2水準完全実施要因計画
1.はじめに
このチュートリアルでは、Design‐Expert® ソフトウェアで2水準完全実施要因計画を取り扱う方法を紹介します。2水準完全実施要因計画とは、多数の因子から重要な少数因子をしぼりこむのに役立つ計画です。急いでいる場合は、囲み内のセクションを飛ばしてください。これらは、さらに時間をかけて詳しく学びたい人向けの補足的内容となっています。
| ※ プログラムの基本機能について このチュートリアルを始める前に、まず「一元配置実験」チュートリアルを確認してください。そこの説明で紹介した機能については、ここで詳しく説明しません。 |
これから分析するデータは、Douglas Montgomery の著書『Design and Analysis of Experiments』(出版:John Wiley and Sons, New York) からの引用です。ウエハー・ボード製造業者は、ろ過工程の加工助剤にホルムアルデヒドを利用しますが、この濃度を出来るだけ速やかに軽減する必要があります。これを怠れば、取締官によって操業停止に追い込まれてしまいます。工程技師は自らどのような選択肢を取るべきかを系統的に調べるために、濃度 (Concentration) を含む主要な因子について、2水準完全実施要因計画を実施します。濃度因子には現行の水準と規制条件を満たす低水準の値が設けられます。
| Factor | Units | Low Level (–) | High Level (+) |
|---|---|---|---|
| A. Temperature | deg C | 24 | 35 |
| B. Pressure | psig | 10 | 15 |
| C. Concentration | percent | 2 | 4 |
| D. Stir Rate | rpm | 15 | 30 |
実験者は上記で設定した工程の組み合わせに基づいて、それぞれのろ過速度(filtration rate)を記録しました。この実験の最終目標は、ろ過速度を最大化しながら、ホルムアルデヒド(因子 C)の濃度をできるだけ低く抑える条件を見つけ出すことです。この事例では、Design‐ Expert が提供する2水準要因計画の機能の多くを実習します。チュートリアルが終わる頃にはきっとパワーユーザーになっているでしょう。それでは、出発しましょう!
| ※ 変更困難な因子(温度など)の場合 実験における試行の順序は完全に無作為化されているのが理想的で、Design-Expertではこのレイアウトがデフォルトとなっています。 一つあるいは複数の因子をすぐに変更するのが非常に困難でこれに対応できない場合は、分割法を選択してください。 ただし、無作為化で制限されるようになる因子の統計的検出力が、減少することに留意してください。 分割法に着手する前に “機能ツアー” を参照して、Design-Expert でこうした実験を行う際のおおよその手順と、効果の選択で注意すべき点を理解しておいてください。 |
2.実験の計画
Design-Expert ソフトウェアのアイコンをダブルクリックしてプログラムを起動します。“File” -> “New Design” を選択します。
画面の左側に4つのブランチが表示されます。デフォルトで表示される階乗の選択を維持し、デフォルトの選択である “Randomized Regular Two-Factorial” を使用します。
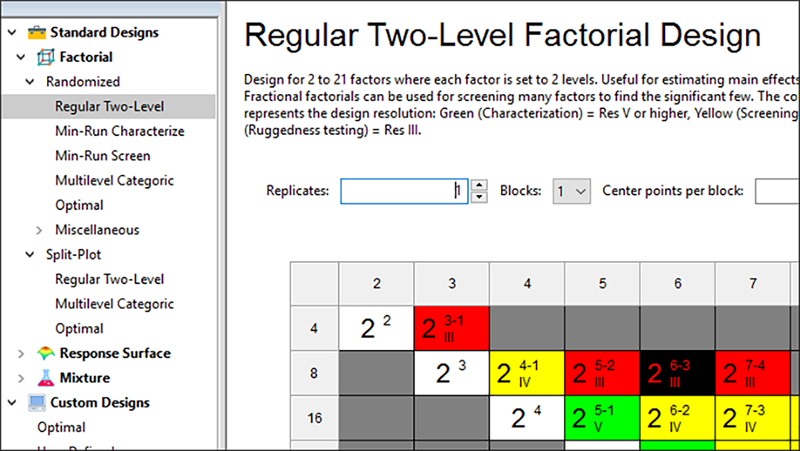 2水準要因計画ビルダー ※ 注意 この計画ビルダーでは、因子数2~21までの2水準要因の完全実施および一部実施計画を設計できます。試行回数は、2のべき乗 (4, 8, 16…) で最大 512 回です。画面上にカラーで色分けされているのが選択肢です。白色の正方形は、試行数 2k 回を要する完全実施要因計画を表します。このとき k(因子数)は 2 から 9 までの値をとります。他の選択肢は、信号のように色分けされています。緑は進め、黄色は注意して進め、赤は止まれ。これらはそれぞれ分解能の程度の違い、すなわち V 以上、IV、III を表します。ここに示したカラーコードの概要を素早く知るには、スクリーンチップスボタン |
それでは、この完全実施計画の事例を進めてゆきましょう。24 とラベルの付いた白の正方形をクリックしてください。因子数が 4 の列で、Runs 行のラベル 16 の場所にあります。
“Next” ボタンをクリックします。単に、選択したセルをダブルクリックしても同様に次に進むことができます。名称、測定単位、実験の因子の水準を入力することができます。空白を移動するには、矢印キー、Tab キー、またはマウスを使用します。以下のスクリーンショットのように、各因子(A, B, C および D)の Name, Units, Low, High 水準を入力します。
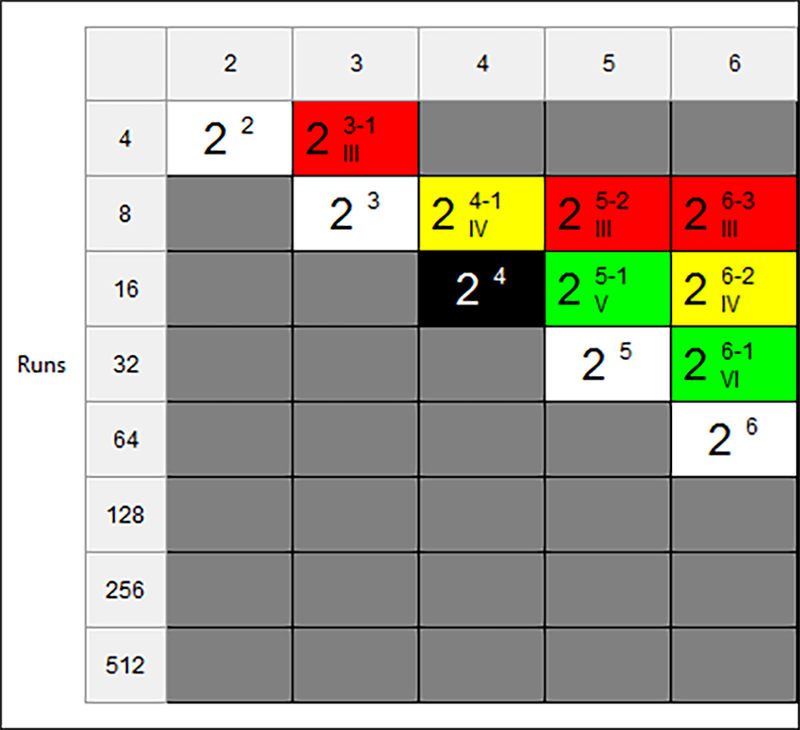
 各因子の指定:名称、単位、水準を入力 ※ 英数字からなる水準の入力方法 因子は2つのタイプ(数値型 “Numeric” またはカテゴリー型 “Categoric”)で表すことができます。数値型データは、温度や圧力など連続的な尺度を持つデータを表します。カテゴリー型データは、触媒系や自動車の型式など、水準間にはっきりとした区別を持つデータを表します。Design‐Expert では、カテゴリー型因子の水準に文字列を使用できます(例:“Low” や “High” などの語)。因子タイプを変更するには、Type 列のセルをクリックして、ドロップダウンリストから “Categoric” を選択するか、あるいは、キーボードから “C” とタイプしてください(“N” とタイプすると数値型を指定できます)。それぞれの方法を実際に試してみてください。この事例では、デフォルトの “Numeric”(数値型)のままにしておきましょう。 |
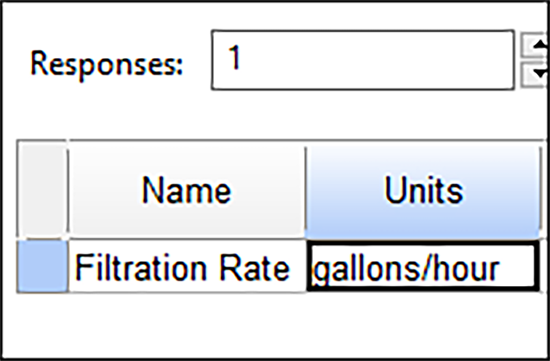
次に “Next” ボタンをクリックして、Responses ダイアログボックスを起動してください。リスト矢印を使って、最大 999 までの応答数を入力できます(必要があれば後から追加することもできます)。この事例では、応答名(Name : Filtration Rate)と単位(Units: gallons/hour)を、以下のようにそれぞれひとつずつ入力します。
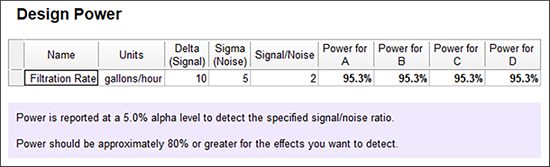
実験計画の検出力を評価するのにちょうど良いタイミングです。このケースの場合、管理者は平均が毎時「10」ガロン未満の相違は考慮しません(これより小さい場合は改善の価値がないため)。技術記録には標準偏差が「5」であると示されます (プロセスの変動) 。これらの値を以下のように入力してください。Design‐Expert により S/N 比が 2 と計算されます(10/5=2)。
“Next” をクリックしてください。結果は良好です。目的とする差を見分けられる検出力の確率が 80% を上回っています。
“Finish” をクリックして、入力内容を適用すると、計画割付表ウィンドウが生成されます。

以上で DOE の第一段階(実験の計画)は完了です。これは Design‐Expert ソフトウェアが提供する重要な4つの機能の一つであることに注意してください。その他の重要な機能としては、Analysis(分析)、Optimization(最適化)、Post Analysis(予測、確認など)があります。
| ※ 注意 Notes ノードをクリックして、デフォルトでここに何が記入されているかを確認してください。必要に応じてここにコメントを入力してください。  データファイルに関するノート Design ノードをクリックしてノートページを終了します。(Design ノードの表示が Design (Actual) となっている点に注目してください – これは因子が、コード表記とは対になる、実際の水準:実測値で表示されていることを意味します) 。 |
この時点で作業が一段落済みましたので、計画を保存してみましょう。これを行う最も簡単な方法は、標準の保存アイコン ![]() をクリックすることです。
をクリックすることです。
3.結果の分析
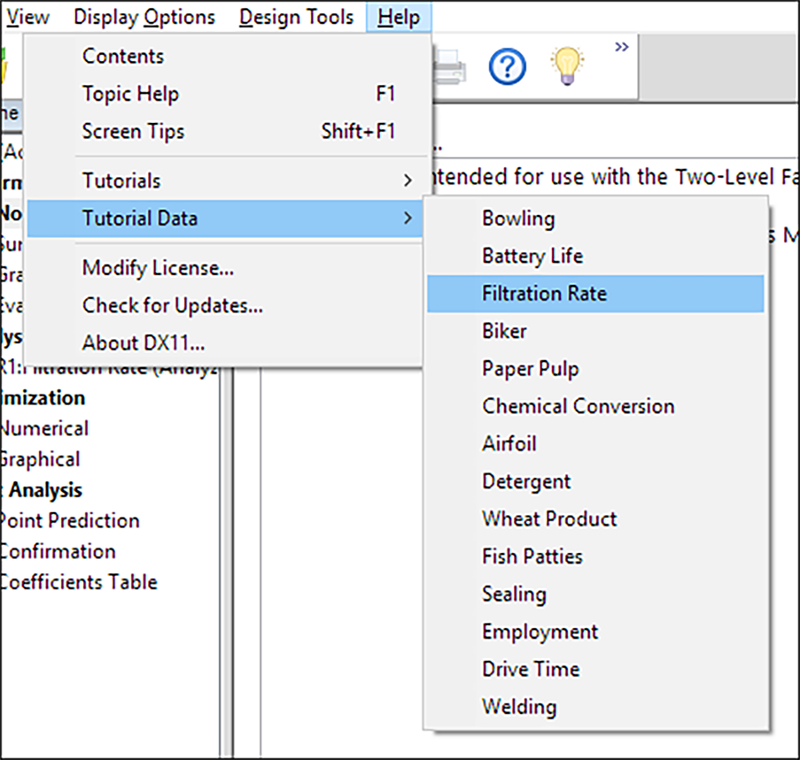
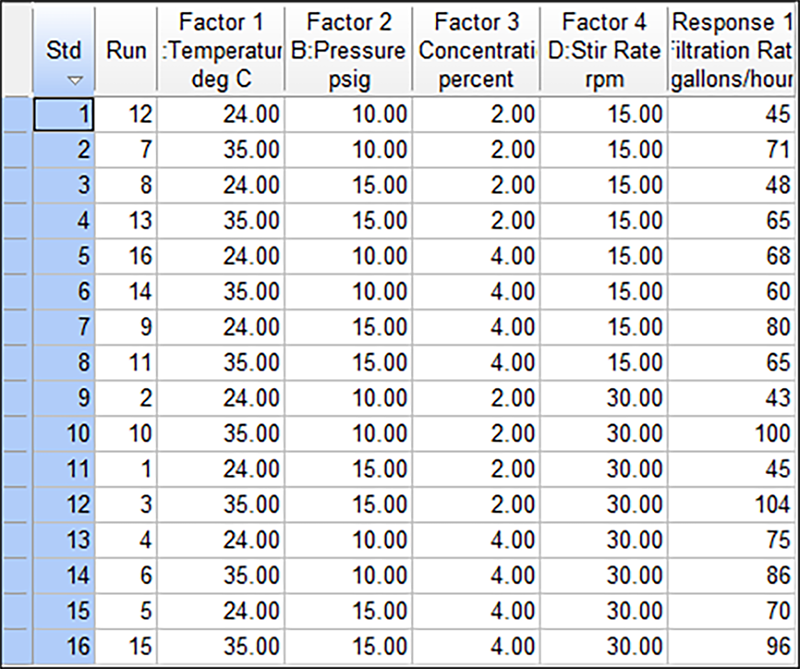
この段階で、作成した計画を印刷すれば、実験の測定記入用紙として利用できます。実験で記録された応答値をここに記入できます。試行順はソフトウェアにより自動的に無作為化されるので、時間、気温、湿度などのあらゆる潜伏因子から保護されます。さてこのチュートリアルでは、“Help” -> “Tutorial Data” -> “Filtration Rate” をクリックして、データをロードします。
Std 列のヘッダー(Std とラベル付けされた灰色の四角部分)をダブルクリックして、以下のように並び替えます。
実行順が無作為化されていることを除けば現在データはチュートリアルの内容と一致しているはずです(自分で実験を実行する際は、常に無作為順に並び変えてください。これをしなければ、時間とともに変化する潜伏因子により結果が偏ったものになります)。実行順が無作為化されていることを除けば現在データはチュートリアルの内容と一致しているはずです(自分で実験を実行する際は、常に無作為順に並び変えてください。これをしなければ、時間とともに変化する潜伏因子により結果が偏ったものになります)。
| ※ 列幅の調整方法 切り捨てられた列のサイズを自動的に変更するには、両方向矢印( |
以上で応答データを記録できましたので、ファイルを保存する良い機会となりました。保存アイコン ![]() をクリックして更新されたファイルを保存してください。
をクリックして更新されたファイルを保存してください。
| ※ 数値フォーマットの変更 この応答データは、一般的なフォーマットで保存されました。これを固定フォーマットで保存すれば、より整然とした出力結果を得ることができます。Response 列のヘッダーにマウスを移動して、クリックし、画面の左側にある Design Properties ペインを確認します。 “Format” ボックスをクリックすると、“General” の横に下向き矢印が表示されます。下矢印をクリックして、“0.0” を選択します 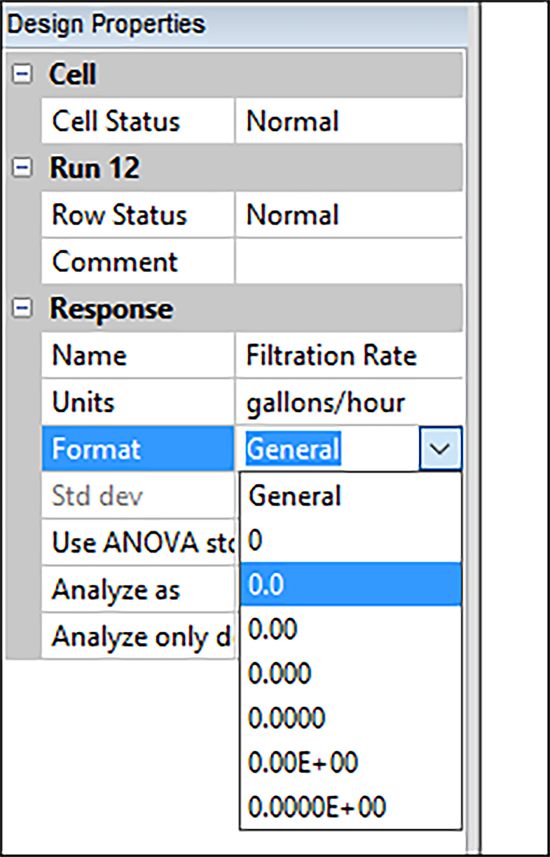 フォーマットの変更 Design Properties ペインを使用して、入力要素の形式、名前、またはレベルを変更することもできます。他の列見出しをクリックして、試してみてください。 |
Design‐Expert では計画の因子水準を2つの方法で表示できます
- Actual (実測値):実際に測定した因子の水準
- Coded (コード表記):低水準 (Low Level) を -1、高水準 (High Level) を +1 とするもの
デフォルトの計画では、実際の因子水準 (Actual) が実行順に配置されます。
| ※ コード形式で因子を表示するには 計画をコード表記の値で表示するには、メニューバーの “Display Options” をクリックして、“Process Factors” -> “Coded” を選択してください。このとき画面は以下のようになっているはずです。 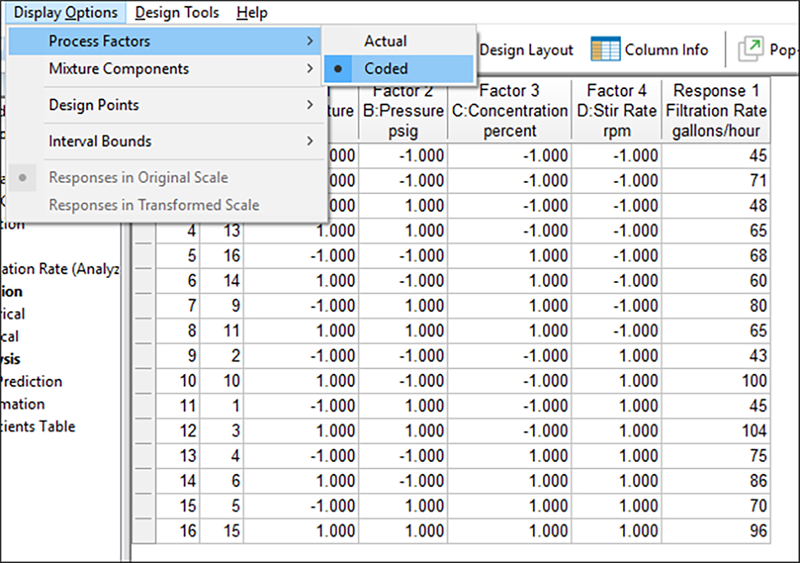 因子水準をコード表記にした計画の配置 (実行順は異なる場合があります) Design ノードにはカッコで “coded” と表示されている点に注目してください: Design (Coded)。これは任意の因子水準が設計点から変化したかどうかを誰もが一目で見分けられるという点で役に立ちます。 それでは、メニューバーの “Display Options” から “Process Factors” -> “Actual” を選択して、因子を元の値に戻しましょう。 |
4.データの並び替えと単純な散布図による効果の事前分析
Design‐Expert には、詳細な分析に進む前に、実験データの全体的な方向性 (overall sense) を確かめるための様々な機能が用意されています。例えば、列をダブルクリックすれば、その内容を素早く並び替えることができます。
実際に確かめてみましょう。Factor 1 (A: Temperature) の列の上部にマウスを移動してダブルクリックすると、その内容が昇順でソートされます。再度ダブルクリックすると降順で並び替えられます。もう一度実行して (矢印が下向きになります) low から high の温度変化が、どのようにろ過に影響するか確認してください。
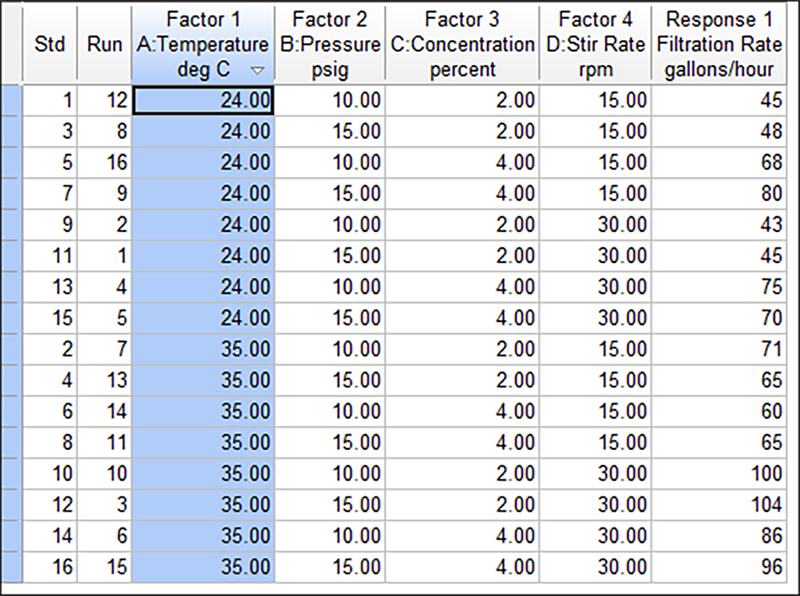
これにより、応答に対する気温の影響をより明確に把握できるはずです。さらに良いことには、画面左上にあるツリー構造の Design から枝分かれした Graph Columns ノードを選択することで、応答と因子 A のプロットを作成できます。これにより、因子 A : Temperature を X 軸に、Filtration Rate の応答を Y 軸とした散布図が表示できるはずです。
気温が応答に対して、大きな影響をもたらすことがこれを見てわかります。凡例の上に高い相関がレポートされている点に注目してください。

温度と、ろ過率の強い関係を示すもうひとつの指標は、これら2つの変数が相関グリッドで交差する赤い部分です。なお、グリッドのすぐ上にある相関をあらわす色分けスケールの隣を見ると、相関を数字で確認できることにも注意してください。
次の因子、B の影響を確認するには上記のように右の四角部分をクリックします。Pressure は、ろ過速度とあまり相関がないことが分かりました-つまりこの関係は有意ではないと判明しました(相関は 0.08 と低い値です)。
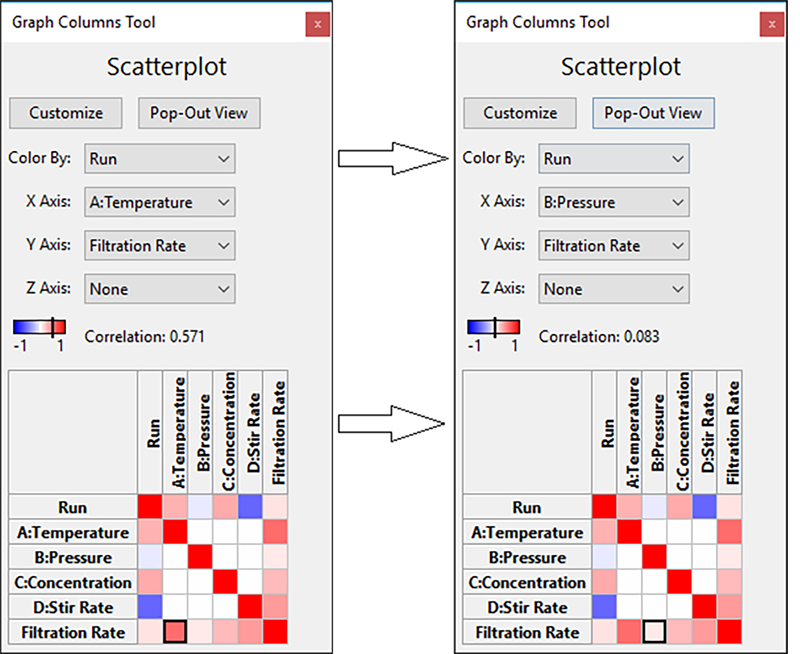
| ※ Color By 機能の利用法 A 対 Filtration Rate の散布図に戻ります。デフォルトのポイントの色分けは標準順序(standard color)に設定されます。以下のように Color By ドロップダウンリストをクリックして “C:Concentration” を選択してみてください。 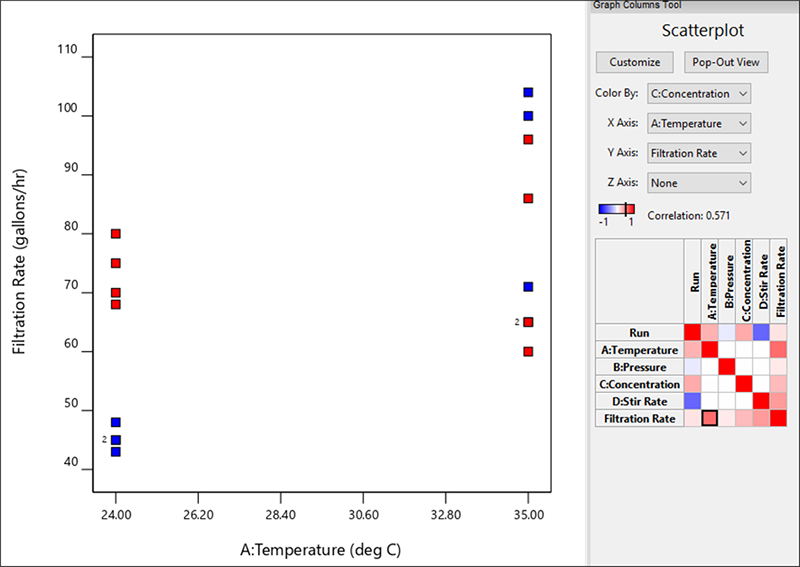 気温 対 ろ過速度のグラフの列を濃度で色分け 2つの色が気温の両水準において、どのように層をなしているかお分かりですか?二つは対照的です。左側(気温が 24℃)では、赤がろ過速度の上端にプロットされているのに対して、右側では青がろ過速度の上部に現れています。ろ過速度の効果に対する濃度と温度の影響のしかたについて、このグラフで何が表されているか、じっくり検討してみてください。しかし、ここで結論を先取りするのはやめておきましょう。これは、より高度なグラフや統計ツールを駆使して、分析をより徹底したものにするための準備段階にすぎないからです。 |
プロット上の幾つかのポイントの横に “2” という数字が表示されているのを不思議に思う人がいるかも知れません。この表記は同じ位置に複数のポイントが存在することを表しています。これらのポイントの1つを複数回クリックして、個々の実行を識別します(グラフの左側の凡例を見てください)。
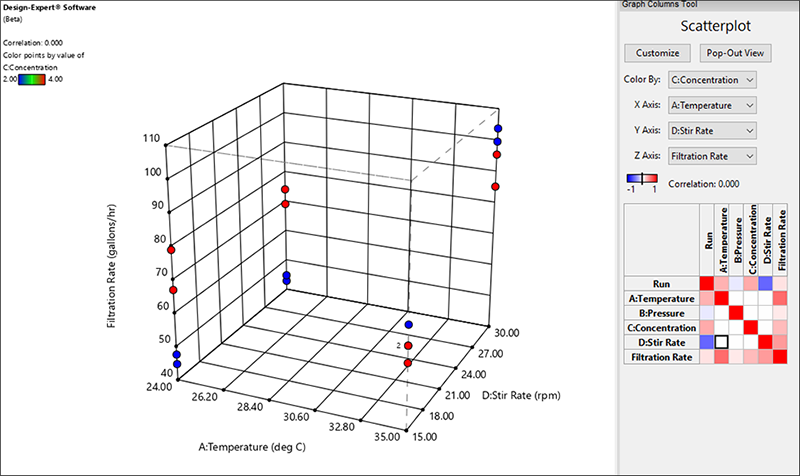
より有用な散布図を作成するには、Y Axisを“D:Stir Rate”に変更し、Z-Axisを“Filtration Rate”に変更します。これにより、グラフの列が3次元にシフトし、左上の応答を最大化するための条件の3D散布図が表示されます。上部の青い点は、低濃度のホルムアルデヒドです。これは良好な結果であると窺えます。
次より、Design-Expertの強力な分析機能を利用して、実際になにが起こっているのか調べていきましょう。
5.実験結果の分析
計画の分析を開始するには、画面の左側にある “Filtration Rate” 応答ノードをクリックしてください。これをクリックすると、画面上部に分析ツールバーが表示されます。統計解析を実行するには、このボタンを左から右へ順番にクリックしていくだけです。
最初に選択されているのは、以下の図に示すように Transform ボタンです。Transform では、応答データに適用する数学関数のリストが提示されます。
| ※ 変換オプションについて それぞれの詳細な説明は Tips ボタンをクリックしてください。 |
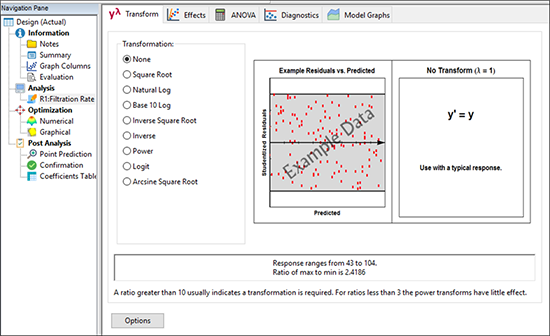
Transform 画面の下側には Design‐Expert による注記として、応答範囲が 2 倍(最大値と最小値の比率は 2.4186)を超えていることを示しています。この値は、べき変換での効果がわずかしか期待できない(“…power transforms have little effect.”)3 を下回っています。したがって、数学的変換はここではデフォルトの “None” のままにしておきましょう。後で説明する診断プロット(Box-Cox)では、トランスフォームが必要であればその旨が告知されます。
モデルの効果の選択
“Effects” タブをクリックしてください。画面には、全効果(正方形のプロット)の絶対値が半正規確率プロット上に表示されます。右側はパレート図です(詳細は後で説明します)。 効果の正負 Positive/Negative Effect は色分けにより判別できます。
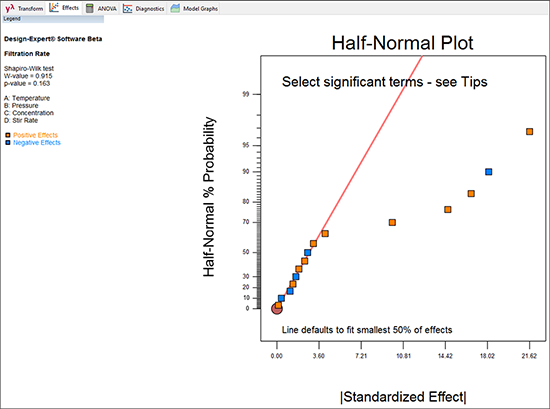
画面上に表示されたメッセージに注目してください:“Select significant terms – see Tips.”(有意項を選択してください – 詳しくは Tips をご覧ください)。ここで、どの効果をモデルに組み入れるかを選択する必要があります。この時点でモデルに組み込む効果を選択しないで先に進むと、“You have not selected any factors for the model.”(モデルで使用する因子が選択されていません)と始まる警告メッセージが表示されます。これを無視して先に進むこともできますが、その場合は(効果のない)モデルとしての意味しかもちません。それが嫌なら、Effects ビューに戻って指定しなおすこともできます(この方が遥かによい判断です!)。
効果の選択は、正方形のポイントをマウスでクリックするだけです。まず始めに、以下の図と同じように、プロットの右端にある最大の効果をクリックしてください。この際パレート図でも選択されます。
デフォルトでは、最小効果の50%を意味する赤い “error line” が表示されます。このラインは、効果を選択する際の基準を視覚的に示す役目を果たします。重要でない効果は 0 付近のライン上に並ぶはずです。もし、このラインが小さい効果に合致しない場合は、このラインをクリックして最小効果(左側)のグループと揃うところにドラッグすることができます。
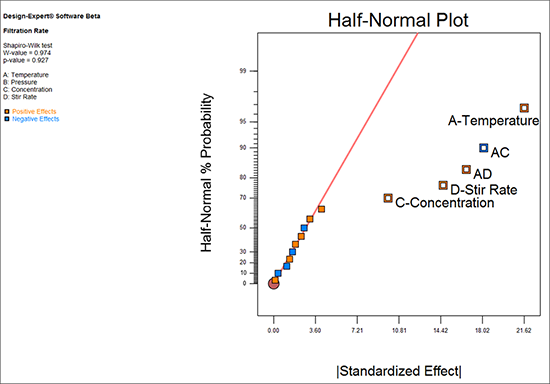
ラインから外れたすべての効果が選択されるまで右から左へ個々の効果を選択していってください。この例では、最後の効果は因子 C です。因子 C とゼロ付近に並ぶさらに小さい効果には大きな隔たりがあります。大抵の場合、この隔たりが効果の選択をやめる良い指標となります。
| ※ 注意 スクリーンチップスボタン( |
ボックスをドラッグして、一度に複数のエフェクトを選択することもできます。
選択した効果の大きさを実際に確認するために、Design-Expertは、パレート図と呼ばれる順序付けられた棒グラフにそれらを表示します。縦軸は絶対効果のt値を示していることに注意してください。この無次元統計は、標準偏差の観点から効果をスケーリングします。この場合、グラフの外観に違いはありませんが、因子レベルの失敗やデータの欠落などが発生した場合、t値スケールは相対効果のより正確な測定値を提供します。次に大きいバーをクリックすると、以下に示すようにABDとして識別されます(右下)。
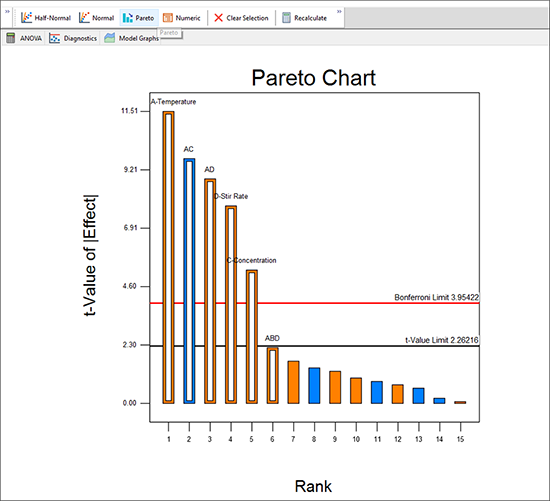
ABD バーは下限値よりも下にあることに注意してください。したがって ABD バーはクリックして除外します。
| ※ 効果の統計的計算について “Numeric” をクリックすると選択したモデルの効果と、それ以外の推定誤差の詳細を定量的に確認することができます。見やすくするには、上部にあるフルウィンドウアイコン 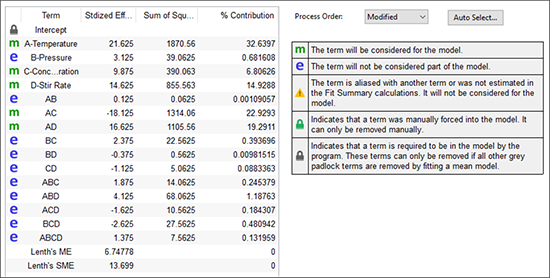 効果リスト |
ANOVA と統計解析
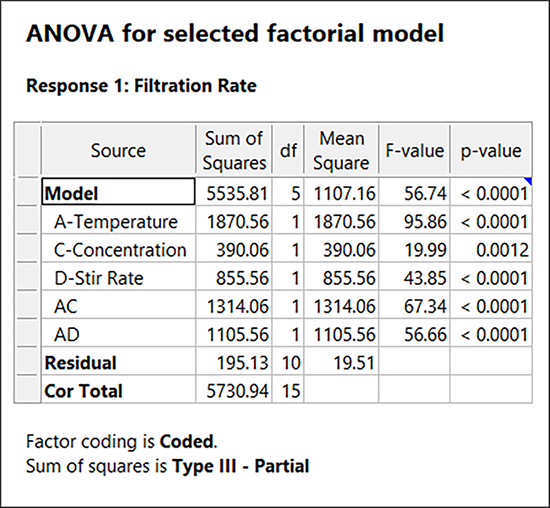
さて、いよいよ分散分析(ANOVA)表をもちいて、統計の詳細をみてゆく段階となりました。“ANOVA” タブをクリックして、選択した効果とその係数を見てみましょう。Design‐Expert のデフォルトでは、青いテキストで注釈が表示されます。
| ※ 注意 注釈の表示/非表示は View で切り替えることができます。 |
Model の確率(p-value)を見てください。Design‐Expert のデフォルトでは、値が 0.05 以下であればそれを有意 significant と判断します。これは、“Edit” -> “Preferences” -> “Math Preferences” -> “Math Analysis”で変更できます。
モデル項 A、C、D、AC、AD に関する P-value についても調べてみると、いずれも 0.05 の判定基準を余裕で通過しています。
| ※ 文脈依存型のヘルプについて ある数値を右クリックして “Help” を選択すると、ANOVA 表の数値に関する定義を表示させることができます。試しに平均二乗残差 (Mean Square Residual) の統計値についてこれを実行してみてください。以下の図のようになります。  文脈依存型 Help へのアクセス |
R‐squared(R二乗)やその他の統計値を見たい場合は、ANOVA の出力結果の他のペインを確認してください。また、それぞれに付いた注釈を参照し、さらに詳しいことを知りたい場合は Help にアクセスしてください。そして、“Coefficients”タブを見て、モデル係数とそれに関連する統計の推定値を確認しましょう。最後に、コード化された表記とコード化されていない表記の両方の予測方程式について、“Coded Equation”タブと“Actual Equation”タブを確認しましょう。
数について論じるのはこれぐらいにして、次に進んで最終的に効果グラフに話をさせましょう。しかし、その前にモデルの有効性を検証する必要があります。
モデルの有効性の検証
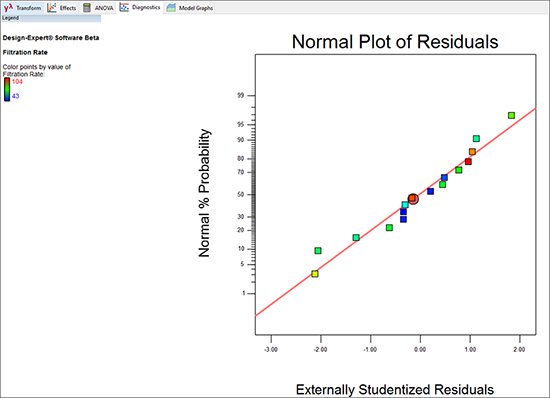
“Diagnostics” タブをクリックして、残差の正規確率プロットを作成してください。
デフォルトでは、残差はスチューデント化されます。これは原則として、標準偏差スケールに変換されます。また、外的に実行され、残差の計算の前にそれぞれの結果が除外されます。統計の専門家たちはこの手法を“case-deletion diagnostic” と呼びます。実験や測定でなにかが上手くいかずに特定の試行に実際の外れ値が生成される場合は、モデルのフィッティングに影響を与える前に矛盾する値が削除されます。これにより、あらゆる異常の検出力が向上します。
| ※ 生の残差 (raw residuals) オプションについて このような2水準完全実施要因計画の場合、生の残差を(元の測定単位で)プロットすることも同様に効果的です。以下のように Diagnostics Toolbar のプルダウンオプションで “Residuals”(raw)を選択して実際に確認してみてください(パターンに明らかな変化はありません)。  残差の様式の変更 最終的には、スチューデント化されたスケールに戻すことをお勧めします。一般的にはこれが残差を診断するもっとも堅牢な手法だからです。 |
残差の正規プロットは、直線に近づけば近づくほど異常性がないことをあらわします(データは完全に直線上にプロットされる必要はありません。これには、「太鉛筆検定」と呼ばれる有効な経験則があります。太めの鉛筆を直線上に置いて、データポイントがそれによってすべて隠れるようであれば、そのデータは十分に正規性があると判定するものです)。この事例のプロットをみると、特に問題ないようですので次に進むことにしましょう。
“Resid. vs. Pred.” を選択してください。以下のようなグラフが表示されます。
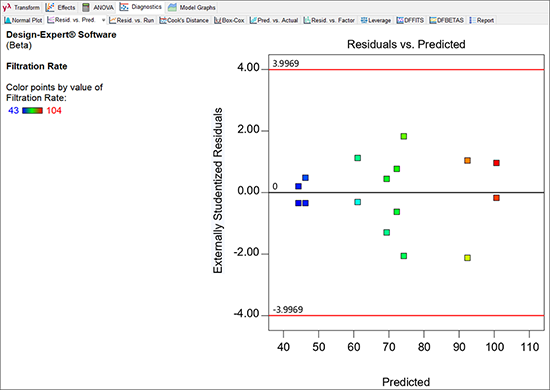
残差のサイズは、その予測値とは無関係(independent)である必要があります。別の言葉で言い換えれば、スチューデント化された残差の縦方向の広がりは、予測された値の水準全域にわたってほぼ均一である必要があるということです。この事例のプロットをみると、特に問題はなさそうです。
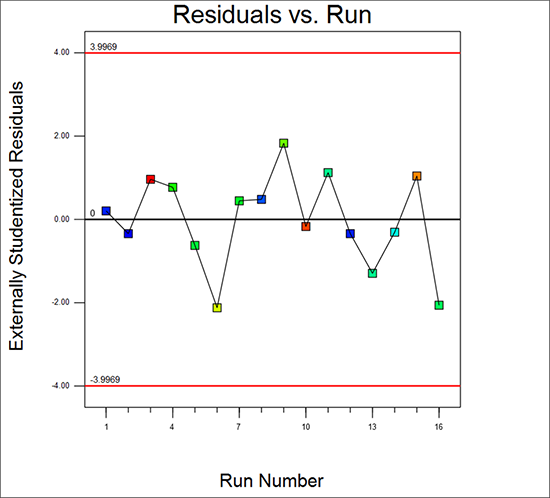
次は “Resid. vs. Run.” を選択して「外れ値 t 」と呼ばれることが多い、とても便利なプロットを見てみます。特定の試行における標準偏差(t 値)が、他のすべての想定と比較して解離しているのはいくつかを表示できるためです。
Design‐Expert には、ランチャートの信頼区間 95% の管理限界とよく似た赤のラインが上下に表示されます。この事例では、突出した点は特にありません。なお、グラフは試行順を無作為化してプロットしているため、実際の画面では、ここに示したポイントの順番とは異なる場合があります。実際の画面では、外れ値だけでなくパターンを見るようにしてください。分かりやすい例は、最初から最後まで残差が着実に減少している、つまり、減少傾向であるということでしょう。これはシステムの安定性の問題を引き起こしますので、調査する価値は十分あります。ただし、実験を順不同で試行して、結果にバイアスをかける応答の傾向に対するプロテクトを取り入れます。
| ※ 範囲から外れたポイントについて 外れ値がひとつでもあれば、それをクリックして、グラフの左側にそのポイントの座標を表示させることができます。プログラムはこのポイントを記憶し、他のプロットでもこのポイントの選択状態は保持されます。この機能を使えば疑わしいポイントなら何でも追跡できるため、特に残差の分析で役立ちます。この機能は、グラフの解釈にも利用できます。ぜひお試しください。このグラフ以外の任意の場所をクリックして、ポイントを非表示にしてください。 以下のように、ポイントを強調するオプションを使用しても有益でしょう。  このフラグを使用すると、デザインレイアウトや Design-Expert 内のあらゆる場所にさかのぼって追跡し続けることができます。試してみてください! |
Box Cox プロットに進みましょう。これは、最適なべき乗則変換を計算するために考案されたものです(詳細は Montgomery 著 Design and Analysis of Experiments を参照してください)。画面の左側に推奨される数学的変換がテキストで表示されます。この事例の場合は “None” です。実際に知りたい情報はこれだけです!
| ※ Box-Coxの詳細について この内容をもっと詳しく掘り下げたい人は、Box‐Cox 画面が解釈に役立つよう色分けされている点に注目してください。青のラインは、現在の変換を表します。この事例の場合、応答値に適用するべき乗を表す Lambda 値として青のラインは 1 を指し示しています。Lambda 値 1 は、変換の必要がないことを表しています。緑のラインは最適な Lambda 値を表しており、赤のラインはその値を囲む 95% 信頼区間を表しています。この 95% 信頼区間に 1 が含まれれば、推奨される変換はないことになります。以上をまとめると、次のようになります:青のラインが赤のラインの間にあれば、それは現在最適な領域に位置することを意味します。従って、応答の変換を変更する必要はありません。 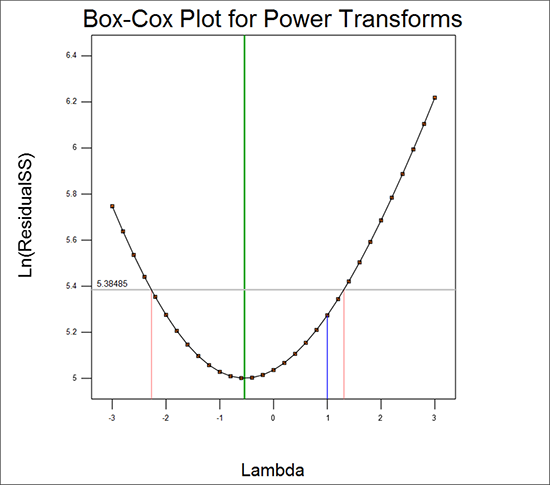 べき乗変換を調べる Box Cox プロット 追記:Box Cox プロットは、ロジット(logit)と逆正弦平方根(arcsine square root)のどちらが適切な変換であるかを選択するのには役立ちません。詳細は、プログラムの Help システムに記述された “Response Transformations” をご覧ください。 |
戻って “Report” タブを選択します。ここで、診断統計の数値が個別にレポート表示されます。問題のある値にはフラグが立てられます。この例では、異常値として検出された値は特にありません。
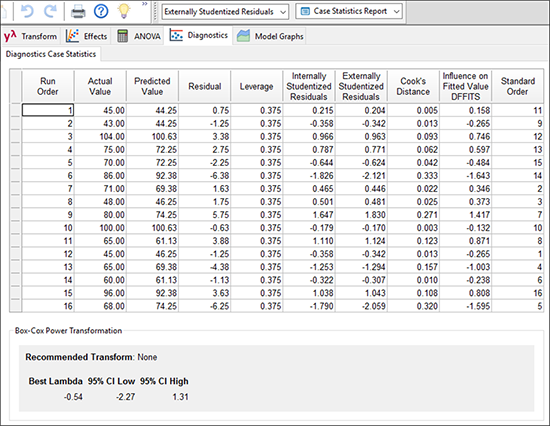
主効果と交互作用の分析
残差分析で何の問題もなければ (この事例では明らかに問題はありませんでした) 、次に考察するのは有意な要因効果となります。
画面上部にある分析ツールバーから、“Model Graphs” タブを選択してください。交互作用 AC のプロットがデフォルトで表示されます(グラフに表示される X 軸がコード表記の単位になっていたら、“Display Options” -> “Process Factors” -> “Actual” を選択して、実測単位に戻しておいてください)。
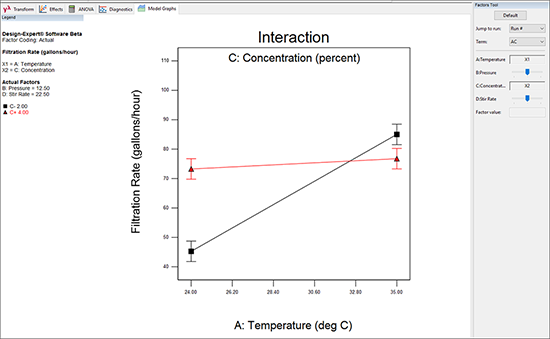
このプロット(およびその他の効果プロット)に表示される “I型” のシンボルはプロットされたポイントの 95% 最小有意差(LSD)区間を示しています。
各ポイントの LSD 区間どうしが互いに重ならない場合(すなわち、仮想の水平線を左から右に引いた場合、LSD バーがその水平線と交差しない、または、重ならない場合)は、ポイントは大きく異なります。
| ※ 一対比較するには 一対比較を使用すると分離の検証を簡単に行うことができます。任意のモデル予測(例えば真ん中の LSDバーの左側にある三角形)をクリックすると一対比較が表示されます。  グラフに追加した一対比較。凡例はどの対が大きく異なるかを示されていることに注意してください 強調表示されたポイントの、平均の予測を通る横線が描かれます。この横線と重なるすべての縦棒は、選択したポイントから大きな差異がないと予測された平均値であることを意味します(例えば、グラフの右側に示された赤い三角形は予測値が A+, C+ であることを示しています) 。凡例には、どの中間点に有意差があるかも一覧表示されます。表示された一対比較が両側で行われた場合でも、表示されるのは区間の半分側のみとなります (分かりやすさが考慮されるため)。 |
グラフの右側にあるポイント(温度の高い部分)間の距離は、グラフの左側にあるポイント(温度の低い部分)の間にある距離よりも小さい点にも注目してください。つまり、ホルムアルデヒドの濃度(C)の効果は、温度(A)の高い水準においては有意性が小さいということです。従って、実験者は、ろ過速度を維持または増大させながら、高温の状態で有害なホルムアルデヒドの量を減らすことができることになります。この組み合わせは、交互作用プロットの右上にある黒い正方形の記号で表されます。
Factors Tool がデフォルトのプロットとともに一緒に開き、画面の右側に固定されます。必要があれば、上部の青の部分をクリックして、好きな位置にマウスをドラッグして移動してください。ツールをクリックして画面の右側にドラッグし、青い影が表示されたら放して、元の位置にロックすることができます。グラフ上にプロットさせたい因子(複数選択可能)を、このツールを使って制御できます。Factors Tool の下部にはプルダウンリストが用意されており、プロットする因子をここから選択することもできます。このリストにはモデルに取り込まれた項のみが含まれます。
| ※ 交互作用に含まれる主効果の選択 Term リストの下矢印をクリックして、項 “A” を選択してください。Graphs Tool では、Interaction から One Factor に選択が移ることに注意してください。 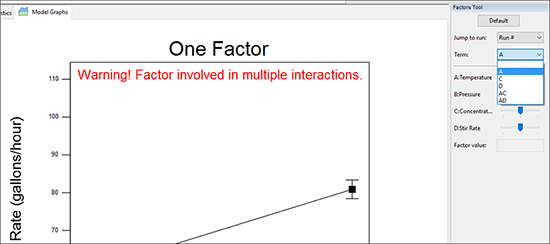 主効果Aに変更(一因子プロット) さらに重要な点は、A(Temperature)プロットの上部に警告が発せられることです。“Factor involved in an interaction.”(交互作用に関係する因子です)とあります。交互作用に関係する因子の主効果プロットからは、誤解を招く情報が発せられるため、これを根拠として実験の結論を導きだそうとしてはいけません。 |
それでは、この段階で執るべき意味のある作業に着手しましょう。Factors Tool に戻って Term リストから別の有意な交互作用 “AD” を選択してください。
Factors Tool 上において、軸(X1 または X2)をまだ割り当てていない因子には、縦の赤いスライドバーが表示されている点に注目してください。これを使って詳細な設定を選択できます。デフォルトのバーの位置は、軸のないこれらの因子の中間の水準にあります。
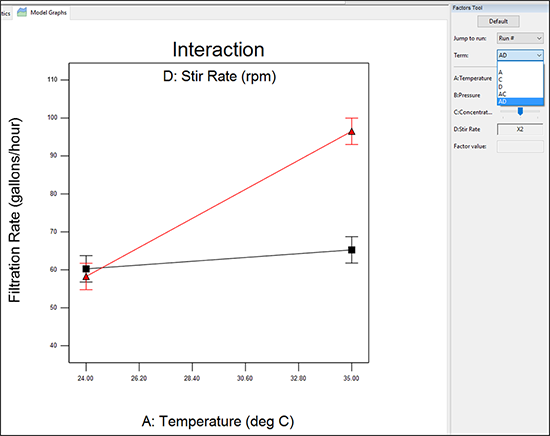
| ※ factor sliders の機能について 固定因子の水準はバーをマウスでドラッグするか、Factors Tool の下側にある数値領域内に変更したい水準を入力することで変更することができます。実際にこれを確認してみましょう。因子 C:Concentration のスライドバーをマウスで掴んで左端に移動してください。交互作用グラフに変化が起きますので注目してください。 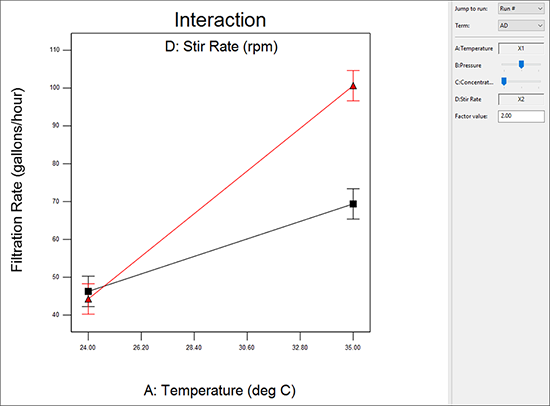 因子Cのスライドバーを低水準(-)の左端に設定した交互作用ADのグラフ 撹拌速度が高いほど(因子 D を表す赤いライン)、非常に高いろ過速度を実現できることが、これで明らかになりました。この高い値のポイントをクリックすると、応答と因子の値に関する詳細情報を得られます。これが最適な結果です。 グラフをデフォルトの濃度 concentration にリセットしましょう。Factors Tool の下側に「3」と入力してください(この操作を有効にするには、因子 C をクリックして選択状態にする必要があります)。Default ボタンをクリックしても、オリジナルの設定に戻すことができます。実際にお試しください。しかし、ホルムアルデヒドの濃度を低くすることは製造工程の問題を解決するこの実験の第一の目標であることを忘れないでください。したがって、因子 C のスライドは必ず左側に戻しておいてください。 |
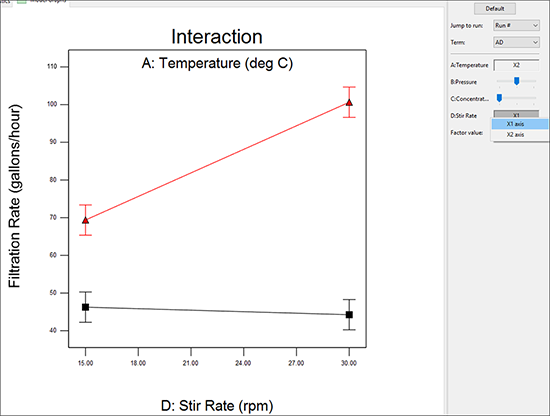
D:Stir Rate の横にあるボックスを右クリックして “X1 axis” に変更してください。交互作用 AD の軸が反転するのを確認できます。
統計的な違いはありませんが、これによって分かりやすくなったと思います。
| ※ テキストの変更について 最後にもう一つ付け加えます。マウスを右クリックすることで少なくとも殆どのグラフに表示されているテキストを編集することができます。例えば、交互作用グラフにおいては、X1 軸のラベルを右クリックします。 次に、“Edit Text” を選択することで、入力フィールドが表示されます。実際にお試しください!   |
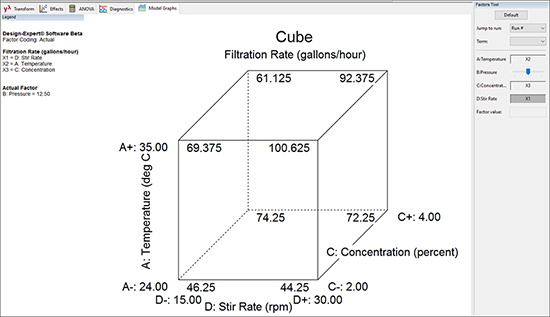
キューブプロットの描画
Graphs Toolbar から “Cube” を選択してください。予測応答(predicted response)が3因子の関数として表示されます。これは有意な効果 A, C, D で作成されたものです。
このプロットは、3つの因子がどのように組み合わさって応答に影響を及ぼすのかを表すものです。表示されているすべての数値は予測された値ですので、作成されるプロットには実測値がなくても構いません。ここで関心のある因子は A、C、D ですので、プログラムはデフォルトでこれら選択します (Factors Tool にある任意の因子を右クリックすることによって、軸を変更することができます) 。
ろ過速度は、A+, D+, C‐ の設定で最大です (右下奥の隅で、予測応答は 100 を超えています) 。これは同時にホルムアルデヒド濃度を低減しようとする所期の目的とも合致します。すばらしい!!
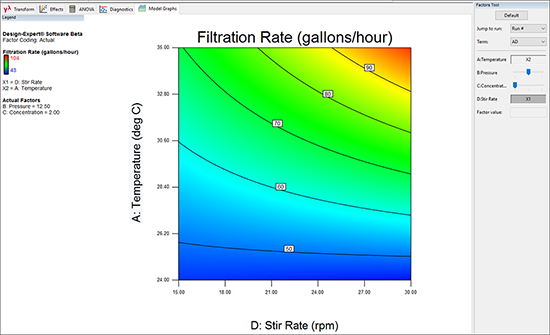
交互作用の等高線図と 3D プロットの作成
交互作用は二次の非線形応答をあらわします。交互作用の等高線図と 3D ビューを実際に見てみると、この非線形性を視覚的に把握するのに役立つかもしれません。
まず初めに、“Contour” を選択して、等高線グラフを作成ください。二つの軸は、A(Temperature)と D(Stir Rate)になっているはずです。もしそうなっていなければ、Factor Tool を右クリックするだけで適切に変更することができます。
画面の色の濃淡を見て驚くユーザーがいるかもしれません – グラデーションは応答の低水準の値を表す青色から始まり、高水準の値を表す黄色で終わります。上記のグラフと同じように表示にするには concentration(C)を低いレベルに設定する必要があります。
| ※ フラグの追加/等高線の変更などについて Design-Expert の等高線プロットは非常にインタラクティブです。例えば、等高線上をクリックするとそれが強調表示されます。これをドラッグすると、別の場所に移動することができます。さらに、グラフ内の任意の場所を右クリックするとオプションが表示され、フラグや等高線を追加したり、Graph preferences の項目を変更したりすることもできます。 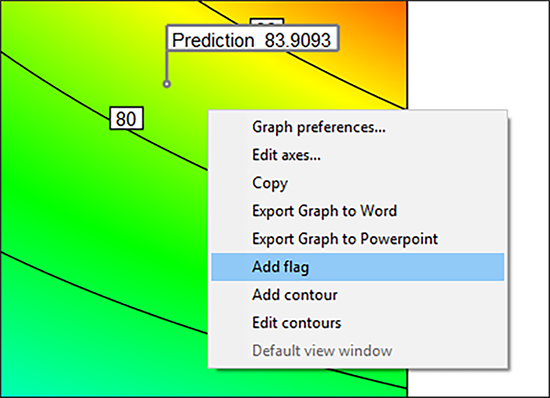 |
次に、この実験から物事がどのように形成されるかを簡単に確認できる、印象的なグラフを作成するために “3D Surface” を選択してください。
グラフ上にカーソルを移動してください。カーソルが手の形状 (![]() ) に変わったら、左クリックして好きなように回転してみてください。
) に変わったら、左クリックして好きなように回転してみてください。
最終段階に進む前に、最初の交互作用を確認しておきましょう。Factors Toolbar にある Term リストから “AC” を選択します。D: Stir Rate 上のサイドバーを右(最高レベル)まで移動して、応答を増やします。
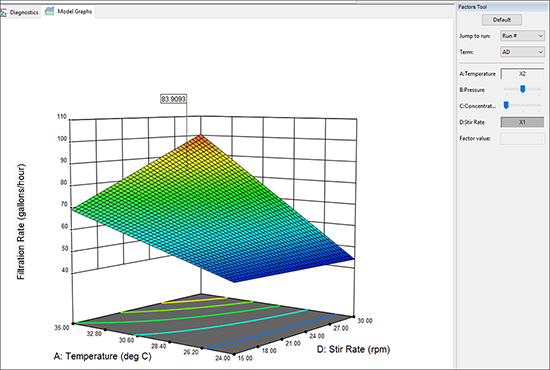
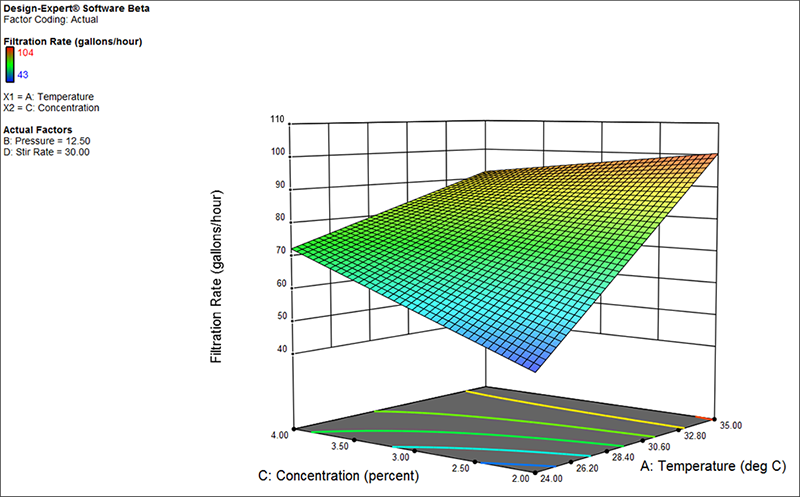 最初の交互作用ADの3Dプロット |
一般的な実験計画で使用するための Design‐Expert に用意された便利なツールは、これでほとんど使い尽くしましたが、最後にもう一つだけ試しておきたいツールがあります。
確認 (Confirmation)
最後に検討する機能は、画面の左下にある Post Analysis ブランチに表示されています “Confirmation” ノードをクリックすると、プロセス因子のあらゆる設定条件に応答予測を作成することができます。次に、“Factors” タブをクリックします。この画面をはじめて立ち上げると、Factors Toolbar パレットにある各因子のポイントはいずれもデフォルトで中央に指定されています。この水準は赤のスライドバーを使って容易に調整することができます。より厳密に指定したい場合は、Sheet ビューで数値入力することも可能です。この事例では、分析結果から判断して以下のように各因子をそれぞれスライドさせることになります:
- A (Temperature) を右側の高水準 (+) にスライドする
- B (Pressure) は、デフォルトの水準の中央のポイントのまま
- C (Concentration) を左側の低水準 (‐) にスライドする
- D (Stir Rate) を右側の高水準 (+) にスライドする
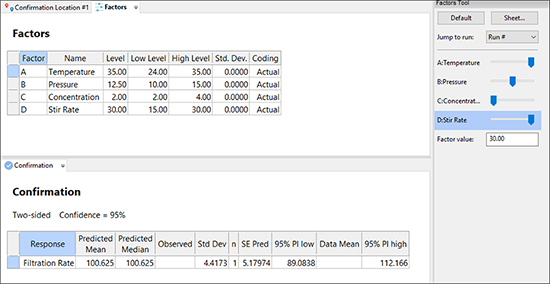
Design-Expert では実験結果から導かれるモデルを使用して、ユーザーがアクセスした時点の平均と試行数 (n) の区間 (PI) を予測します。これにより、ホルムアルデヒドの量を最小限にする、最小のろ過率が分かります。これで目的は達成しました。
| ※ Post Analysis の機能/その他 さらに確実性を向上させるにはサンプルサイズ (n) を増やすのが賢明です。予測区間 (PI) の改善という観点から、nが増加するにつれて応答は減少します。Confirmation タブで、n の値を変更して自分でこれを確認することができます。PI の変化に注目してください-限界値に近づいています。*実験的試行は6回くらいが妥当といえるでしょう。 以下のように、自分の確認試行にログインするための日付入力画面を作成することができます。それから、実結果の平均が計算されます。この値がPIの範囲内に入っている場合は、実験プログラムの次の段階に進むことができます。そうでない場合は注意が必要です。 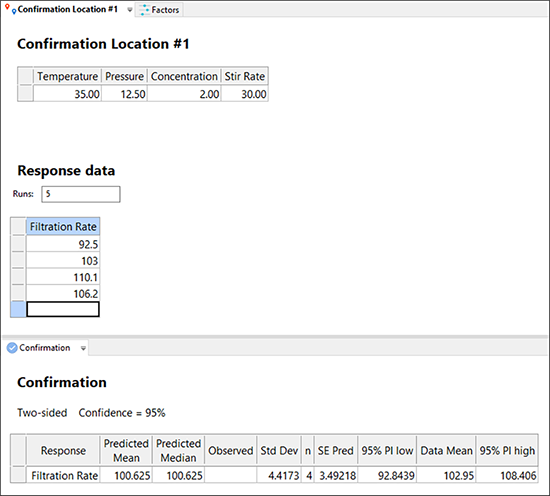 判定結果の入力 *統計的詳細:無限試行の結果として、PI は信頼区間(CI)に向かって収束します。この信頼区間はオリジナルの実験における試行数(N)の関数です。Point Prediction ノードで CI を確認してください。信頼(1-α)でサンプリングされた母集団(P)に含まれるように、計算された許容区間(TI)も確認することができます。デフォルトでは母集団の標本の 99% が、許容区間内に 95% の信頼度で含まれるように設定されています。平均値の 95% で信頼区間は最も狭くなり、単一実測値(所定の Confirmation ノード)の 95% 予測区間でさらに広くなって、母集団の 99% を含む 95%(TI/許容区間)で最も広くなることに注意してください。最も厳密な区間 TI(許容区間)は製造仕様の設定で必要になることが多いですが、大抵の実験者はPI(予測区間)を予測値の管理方法として受けとめています。従って、Confirmation Tool は力強い見方となってくれるでしょう。 |
以上で、複数要因の分析に必要とされる重要な出力結果のすべてに目を通しました。作業内容を保存するために、ここで “File” -> “save” を実行するといいでしょう。ここで作成したモデルが Design‐Expert に保存されます。この出力結果は、必要があればいつでも簡単に再現できます。後から他のファイルと区別しておくために、ファイルに何かコメントを残しておきたい場合もあるでしょう。画面左側にあるツリー構造の左上にある Notes フォルダーノードをクリックして、ここにコメントを記入できることを忘れないで下さい。このファイルを後で開くときは、ここを見てコメントした内容を確認することになります。
6.最終報告書の作成
分析の総仕上げは、最終報告書を作成して印刷することです。まだ済んでいなければ、しかるべきアイコンやボタンをクリックして必要な情報を画面上に戻して、プリントアイコンをクリック(または、“File” -> “Print” コマンドを使用)してください。
グラフを他のアプリケーションにコピーすることもできます:。Ctrl+C を使用するか、以下のようにコピーアイコン を使用してください。
ANOVA 表やその他のレポートについては、まず Select All を実行するか、コピーしたいテキスト範囲を選択してからコピーを行ってください。
※ 結果のエクスポートオプションについて: Design-Expert で表示される、様々な画面の上で右クリックしてみてください。 レポート作成に役立つ他のプログラムへのショートカットが、表示されることがよくあります。 例えば、以下に示すデザインレイアウトのスクリーンショットを見てください(ヒント: すべてのヘッダーとデータをハイライトするには “Select” ボタンをクリックします)。 エクスポートのオプション ここまでやり遂げたら、以降はユーザー自身が実際に色々挑戦して試しながら機能を学んでいくことをお勧めします。 ただし特定の難しい手法の習得にこだわりすぎないでください。スクリーンチップス(Screen Tips)をクリックして参照したり、メインメニューからヘルプの検索機能を有効に活用してください。 |
以上で、要因配置計画の基礎チュートリアルは終了です。必要に応じて、さらに上級のトピックや機能のチュートリアルに進んでください。メニューから “File” -> “Exit” を選択して、Design‐Expert を終了しても構いません。ここで使用したデータをまだ保存していないか、最後に保存したデータに変更が加えられていれば、警告メッセージが表示されます。データや分析結果が保存されたのを確認してから、プログラムを終了するようにしてください。