセットを使って何か問題が生じた場合は、SYSTAT のロバスト回帰プロシージャ (LAD, LTS, LMS, S, M, Rank) のいずれか適したものを使用して問題を解決します。
応答曲面最適化 (RSM) では、最適な因子を計算し、その因子応答データを2次元応答曲面に当てはめます。応答の最適な組み合わせを得るために、望ましさ解析を使用します。SYSTAT では望ましさプロットのほか、最適化の方向を見つけ出すためにピーク部解析も用意しています。
プロセスの設計とパフォーマンスの改良、最適化
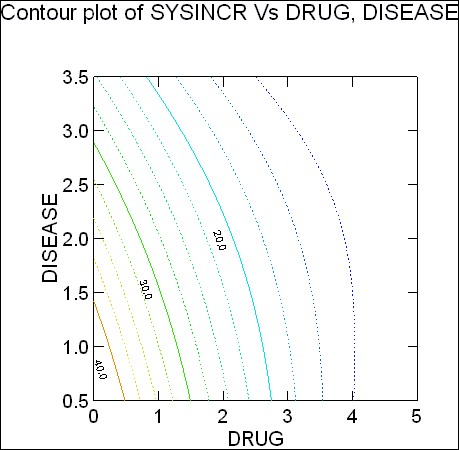
- 綿密に計画された実験から得たデータを使用する場合は、応答曲面最適化 (Response Surface Optimization) を呼び出します。これによって、入力因子のレベルとプロセス設定を最適化し、製品特性の観点から最良の結果を生み出すことができます。応答曲面パラメータの推定、分散分析と有意性検定の実行、最適因子設定の計算、等高線と望ましさプロットの作成、および、リッジ解析を行います。
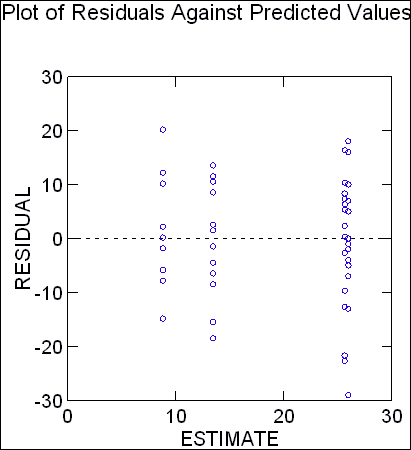
クラスター解析では、フレキシブルベータ、重み付きリンク、ユニフォームとカーネルというリンク方法を搭載しました。また階層の妥当性インデックスを新たに5つ、および、k-median 法、ツリーの高さとノードに基づいたツリー剪定が追加されています。
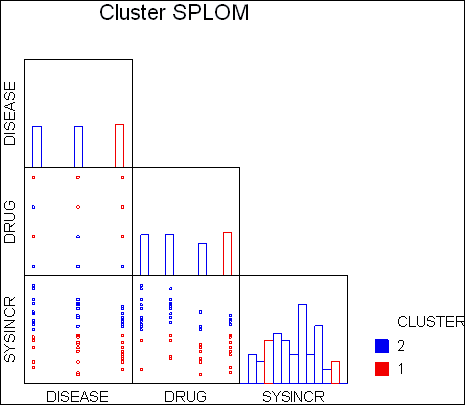
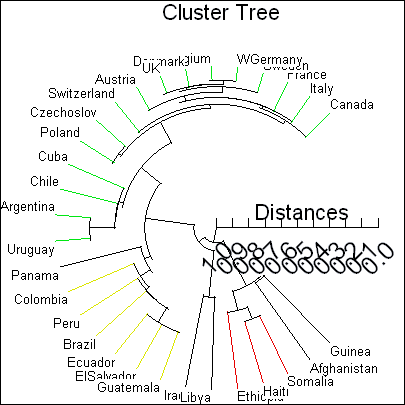
データのグルーピングを容易に検出
- SYSTAT のクラスター解析は、豊富な種類の距離および類似マトリクス、クラスタリング条件、検証指標、および、切断および剪定法を提供します。これによって、階層的分類やデータのグルーピングで最良の結果を得ることができます。新しいリンク法では、ユニフォームとカーネル、フレキシブルベータ、重み付きリンク、というリンク方法が搭載されています。新しい5つのインデックスでクラスタの妥当性を検証できます。クラスタツリーは、リーフノードおよびツリーの高さに基づいて剪定することができます。アルゴリズムには、K-means または K-medians を選択できます。
その他の新機能
- 時系列の傾向解析では、サンプルをランダムに抽出し、データに当てはめるためのいくつかの確率分布が追加されました。またデータタイプごとの尺度、比較法が加わっています。
- 多変量歪度、尖度の計算、多変量正規性の検定が可能です。
- 分散分析では、様々な2乗和の計算法が加わったほか、対称性に関する計算、検証が行えます。
- SYSTAT でモデルのフィッティングを行うと、アカイケおよびベイズに関する情報 (AIC および BIC) が計算されます。
- ブートストラップ解析法を搭載しているため、記述統計、相関、回帰分析では、標準誤差と信頼区間付きでブートストラップ推定量を計算することができます。
使いやすいグラフ機能
SYSTAT は、非常に豊富なグラフ機能を有しており、解析データに最適なグラフをいつでも作成することができます。SYSTAT では、ウィンドウを切り替えずに様々なグラフを作成することができます。いくつものグラフの比較や重ね合わせ、座標の変換や投影図の追加、色やシンボルの変更など、表現力に富んだプレゼンテーションが可能です。グラフの位置、軸ラベル、スケール、色やシンボルの設定変更など、簡単に行えます。また 3次元グラフでは Dynamic Explorer を使ってグラフを回転させ、最適な視野を得ることができます。その他、元データの要約が一緒に表示されます。
魅力的なグラフを素早く便利に作成
- 分析結果の報告には、SYSTAT に装備された豊富な学術グラフを使用しましょう。グラフは、必要に応じてカスタマイズできます。新しいインタラクティブなダイアログを使うことで、複数のグラフ要素を単一のダイアログボックス内で編集できます。
大規模データの便利で魅力的な表示法
- 二変数のヒストグラムをあらわす Hexagonal Binning は散布図を改良したグラフです。大規模なデータセットをあらわす場合に使用します。Hexagonal binning プロットは、画面を六角形のグリッドに分割します。六角形の半径はすべて同一の大きさですが、配色は X-Y の値の範囲に従って変化します。
強力なデータ操作機能
SYSTAT は、データの前処理のために、たくさんのデータ操作機能を有しています。簡単なメニュー操作で、データの変換、ソート、トリム、整形、選択、ランク付け、ラベル、グループ化、修正、重み付けが行えます。解析の概要、変数のラベルと情報、データのラベル、条件などの情報も、元データに付け加えられます。Data Editor 使用中は、最大32ステップのアンドゥとやり直しが可能です。(23, 15) に拡張されたデータフィールドによって、データの精度をアップさせることができます。変数名は最大 256 文字が使用できます。変数のプロパティダイアログには、変数の基本情報とヒストグラムが表示されます。
長い変数名によるフレキシブルなアウトプット
- 変数名と文字変数に使える文字数が最大 256 文字まで利用できるようになりました。アウトプットで変数名を省略する必要はもうありません。要求に合った形式でアウトプットを出力するには、非常にわずかな編集だけで済みます。
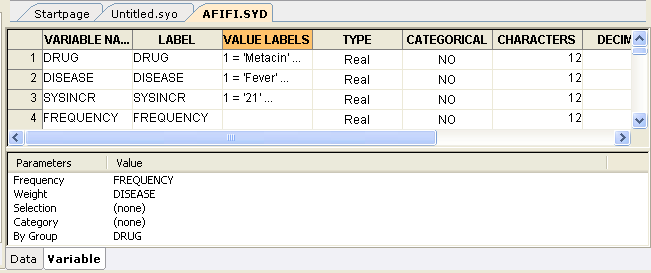
データタブと変数タブを使った分析のスピードアップ
- SYSTAT 12 の変数タブを使ってデータエディタ内で分析の準備ができます。データを表示するデータタブと、変数の情報を表示する変数タブを使うことで分析に更なるパワーを追加できます。変数ビューはタイプや幅など変数名に関する情報を提供する部分と、Frequency、Case selection などの処理条件を表示する部分の2つに分けられています。 カーソルをデータタブの変数名に移動させることで変数に関するコメントをツールチップの形で確認することもできます。ほとんどの操作をマウスクリックだけで取り扱うことができるので、分析にかかる時間が短くなり、データの本質を理解する作業が大幅に軽減されます。
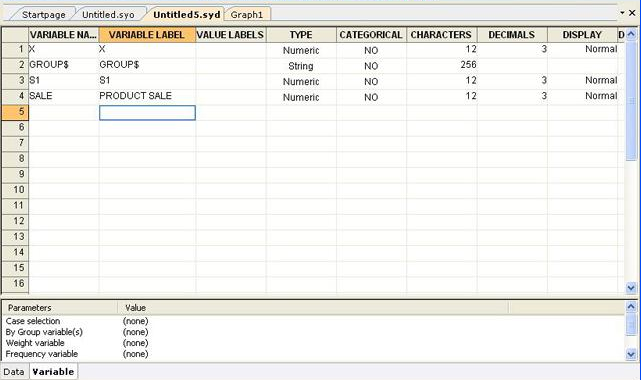
アンドゥ/リドゥによるデータ編集の簡素化と操作性の向上
- データエディタでは、アンドゥ機能を使うことができます。アンドゥとリドゥは一回のセッションで最大 32 ステップまでさかのぼることができます。これによって、誤って削除してしまった情報を簡単に復元することができます。作業の簡素化し、貴重な時間を節約できます。
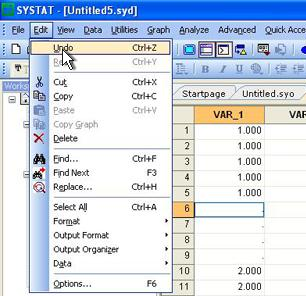
多くの新機能を使いこなす
- SYSTAT 12 では豊富な新機能が搭載されていますが、その多くは、ユーザーがこれまで以上に分析を容易に進められるよう特別に設計されています。 例えば、全てのプロシージャにはバブルヘルプ形式で簡単な説明が表示されるようになっています。
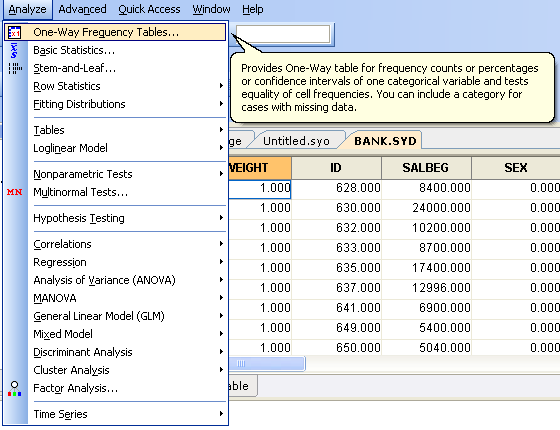
カスタマイズ可能な革新的インターフェース
SYSTAT 12 では、好きなようにメニューとツールバーをカスタマイズすることができます。操作が平易なメニュー対話方式にするか、直感的なコマンドライン入力を使うか、あるいはそれらの組み合わせにするか、選ぶことができます。Output Organizer によって、解析結果に素早くアクセスすることができます。またスタートページから、これまでに使用したデータセット、コマンドスクリプト、出力、および PDF マニュアルに簡単にアクセスすることも可能です。誤入力を防ぐファイル名、変数名、コマンドの自動記入機能が搭載されているほか、入出力形式も豊富です。
必要な情報が一目で分かるスタートページ
- スタートページには、最後に使ったファイルの情報、便利なチップス情報、テーマメニュー、マニュアルの PDF ファイルが表示され、簡単にアクセスすることができます。また、スクラッチパッドには必要な情報を書き留めておくこともできます。
互いに連動したコマンドライン・インターフェースとメニューダイアログ
- SYSTAT 12 のメニューダイアログとコマンドは相互に連動しています。これらを活用することで、作業を迅速に進めることができます。コマンドラインとメニューダイアログの任意の組み合わせでユーザーは効率的に作業を進めることができます。
自動記入機能による時間の節約とエラーの回避
- ファイル名、変数名、主要なコマンド名の入力には、SYSTAT の新しい自動記入機能が役立ちます。記入の途中で、既に入力した内容が入力候補としてリストであらわれ、そこから必要な情報を選択して入力することができます。以後は、ファイル名、変数名、コマンド名をそこから選んで簡単に入力することができます。これによって、スペルミスを防ぐことができます。
| 「SYSTAT 12 すばらしいところは、データの理解、変換、そして解析結果のインテグレーションが簡単にできるということを統計解析ソフトにもたらしたことです」と、Custom Decision Support 社の Eugene B. Lieb 社長がコメントしています。「しばしばデータ解析そのものよりも、解析結果をわかりやすく表現するために、多大な労力と時間を費やします。SYSTAT 12 の豊富なツール、使いやすさ、優れたグラフ機能、およびユーザーフレンドリーなインターフェースを体験したら、二度と手放せなくなります。」 Custom Decision Support 社の Eugene B. Lieb 社長 |
| 「SYSTAT は統計解析の専門的ニーズに応えるだけでなく、ドロップダウンのメニューを使って初心者でも簡単に使いこなせるソフトです。SYSTAT は GUI を搭載した最初の統計ソフトであり、現在でもユーザーインターフェースの使いやすさでは、他のソフトをリードしています。メインで使用している統計ソフトがあっても、SYSTAT をぜひ解析用ツールの一つに加えることを奨めます。グラフのすばらしさ、カスタマイズの容易さに舌を巻くことでしょう。様々な統計ソフトウェアがありますが、SYSTAT は間違いなくお奨めの一本です。」 Robert T. Brennan 博士、Harvard Medical School 「ユーザーインターフェースのカスタマイズ性では、他のソフトに比べ群を抜いて優れています。搭載されている機能、容易さで言えば最高レベルです。それだけでなく、SYSTAT 12 ではあらゆる機能が注意深く改良されています。私は 30 年間、様々な統計ソフトを使って大規模な公的データの解析をやってきましたが、統計ソフトを一つ選ぶなら SYSTAT 12 をお奨めします。私は今、毎日 SYSTAT 12 を使用しており、他のソフトを使用する気がなくなりました。」 Carl Desportes Bowman 教授、 Institute for Advanced Studies in Culture, University of Virginia |
バージョン 11 で追加された機能
SYSTAT 11ユーザーインターフェースの改良
SYSTAT 11 では、ユーザーインターフェースが全面的に改良されました。メニュー、スペース、ツールバーなどのカスタマイズ性が一層向上しました。
- メニューバーは新たに再編され、2つのアイテム (「ユーティリティ」と「モンテカルロ」) が追加されました。また、「統計」メニューは「解析」に変更されました。
- 読み込み可能なファイル形式として新たに Stata、Statistica、JMP、MINITAB、S+ などが追加されました。
- ※ただし、SYSTATと他のソフトとの仕様上の違いがあるため、100%の互換性はございません。
- ※ただし、SYSTATと他のソフトとの仕様上の違いがあるため、100%の互換性はございません。
- ダイアログボックスも多くが再編され、設定を追加するたびに個々のダイアログボックスが現われるのではなくタブを切り替えることで変更できるようになりました。
- マウスで操作できる機能はすべてキーボードでも操作できるようになりました。
オンラインヘルプの改良
- マウスの位置に沿ってインタラクティブにヘルプを表示する機能がダイアログボックス項目に加わりました。コンテクストにあわせてリンクする HTML 形式のヘルプも新しくなりました。広範にわたるツールチップも用意されています。ダイアログボックスのインプットフィールドには入力されるべき値の範囲がガイドとして表示されます。制限されたパラメータの入力項目をもつダイアログボックスでは複数入力が新たにできるようになりました。入力はユーザーによって追加・削除できます。
- マニュアルにある 500 を超える事例用コマンドファイルは SYSTAT ディレクトリに用意されます。これらは、わずかな修正で別のデータセットに適合させることができるので、ユーザーは同様の解析を時間をかけずに実行することができます。
グラフィクスにおける画質と操作性の向上
- SYSTAT 11 から、Microsoft の 16M 色カラーパレットを利用するようになりました。これによってグラフのより自由なカスタマイズ性と表現が可能になりました。インタラクティブな Graph Editor は、マウスオーバーにより、グラフの各要素の名前 (例:ラインプロット、ヒストグラム、X 軸の凡例など) をそれぞれ表示できます。グラフの各要素の外観 (例:ラインスタイル、塗りスタイル、フォント、カラーなど) は、右クリックによってインタラクティブに変更できます。テキストの編集は、テキスト要素をダブルクリックすることによって変更できます。座標系は、軸を設定したり、グリッドラインを表示/非表示にしたり、インタラクティブに変更することができます。
- 凡例の書式の変更が Graph Editor 上からできるようになりました。他のグラフを作成するために Graph Editor を使って軸の変数を変更できます。3D グラフは、Automatic (自動旋回) または Mouse Interactive (マウスによる旋回) によるアニメーション表示ができます。GIF、TIFF および PS ファイルに出力できます。ズームイン・ズームアウト機能には、選択範囲のズームと段階的なズームおよびマウスのドラッグによる移動によるズームが新たに追加されました。Poly Line と Arrow Setting エラーバーパラメータは、Graph Editor から利用できる新しい注釈オブジェクトです。
モンテカルロ法 (マルコフ連鎖モンテカルロ法を含む)
SYSTAT 11 では、強力な乱数生成アルゴリズム MT (Mersenne-Twister) 法を利用した乱数を発生させることができます。目的に応じた様々なプロパティをつけることで、ブートストラップやモンテカルロ検定を簡単に実行できます。
- SYSTAT 11 では、多くの乱数サンプル生成機能を備えています。IID モンテカルロ (IIDMC) とマルコフ連鎖モンテカルロ (MCMC) アルゴリズムを備えており、多くの標準的な分布、特殊な分布、間接的に特定された分布を選択することで様々な無作為標本を生成することができます。これらの機能はシミュレーションの実行に活用でき、分析的に解くには困難とされるベイズ問題における計算上の支援をします。
品質分析 (Quality Analysis)
SYSTAT の品質分析機能には、品質管理および改善に役立つ新しい統計手法と実績のある統計ツールが用意されています。 この品質分析には、基本的な統計ツールから生産過程に適用されるオンライン品質管理までの総合的な機能が含まれています。 SYSTAT で、さまざまな管理図、ヒストグラム、パレート図、箱ヒゲ図、ゲージ R & R 研究、工程能力分析、シグマ測定、タグチの損失関数、およびベータ補整法を使用したタグチのオンライン管理を使用することができます。 また、SYSTAT には、8 種類の統計分布の平均工程曲線および検査特性曲線も用意されています。
- 良く設計され管理された製造工程であっても、全く同一の製品は存在せず、変動は避けられません。SYSTAT のヒストグラムおよび箱ヒゲ図は、データのこのような変動の捕捉に役立ちます。 パレート図を使用すれば、最もよく発生する欠陥のタイプをすぐに目視で確認することができます。
- 工程改善プロジェクトの最初のステップは、反復性および再現性を調べることです。 SYSTAT のゲージR & R (Gauge R & R) 研究機能には、測定システムにおける部分対部分の変動、再現性、反復性の測定と、それに対応したグラフ表示が用意されています。 また、SYSTAT では、これらおよびゲージ R & R 指標の信頼区間も調べることができます。
- SYSTAT の工程能力分析は、指定した基準に対する工程の均一性を調べることが目的です。 さまざまな工程能力測定および工程性能測定のほかにも、SYSTAT では、正規分布とさまざまな非正規分布で同一のグラフ出力を使用することができます。
- シグマ測定機能を使用して、指定した DPMO (100 万回あたりの欠陥数) に対する量的特性について、工程のシグマ水準を計算することができます。 また、この機能を使用して、多段工程の歩留まりを調べることができます。
- 目標値の性質に基づいて、タグチの損失関数を計算することができます。目標値の性質として、通常は、望目特性、望小特性、望大特性の 3 種類を考えます。 SYSTAT では、この 3 種類のすべてを使用することができます。 タグチは、目標値のばらつきを測定するための信号対雑音 (S/N) 比と呼ばれる測度も提案しています。 これは製品の信頼性の測度で、品質損失関数を使用して S/N 比を求めることができます。 SYSTAT では、3 種類の目標値に対する S/N 比を調べることができます。
- 管理図は、標本 (合理的な群や時間など) に関して測定または計算した品質特性、つまり統計量(平均値や範囲など)を表すグラフです。 SYSTAT には、ラン、累積合計、移動平均、EWMA (指数で重み付けした移動平均)、XMR、回帰、TSQ (Hotelling の T2)の各グラフのほかにも、さまざまな Shewhart 管理図(X-bar、分散、s、R、X-bar と s、R、X-bar と R、X、np、p、c、u)が用意されています。 また、SYSTAT には、8 種類の統計分布の検査特性曲線および平均工程曲線も用意されています。 Shewhart、移動平均、EWMA、および X-MR の各グラフでは、Nelson (1984) によって提唱された 8 種類のラン検定も使用できます。
- SYSTAT のタグチのベータ補正法は、工程調整の大きさと頻度を決定します。 また、タグチの損失関数を使用して、調整の「前」および「後」の品質を比較することもできます。
確率分布(Probability Distributions)
SYSTAT の 13 の分布は、離散型および連続型、単一変量および多変量分布を含む 33 に拡張されました。これら 33 種の分布を元に、任意のサイズのランダムサンプルを任意の数で出力できます。
- 確率計算 (確率密度関数/累積分布関数/ 逆累積分布関数) は、メニューを選択することによってインタラクティブに実行できます。分布のフィッティングは、カイ二乗適合度検定 (chi-square goodness-of-fit tes) と Kolmogorov-Smirnov 検定を含む 28 種の単変量離散から実行できます。Shapiro-Wilk 正規性検定では、正規、対数正規、ロジット正規分布フィッティングを選択できます。
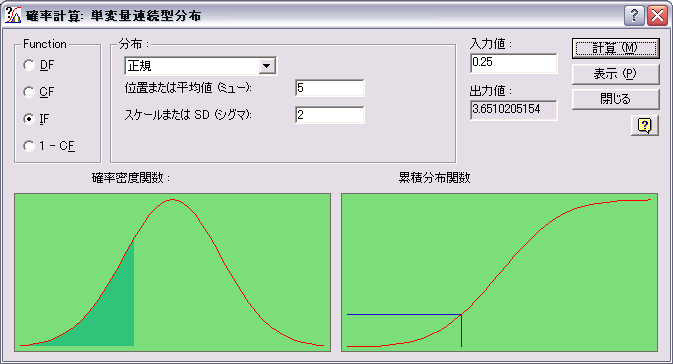
新しい回帰分析法 (New Regression Techniques)
ベイズ回帰モデルは、多重線形回帰モデルにおけるフィッティングの新しいパラダイムです。ベイジアンの手法では、多重線形回帰モデルの回帰パラメータの推定値は、事前情報をパラメータの事前分布の形式に組み込むことで求められます。
- エラーの成分に正規分布が含まれる場合、クラシカルなベイジアン分析において広く使用されていた事前分布は(多変量)正規- ガンマ分布です。 この手法の利点は、共役事前分布であるという点にあり、回帰パラメータの事後分布の形式が事前分布の形式と同じになります。ベイジアンの手法にはもう一つ利点があり、「信頼区間」の形式のパラメータに関する直接確率文を生成します。
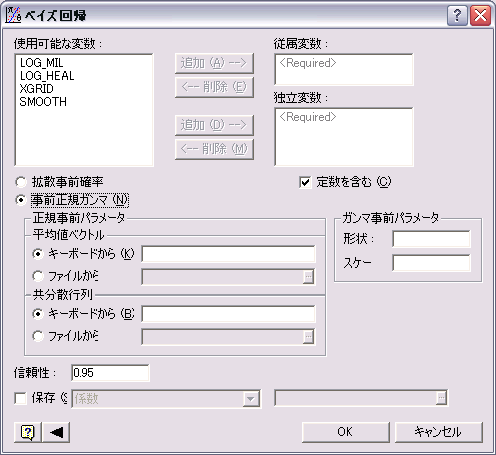
- 「ロバスト回帰」機能には、データに外れ値が含まれている場合の多重線形回帰モデルのあてはめに使用する、LMS 回帰 (最小二乗メディアン) プロシージャおよびランク回帰プロシージャが用意されています。 また、「非線形モデル」の「ロバスト」オプションを使用して、最小絶対偏差 (LAD) 回帰および M 回帰 (M-Regression)を実行することができます。
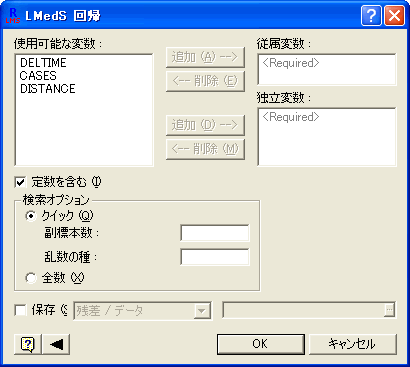
- ロバスト回帰機能の LMS 回帰は、残差の平方の中央値を最小化することにより、頑健なあてはめを生成します。 また、残差/データ回帰係数を保存することができます。
- ランク回帰はノンパラメトリック回帰を実行します。 残差の順位に基づくスコア関数を最小化します。 回帰係数を保存することができます。
行統計(Row Statistics)
- 基本統計 (Basic Statistics) と幹葉図 (Stem-and-Leaf plot)はすべて、列とは別に Row Statistics (行の統計) が新たに利用できるようになりました。N & P-Tiles (N 分位点/ P 分位点-新機能) の設定では 7種類の方法で計算できます。
仮説検定(Hypothesis Testing)
- 検定で Variance (分散)、Correlation (相関)、Proportion (出現率) が利用できるようになりました。これらの検定では、平均のための検定のほかに片側検定 (one-sided alternatives) も利用できます。
検出力分析 (Power Analysis)
- 検出力分析では、片側検定 (one-sided alternatives) が利用できるようになりました。
多変量解析 (Multivariate Analysis)
- Multivariate Analysis (多変量解析) 機能は、ドロップダウンメニュー項目のひとつに再編され、新たに MANOVA (多変量分散分析) 機能が追加されました。MANOVA の中には良く使われる検定プロシージャが含まれます。
- 多変量分散分析(MANOVA)機能を使用して、1 元配置、2 元配置および多元配置多変量データの推定および検定、反復測定分析、および群内あるいは群間検定を行うことができます。 標準実験計画および交差とネスティングによる標準要因処理構造(Standard factorial treatment structures)を使用して取得したデータの多変量解析も含まれています。
- 多変量分散分析は、パラメータ推定値および最小 2 乗平均値ベクトルが供給される基本分析から始まります。 次に、仮説検定の結果が続き、適切な統計量とその p 値に関する多変量検定の結果のほかに、各(独立)変数(多変量データ ベクトルの成分)に対応する単変量検定の結果も供給されます。
行列の演算 (Matrix Computations)
- 行列操作や行列演算は、すべてメニューから実行できるようになりました。