19.5 一元配置分散分析 (ANOVA)
一元配置分散分析 (One Way Analysis of Variance) は、全ての標本が標準偏差 (分散) の等しい正規分布の母集団から抽出されていることを前提条件とするパラメトリック検定です。
一元配置 (One Way) すなわち1因子の ANOVA を使うのは:
- 2つ以上の異なる実験群の平均値がある単一因子によって影響を受けるか否かを調べたいとき。
- 分散の等しい正規分布の母集団から標本が抽出されているとき。
抽出したデータの母集団に正規性がないことが分かっている場合は、クラスカル=ウォリスの順位に基づく ANOVA 検定 (Kruskal-Wallis ANOVA on Ranks test) を使います。詳しくは、クラスカル=ウォリスの順位に基づく分散分析 をご覧ください。実験群に対する2因子の効果を考慮したい場合は、二元配置分散分析 (Two Way ANOVA) を使います。詳しくは、二元配置分散分析 (ANOVA) をご覧ください。比較する群が2つしかない場合は、t 検定を実行することができます (必要とする結果の種類によって変わります)。2群に対して ANOVA を実行したときの P 値は、対応のない t 検定で得られる P 値と全く同じです。詳しくは、対応のない t 検定 をご覧ください。
| ※ Note:非正規母集団や分散の等しくない母集団に対して ANOVA を実行しようとする場合、お使いの ANOVA オプション設定によっては、SigmaPlot により、そのデータがパラメトリック検定にふさわしいものではないとの警告が表示され、代わりにクラスカル=ウォリスの順位に基づく分散分析 (Kruskal-Wallis ANOVA on Ranks) を実行するよう提案されます。 |
- 一元配置分散分析について
- 一元配置分散分析を実行する
- 一元配置分散分析のデータを配置する
- 一元配置分散分析オプションを設定する
- Options for One Way ANOVA: Assumption Checking
- Options for One Way ANOVA: Results
- Options for One Way ANOVA: Post Hoc Tests
- 一元配置分散分析を実行する
- 一元配置分散分析の多重比較オプション
- 一元配置分散分析の結果を解釈する
- 結果の説明
- 一元配置分散分析のレポートグラフ
- One Way ANOVA レポートのグラフを作成する方法
1. 一元配置分散分析について
一元配置分散分析 (One Way ANOVA) の計画は、実験群が2つ以上あるという点を除けば対応のない t 検定 (unpaired t-test) と同じです。帰無仮説は、「標本を抽出した母集団の間に差はない」です。
2. 一元配置分散分析を実行する
一元配置分散分析 (One Way ANOVA) を実行するには:
- ワークシートに適切なデータを入力または配置します。詳しくは、一元配置分散分析のデータを配置する をご覧ください。
- 必要があれば、One Way ANOVA オプションを設定します。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから以下を選択します:
Compare Many Groups → One Way ANOVA
- 検定を実行します。
- レポートグラフを作成します。詳しくは、一元配置分散分析のレポートグラフ をご覧ください。
3. 一元配置分散分析のデータを配置する
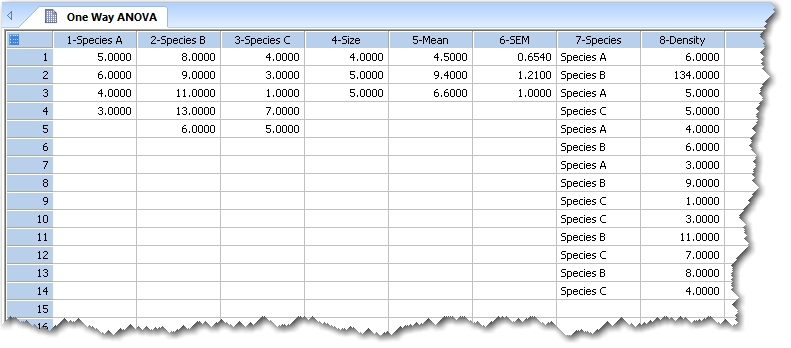
生データ (raw data)、インデックス付きデータ (indexed data)、または、要約統計量 (summary statistics) としてデータを配置します。生データの配置には、32 を上限として群と同じ数の列数が必要になります:それぞれの列に、各群のデータが入ります。インデックス付きデータの配置には、ワークシートの2列を使います。要約統計量の配置には、ワークシートの3列を使います。
One Way ANOVA で有効なデータフォーマットの3例。
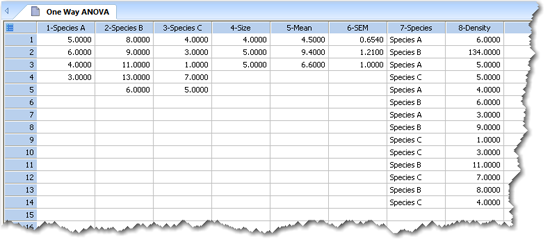 |
列1から3には、各群のデータを列ごとに配置しています。列4、5、6には、サンプルサイズ、平均値、標準偏差を使用した記述統計量を配置しています。列7と8には、列7を因子列とする群別のインデックス付きデータを配置しています。
4. 一元配置分散分析オプションを設定する
- Analysis タブの SigmaStat グループにある Select Test ドロップダウンリストから One Way ANOVA を選択します。
- 現在の検定の Options をクリックします。Options for One Way ANOVA ダイアログに3つのタブが表示されます:
- Assumption Checking:データの正規性と等分散性の基準を緩和または厳格にするには、このパラメータを調整します。詳しくは、Options for One Way ANOVA: Assumption Checking をご覧ください。
- Results:レポートにデータの統計サマリーと信頼区間を表示したり、ワークシート列に残差を保存するかを指定します。詳しくは、Options for One Way ANOVA: Results をご覧ください。
- Post Hoc Test:検出力 (Power)、すなわち、検定の感度の計算し、多重比較を有効にするかを指定します。詳しくは、Options for One Way ANOVA: Post Hoc Tests をご覧ください。
| ※ Tip:検定オプションを変更したあと検定を実行するにあたり、検定の実行前にデータを選択しておきたい場合は、使用するデータをポインターでドラッグします。 |
- 検定を継続するには、Run Test をクリックします。
- 現在の設定内容を適用して、オプションダイアログを閉じるには、OK をクリックします。
4.1 Options for One Way ANOVA: Assumption Checking
正規性 (Normality) の前提条件の検定では、母集団が正規分布に従っているかをチェックします。等分散 (Equal Variance) の前提条件の検定では、各群の平均値の周りのばらつきをチェックします。
Options for One Way ANOVAダイアログボックスの Assumption Checking オプションの表示例。
 |
- Normality の検定:SigmaPlot では、母集団の分布の正規性検定に Shapiro-Wilk または Kolmogorov-Smirnov のいずれかを使用します。
- Equal Variance の検定:SigmaPlot では、群平均のばらつきをチェックすることで等分散性を検定します。
- 正規性および等分散の P 値:P 値により、データが正規分布していないと誤って結論付ける確率が決定されます (P 値は、データが正規分布しているという帰無仮説を誤って棄却してしまうリスクです)。検定によって求められた P 値が、ここで設定した P 値よりも大きければ、検定は採択されます。
正規性と等分散のいずれかまたは両方の要件をより厳密なものにするには、この P 値を大きくします。パラメトリックな統計手法では、仮説の棄却が比較的ロバスト (頑健) に検出されることから、SigmaPlot ではこの値を 0.050 としています。P 値をこれよりも大きくすると (例えば、0.100)、そのデータに正規性がないとの判定が出やすくなります。
正規性の要件を緩和するには、P 値を小さくします。正規性があるという仮説を棄却するための P 値に小さい値しか要求しないということは、前提とする正規分布からデータが外れていても、それが非正規であると判定される前に、それだけ広く受け入れたいとする意思があることを意味します。例えば、P 値を 0.010 とした場合、あるデータを非正規であると判定するには、0.050 の場合と比べてそれだけ大きく正規性を逸脱していなければなりません。
| ※ 制限事項 |
| データの分布が極端な状態にあり、これらの手法では検定できない場合があります。たとえば、ルビーンの中央値検定 (Levene Median test) では、分散の大きさが数次の場合は差の検出ができません。このような条件の場合は、前提条件の自動検定に頼らずにデータを視覚的に調べることで容易に見分けることができます。 |
4.2 Options for One Way ANOVA: Results
- Summary Table:列または群の観測数 (N)、列または群の欠損値の数 (Missing)、列または群の平均値 (Mean)、列または群の標準偏差 (Std Dev)、および、列または群の平均値の標準誤差 (SEM) を表示します。
- Residuals in Column:レポートに残差を表示し、ワークシートの指定列に検定の残差を保存します。列番号を入力するか、ドロップダウンリストから列を選択します。
Options for One Way ANOVA ダイアログボックスに Summary Table および Residuals オプションを表示した例。
 |
4.3 Options for One Way ANOVA: Post Hoc Tests
- Power:検出力 (Power) すなわち検定の感度は、もし群間に真の差がある場合、その差を検定によって検出できる確率です。
- Use Alpha Value:アルファ (α) は、誤って差があると判断しても良しとする確率です。SigmaPlot で提示される値は、α = 0.05 です。この設定は、誤りを許容する確率が 20分の1であることを示します。すなわち、P < 0.05 であれば有意な差があると判断できることになります。
α 値を小さくすると、有意差があると結論付ける要件がそれだけ厳格なものになりますが、差があるにもかかわらずないと結論付けてしまう可能性はそれだけ大きくなります。α 値を大きくすると、差があると結論付ける要件はそれだけ容易になりますが、誤判定をレポートしてしまうリスクが増加することになります。
Options for One Way ANOVA ダイアログボックスに Power および Multiple Comparison オプションを表示した例。
 |
- Multiple Comparison (多重比較):一元配置分散分析 (One-Way ANOVA) では、幾つかの処理群の間に差がないという仮説を検定しますが、どの群に差があるのか、すなわち、群間の差の大きさは分かりません。これらの差を特定するのが多重比較プロシージャです。多重比較の実行については、常に実行するか、または、一元配置分散分析 (One Way ANOVA ) で差が検出されたときだけ実行するかを選択できます。
ANOVA で差を検出するか否かの判定に使用する P 値は、Options ダイアログボックスの Report タブで設定します。一元配置分散分析 (One-Way ANOVA) で求められた P 値が、このボックスで指定した P 値よりも小さければ、群間に差が検出されたことになるので、多重比較が実行されます。
- Always Perform:ANOVA で差が検出されたか否かにかかわらず常に多重比較を実行します。
- Only When ANOVA P Value is Significant:ANOVA で差が検出されたときだけ多重比較を実行します。
- Significance Value for Multiple Comparisons:Significance Value for Multiple Comparisons ドロップダウンリストから .05 または .01 を選択します。この値は、多重比較で処理間に有意差があると誤って結論付ける見込みを決定します。
値が .05 であれば、多重比較で誤って差を検出する可能性が 5% 以下であれば多重比較で差が検出されることになります。
(※ v14 では Σ > Options > Report タブの Test Results で指定します)
| ※ Note:ワークシートでお持ちのデータを選択して検定を実行したあと、多重比較が開始されると、Multiple Comparison Options ダイアログボックスが表示され、多重比較の手法を選ぶよう指示されます。 |
5. 一元配置分散分析を実行する
検定を実行する前にお持ちのデータを選択しておきたい場合は、対象となるデータをマウスポインタでドラッグしておきます。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから次を選択します:
Compare Many Groups → One Way ANOVA
検定ウィザードの Data Format パネルで、データフォーマットを選択します。
Data Format の選択を指定する One Way ANOVA — Data Format ダイアログボックス
 |
- Data Format ドロップダウンリストから該当するデータフォーマットを選択します。詳しくは、群比較検定のデータフォーマット をご覧ください。
- Next をクリックして、検定するデータ列を選択します。この検定を選択する前に列を選択していれば、Selected Columns リストに選択した列が表示されます。
データ列の選択を指示する検定の Select Data パネル
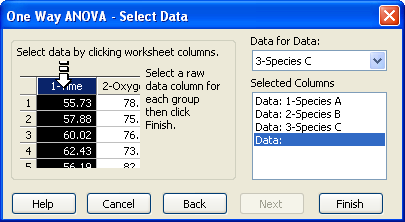 |
- Selected Columns リストに別のワークシート列を割り当てたい場合には、ワークシートで直接その列を選択するか、Data for Data ドロップダウンリストからその列を選択します。
Selected Columns リストの一行目に割り当てられるのは最初に選択した列で、以後同様に列を選択するごとにリストの2行目以降に割り当てられてゆきます。各行には、選択した列のタイトルが表示されます。生データとインデックス付きデータの場合は、ワークシートの2列を選択するよう指示されます。
- 選択した内容を変更するには、リストの割り当てを選択したあと、ワークシートから列を選択しなおします。Selected Columns リストの内容をダブルクリックすることによって、列の割り当てを消去することもできます。
- Finish をクリックすると、選択した列に基づく一元配置分散分析が実行されます。
正規性と等分散性の検定を指定している場合は、SigmaPlot により正規性の検定 (Shapiro-Wilk または Kolmogorov-Smirnov) と等分散性の検定 (Levene Median) が実行されます。
お持ちのデータがいずれの検定にも合格 (Pass) した場合、SigmaPlot により、パラメトリックな t 検定を使用して分析を続行するのがふさわしいことが報告されます。詳しくは、対応のある t 検定をご覧ください。
計算が完了すると、レポートが表示されます。詳しくは、レポートグラフ をご覧ください。
- Finish をクリックすると、一元配置分散分析 (One Way ANOVA) が実行されます。
正規性と等分散性の検定を指定しており、かつ、お持ちのデータがいずれの検定にも不合格 (Fail) になった場合は、SigmaPlot により、ノンパラメトリックな Kruskal-Wallis の順位に基づく分散分析 (Kruskal-Wallis ANOVA on Ranks) を使って分析を続行するのがふさわしいことが報告されます。詳しくは、Kruskal-Wallis Analysis of Variance on Ranks をご覧ください。
P 値が有意のときだけ多重比較を実行するよう選択しており、かつ、P 値が有意でない場合は、この検定の完了後に One Way ANOVA レポートが表示されます。詳しくは、レポートグラフ をご覧ください。
多重比較の P 値が有意である場合、または、多重比較を常に実行するよう選択している場合は、Multiple Comparisons Options ダイアログボックスが表示され、多重比較の手法を選択するよう指示されます。
6. 一元配置分散分析の多重比較オプション
一元配置分散分析 (One Way ANOVA) では、幾つかの処理群の間に差がないという仮説を検定しますが、どの群に差があるのか、すなわち、群間の差の大きさは分かりません。多重比較検定では、実験群間の比較を行うことによってこれらの差を特定します。
P 値が有意のときのみ多重比較の実行するよう選択し、かつ、ANOVA で求められた P 値が指定した P 値以下になった場合、または、Options for One Way ANOVA ダイアログボックスで常に多重比較を実行するよう選択した場合、Multiple Comparison Options ダイアログボックスが表示され、多重比較の検定法を指定するよう指示されます。このダイアログボックスの左上には、ANOVA によって求められた P 値が表示されます。
One Way ANOVA で選択できる多重比較の検定法には以下の7種類があります:
One Way ANOVA で選択できる多重比較には2つのタイプがあります。選択できる比較タイプは、選択した多重比較検定法によって変わります。
- All pairwise 比較は、組み合わせ可能な全ての処理対を比較します。
- ある対照群に対する多重比較 (Versus control) は、単一の対照群に対して全ての実験群を比較します。
全ての処理間の差を調べるには、Tukey と Student-Newman-Keuls 検定が推奨されます。処理数がわずかしかない場合は、より簡便な Bonferroni t-test を選択することもできます。
Dunnett の検定は、実験の処理群と対照群との間の差を調べるのに推奨されます。処理数や観測数がわずかしかない場合は、より簡便な Bonferroni t-test を選択することもできます。
| ※ Note:いずれのケースにおいても、群の数が少ない場合は Bonferroni t-test の感度が最も高くなります。Dunnett’s test は、観測数が6つより少ないときは選択できません。 |
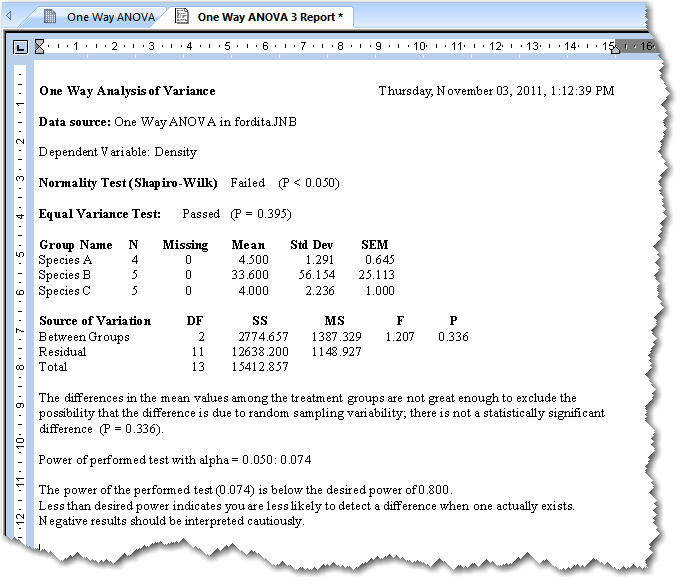
7. 一元配置分散分析の結果を解釈する
One Way ANOVA レポートには、群の変動要因 (source of the variation) をあらわす分散分析表が表示されます。この表に表示される内容は、群の平方和 (sum of squares)、自由度 (degrees of freedom)、平均平方 (mean squares)、および、F 統計量とそれに対応する P 値です。レポートに表示されるデータの統計的サマリー表とその他の結果は、Options for One Way ANOVA ダイアログボックスで表示非表示を指定することができます。
また、多重比較の表を作成することも可能です。多重比較の結果についても、Options for One Way ANOVA ダイアログボックスで指定します。多重比較で使用される検定法は、Multiple Comparison Options ダイアログボックスで指定したものです。
7.1 結果の説明
数値による結果に加えて、拡張された結果の説明が表示されることがあります。この説明テキストは、Options ダイアログボックスで有効または無効にすることができます。詳しくは、レポートグラフ をご覧ください。
- Normality Test:Normality Test の結果には、そのデータが正規母集団から抽出されたものであるという前提条件の検定に合格したか否か (Passed または Failed)、および、この検定で計算された P 値が表示されます。全てのパラメトリック検定では、ソースとなる母集団が正規分布に従っている必要があります。この結果は、 Options for One Way ANOVA ダイアログボックスで設定します。
- Equal Variance Test:等分散性の検定 (Equal Variance test) の結果には、そのデータが同じばらつきを持つ母集団から抽出されたものであるという前提条件の検定に合格したか否か (Passed または Failed)、および、この検定で計算された P 値が表示されます。全てのパラメトリック検定では、ソースとなる母集団の分散が等しいものである必要があります。ここで表示される結果は、Options for One Way ANOVA ダイアログボックスで設定します。
- Summary Table:Options for One Way ANOVA ダイアログボックスでこのオプションを有効にすると、サンプルサイズ N、欠損値の数、平均値、標準偏差、平均値と標準偏差の差、および、標準誤差 (SEM) を一覧にしたサマリーテーブルが表示されます。
- N (Size):該当する列または群の観測値の数です。
- Missing:該当する列または群の欠損値の数です。
- Mean:列の平均値です。観測値が正規分布に従う場合、平均値は分布の中心になります。
- 標準偏差 (Std Dev):ばらつきの尺度です。観測値が正規分布に従う場合、平均値の上下1標準偏差分の間に約3分の2が収まり、平均値の上下2標準偏差分の間に観測値の約 95% が収まります。
- 平均値の標準誤差 (SEM):標本を元に算出した平均値から真の母平均を近似するときの目安となる尺度です。
- Power (検出力):Options for One Way ANOVA ダイアログボックスでこのオプションを無効にしていない限り、実行される検定の検出力が表示されます。
One Way ANOVA の検出力 (Power)、すなわち感度は、群間に真の差がある場合、その検定で群間の差を検出できる確率です。検出力が 1 に近づくほど、その検定の感度は高くなります。
ANOVA の検出力は、サンプルサイズ、比較する群の数、誤って差があるとレポートする可能性、すなわち、α (alpha)、観測される群の平均値の差、および、観測される標本の標準偏差によって影響を受けます。
- アルファ:アルファ (α) は、誤って差があると結論付けすることが許容される確率です。この誤りを、第一種の誤り (Type I error) と呼ぶこともあります (第一種の誤りは、仮説が真であるにもかかわらずそれを価値がないとして棄却するときです)。
アルファ (α) の値は、Options for One Way ANOVA ダイアログボックスで設定します。α = 0.05 という値は、許容される誤りが 20分の1であること、すなわち、P < 0.05 であれば有意差があると結論付けることを示します。 α の値を小さくするほど、有意差があるとの結論付けに至る要件はそれだけ厳格になりますが、その反面、差があるにもかかわらず差がないと結論付けてしまう可能性は高くなります (第二種の誤り:Type II error)。α の値を大きくすれば、差があるという結論付けは容易になりますが、その反面、差があると誤って判断してしまうリスクは高くなります。
ANOVA 表:一元配置分散分析の結果が ANOVA 表に一覧表示されます。
- DF (Degrees of Freedom):自由度 (Degrees of freedom) は、ANOVA の感度に影響を及ぼす群とサンプルサイズの数をあらわします。
- 群間 (between groups) の自由度は、群数の尺度です。
- 群内 (within groups) の自由度 (誤差 (error) または残差 (residual) 自由度とも言う) は、群の数を調整したサンプルサイズ全体の尺度です。
- 全体 (Total) の自由度は、サンプルサイズ全体の尺度です。
- SS (Sum of Squares):平方和 (sum of squares) は、ANOVA データ表における各要素に関するばらつきの尺度です。
- 群間の平方和は、標本群の平均差のばらつきの尺度です。
- 群内の平方和 (誤差 (error) または残差 (residual) 平方和とも言う) は、個々の標本すべてに内在するばらつきの尺度です。
- 全体の平方和は、総平均 (全ての観測値の平均) に関する観測値の全体のばらつきの尺度です。
- MS (Mean Squares):平均平方 (mean square) では、母分散の推定量が2つ出力されます。これらの分散推定量の比較が分散分析の基礎となります。
群間の平均平方は次式であらわされます:
群内の平均平方 (誤差 (error) または残差 (residual) 平均平方とも言う) は次式であらわされます:
- F 統計量:F 検定統計量は、次の比であらわされます:
F 比が 1 に近い場合、群間に有意な差はないと結論付けることができます (例えば、対象のデータ群は、すべての標本は同一母集団から抽出されているという帰無仮説と一致する)。
F が大きな数の場合、標本内に異なる母集団から抽出されたものが少なくとも1はつあると結論付けることができます (例えば、母集団において期待されるランダム変動よりもそのばらつきが大きい)。具体的にどの群が異なっているかを調べるには、多重比較の結果を調べます。
- P Value (P 値):P 値 (P value) は、2群の間に真の差があると誤って結論付けてしまう確率です (例えば、t に基づいて帰無仮説を誤って棄却する、すなわち第一種の誤り (Type I error) を犯す確率)。P 値が小さいほど、異なる母集団から標本が抽出されている確率は大きくなります。伝統的には、P < 0.05 の場合は、有意差があると結論付けることができます。
多重比較:多重比較 (multiple comparisons) を実行するよう選択している場合は、各群の対の比較表が表示されます。多重比較プロシージャを有効にするには、Options for One Way ANOVA ダイアログボックスを使います。多重比較プロシージャーで使用する検定は、Multiple Comparison Options ダイアログボックスで選択します。
ANOVA の結果からは、2つ以上の群に差があるかどうかまでしか分からないため、具体的にどの処理が異なっているかを判断するには、多重比較の結果を使用します。多重比較の結果の特定のタイプは、使用する比較検定法、および、比較の仕方、すなわち、全ての組み合わせ (all pairwise) か、対照群との比較 (versus a control) かによって異なります。
- 全ての対の組み合わせ (All pairwise comparison) の結果には、組み合わせ可能な全ての群の対の一覧が表示されます。全ての対の組み合わせには、Tukey, Student-Newman-Keuls, Fisher LSD, Duncan’s test および Bonferroni t-test があります。
- 単一の対照群との比較では、選択した対照群 (control group) との比較しか表示されません。対照群は実際に行う多重比較プロシージャで指定します。対照群との比較検定には、Bonferroni t-test および Dunnett’s, Fishers LSD, および Duncan’s tests があります。
パラメトリックな多重比較プロシージャの結果の導出に関する詳細については、統計学の参考書をご覧ください。
- Bonferroni t-test の結果:Bonferroni t-test には、各群の対の平均値の差が一覧で表示され、各対の t 値が計算され、その比較について P < 0.05 であるか否かが表示されます。Bonferroni t-test は、全ての群の比較にも、対照群との比較にも利用できます。
t 値が大きいものであれば、比較した2群の差は統計的に有意であると結論付けることができます。
比較した P 値が 0.05 より小さい場合は、誤って有意差があると結論付けてしまう可能性は 5% よりも小さくなります。この値が 0.05 より大きければ、確信を持って有意差があると結論付けることはできません。
この平均値の差が2群の間の差の大きさの尺度となります。
- Tukey, Student-Newman-Keuls, Fisher LSD, Duncan’s, および Dunnett’s Test の結果:Tukey, Student-Newman-Keuls (SNK), Fisher LSD, および Duncan’s tests は、いずれも群の全ての対の組み合わせを比較するものです。これに対して、Tukey Fisher LSD, and Duncan’s は、対照群とそれ以外の群との比較に使用するものですので、このタイプの比較では推奨されません。
対照群とその他の全ての群とを比較できるのは Dunnett’s test のみです。いずれの検定も、q 検定統計量を計算し、その対比較で P < 0.05 または < 0.01 であるか否かを表示します。
q 値が大きいものであれば、比較した2群の間の差は統計的に有意であると結論付けることができます。
比較した P 値が 0.05 より小さい場合は、誤って有意差があると結論付けてしまう可能性は 5% よりも小さくなります。この値が 0.05 より大きければ、確信を持って有意差があると結論付けることはできません。
Difference of the Means (平均値の差) が2群の間の差の大きさの尺度となります。
p は、q の算出に使用するパラメータです。p が大きければ、有意差を示すのにそれだけ大きな q が要求されます。p は、比較する群平均の順位に関する差の指標です。群平均には大きいものから小さい順にそれぞれ順位を付け、比較における平均値の数の隔たりが p になります。例えば、比較する平均値が4つある場合、最大と最小を比較すると p=4 となり、二番目に小さなものと最小のものを比較すると p=2 になります。Tukey test の場合、p は常に群の総数と等しくなります。
ある群が他の群と比べて有意差がないことが分かった場合、差のない2群の順位 p の間にある順位 p を持つ全ての群についても、有意差がないとみなされますので、これらの比較については DNT (Do Not Test) という結果が表示されます。
8 一元配置分散分析のレポートグラフ
One Way ANOVA の結果を使用して以下を含む最大5つのグラフを作成できます:
- 列平均の棒グラフ (Bar chart of the column means):One Way ANOVA の棒グラフでは、標準偏差をあらわすエラーバーと共に各群の平均値が垂直の棒としてプロットされます。詳しくは、Bar Charts of the Column Means をご覧ください。
- 列平均のエラーバー付き散布図 (Scatter plot with error bars of the column means):One Way ANOVA の散布図では、各群の平均値が1つの点としてプロットされ、それぞれの点には標準偏差をあらわすエラーバーが付けられます。詳しくは、Scatter Plot をご覧ください。
- 残差のヒストグラム (Histogram of the residuals):One Way ANOVA のヒストグラムでは、指定した範囲の生の残差が定義した間隔セットを使用してプロットされます。詳しくは、Histogram of Residuals をご覧ください。
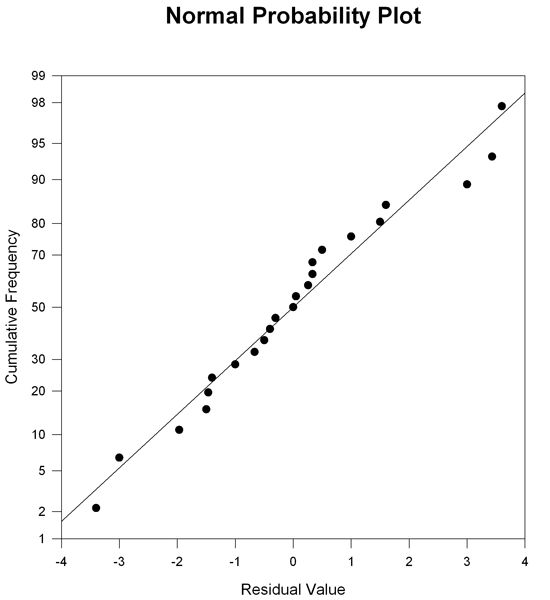
- 残差の正規確率プロット (Normal probability plot of the residuals):One Way ANOVA の確率プロットでは、生の残差の度数がプロットされます。詳しくは、Normal Probability Plot をご覧ください。
- 多重比較グラフ (Multiple comparison graphs):One Way ANOVA の多重比較グラフでは、ある重要な因子の水準間の有意差がプロットされます。詳しくは、Multiple Comparison Graphs をご覧ください。
8.1 One Way ANOVA レポートのグラフを作成する方法
- One Way ANOVA test レポートを選択します。
- Report タブをクリックします。
- Results Graphs グループにある Create Result Graph をクリックします。
Create Result Graph ダイアログボックスが表示され、その中に One Way ANOVA の結果で利用できるグラフのタイプが表示されます。
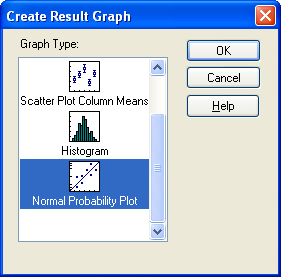
- Graph Type リストの中から作成したいグラフタイプを選択して OK をクリックするか、リスト内のグラフをダブルクリックします。
選択したグラフがグラフウィンドウに表示されます。詳しくは、レポートグラフ をご覧ください。