19.8 クラスカル=ウォリスの順位に基づく分散分析
クラスカル=ウォリスの順位に基づく分散分析 (Kruskal-Wallis Analysis of Variance on Ranks) を使うのは:
- 異なる3つ以上の実験群が単一の因子によって影響を受けるかどうかを調べたいとき。
- 標本が正規性のない母集団から抽出されているか、または、それらの分散が等しくないとき。
お持ちのデータが分散の等しい正規母集団から抽出されていることが既知の場合は、一元配置分散分析 (One Way ANOVA) を使います。詳しくは、一元配置分散分析 (ANOVA) をご覧ください。比較する群が2つしかない場合は、マン=ホイトニーの順位和検定を実行します。詳しくは、マン=ホイトニーの順位和検定をご覧ください。非正規母集団に対する2因子または3因子の検定法はありませんが、お持ちのデータを変換することでパラメトリック検定の前提条件にあてはめることはできます。
| ※ Tip:Options for ANOVA on Ranks ダイアログボックスで正規性の検定を実行するよう選択している場合、正規母集団に対して順位に基づく分散分析を実行すると SigmaPlot によりそのデータがパラメトリック検定に適合していることが告知され、一元配置分散分析をその代わりに実行するよう提案されます。詳しくは、一元配置分散分析 (ANOVA) をご覧ください。 |
- クラスカル=ウォリスの順位に基づく分散分析について
- 順位に基づく分散分析を実行する
- 順位に基づく分散分析のデータを配置する
- 順位に基づく分散分析オプションを設定する
- Options for ANOVA on Ranks: Assumption Checking
- Options for ANOVA on Ranks: Results
- Options for ANOVA on Ranks: Post Hoc Tests
- 順位に基づく分散分析を実行する
- 順位に基づく分散分析の多重比較オプション
- 順位に基づく分散分析の結果を解釈する
- 結果の説明
- 順位に関する分散分析のレポートグラフ
- ANOVA on Ranks のグラフを作成する方法
1. クラスカル=ウォリスの順位に基づく分散分析について
クラスカル=ウォリスの順位に基づく分散分析 (Kruskal-Wallis Analysis of Variance on Ranks) では、それぞれが異なる処理を受ける複数の実験群を比較します。この計画は、実験群が2つより多いという点を除けば基本的にマン=ホイトニーの順位和検定と同じです。詳しくは、マン=ホイトニーの順位和検定をご覧ください。2群に対して順位に基づく分散分析 (ANOVA on Ranks) を実行しようとすると、順位和検定をその代わりに実行するよう SigmaPlot から提案されます。詳しくは、マン=ホイトニーの順位和検定 をご覧ください。
検定する帰無仮説は「群間の値の分布に差はない」です。
クラスカル=ウォリスの順位に基づく分散分析は、全ての標本が分散の等しい正規分布に従う母集団から抽出されているという前提条件を必要としないノンパラメトリック検定です。
2. 順位に基づく分散分析を実行する
順位に基づく分散分析 (ANOVA on Ranks) を実行するには:
- ワークシートに適切なデータを入力または配置します。詳しくは、順位に基づく分散分析のデータを配置する をご覧ください。
- 必要があれば、ANOVA on Ranks オプションを設定します。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから以下を選択します:
Compare Many Groups → ANOVA on Ranks
- 検定を実行します。
- レポートグラフを作成します。詳しくは、順位に基づく分散分析のレポートグラフ をご覧ください。
3. 順位に基づく分散分析のデータを配置する
検定するデータのフォーマットは、生データもしくはインデックス付きデータになります。生データの場合は、64 を上限として群の数と同じ数の列に配置します。列ごとに1つの群データが入ります。インデックス付きデータの場合は、少なくとも3つの処理をワークシートの2列に配置します。処理が3つより少ない場合は、順位和検定 (Rank Sum Test) を使います。詳しくは、マン=ホイトニーの順位和検定をご覧ください。
順位に基づく分散分析で有効なデータフォーマットの2つの例
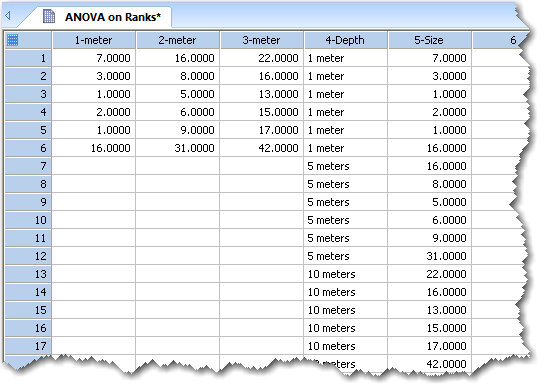 |
列1から3は、生データを配置したものです。列4と5は、列4を因子列、列5をデータ列とするインデックス付きデータを配置したものです。
4. 順位に基づく分散分析オプションを設定する
ANOVA on Ranks のオプションを使用するのは:
- 検定の各種パラメータの調整。データの正規性と等分散性の基準を緩和または厳格にすることができます。
- 多重比較検定を有効にするとき。
- サマリーテーブルを表示するとき。
ANOVA on Ranks オプションを変更するには:
- Analysis タブの SigmaStat グループにある Select Test ドロップダウンリストから ANOVA on Ranks をクリックします。
- Current Test Options オプションをクリックします。
Options for ANOVA on Ranks
ダイアログに以下の3つのタブが表示されます:
- Assumption Checking:データの正規性と等分散性の基準を緩和または厳格にするには、このパラメータを調整します。詳しくは、Options for ANOVA on Ranks: Assumption Checking をご覧ください。
- Results:レポートにデータの統計サマリーと信頼区間を表示したり、ワークシート列に残差を保存するかを指定します。詳しくは、Options for ANOVA on Ranks: Results をご覧ください。
- Post Hoc Tests:検出力 (Power)、すなわち、検定の感度を計算するかを指定します。詳しくは、Options for ANOVA on Ranks: Post Hoc Tests をご覧ください。
- 検定を継続するには、Run Test をクリックします。
- 現在の設定内容を適用するには、OK をクリックします。
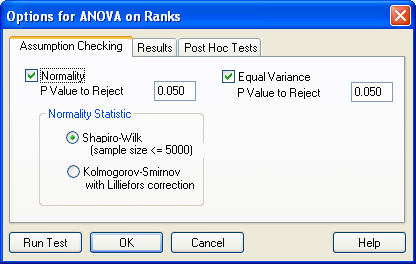
4.1 Options for ANOVA on Ranks: Assumption Checking
Options ダイアログボックスの Assumption Checking タブを選択すると、Normality (正規性) と Equal Variance (等分散性) に関するオプションが表示されます。正規性 (Normality) の前提条件の検定では、母集団が正規分布に従っているかをチェックします。等分散 (Equal Variance) の前提条件の検定では、各群の平均値の周りのばらつきをチェックします。
- Normality の検定:SigmaPlot では、母集団の分布の正規性検定に Shapiro-Wilk または Kolmogorov-Smirnov のいずれかを使用します。
- Equal Variance の検定:SigmaPlot では、群平均のばらつきをチェックすることで等分散性を検定します。
- 正規性および等分散の P 値:P Value to Reject ボックスに該当する P 値を入力します。P 値により、データが正規分布していないと誤って結論付ける確率が決定されます (P 値は、データが正規分布しているという帰無仮説を誤って棄却してしまうリスクです)。検定によって求められた P 値が、ここで設定した P 値よりも大きければ、検定は採択 (Pass) されます。
正規性と等分散のいずれか又は両方の要件をより厳密なものにするには、この P 値を大きくします。パラメトリックな統計手法では、仮説の棄却が比較的ロバスト (頑健) に検出されることから、SigmaPlot ではこの値を 0.050 としています。P 値をこれよりも大きくすると (例えば、0.100)、そのデータに正規性がないとの判定が出やすくなります。
正規性の要件を緩和するには、P 値を小さくします。正規性があるという仮説を棄却するための P 値に小さい値しか要求しないということは、前提とする正規分布からデータが外れていても、それが非正規であると判定される前に、それだけ広く受け入れたいとする意思があることを意味します。例えば、P 値を 0.050 とした場合、あるデータを非正規であると判定するには、0.100 の場合と比べてそれだけ大きく正規性を逸脱していなければなりません。
| ※ Note:データの分布が極端な状態にあり、これらの手法では検定できない場合があります。たとえば、ルビーンの中央値検定 (Levene Median test) では、分散の大きさが数次の場合は差の検出ができません。このような条件の場合は、前提条件の自動検定に頼らずにデータを視覚的に調べることで容易に見分けることができます。 |
4.2 Options for ANOVA on Ranks: Results
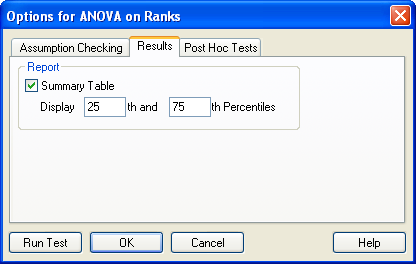
順位に基づく分散分析の Summary Table では、中央値 (Median)、パーセンタイル、および、サンプルサイズ N がレポートに表示されます。必要があれば、ボックスの内容を編集してパーセンタイルの値を変更します。提示されるパーセンタイルは、25% および 75% パーセンタイルです。
Summary Table オプションを表示した Options for ANOVA on Ranks
ダイアログボックスの例
 |
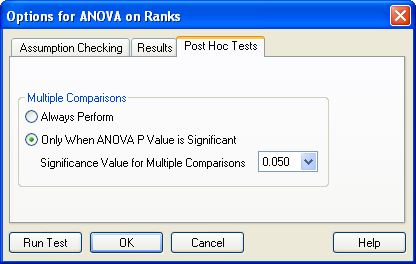
4.3 Options for ANOVA on Ranks: Post Hoc Tests
Options ダイアログボックスの Post Hoc Test タブをクリックすると、多重比較オプションが表示されます。順位に基づく分散分析 (ANOVA on Ranks) では、幾つかの処理群の間に差がないという仮説を検定しますが、どの群に差があるのか、すなわち、群間の差の大きさは分かりません。多重比較は、二元配置分散分析で差が検出されたときに、これらの差を特定するのに使います。
ANOVA で差を検出するか否かの判定に使用する P 値は、Options ダイアログボックスの Report タブで設定します。順位に基づく分散分析 (ANOVA on Ranks) で求められた P 値が、このボックスで指定した P 値よりも小さければ、群間に差が検出されたことになるので、多重比較が実行されます。
- Multiple Comparison (多重比較):多重比較は、常に実行するか、または、ANOVA on Ranks で差が検出されたときだけ実行するかを選択できます。
- Always Perform:ANOVA で差が検出されたか否かにかかわらず常に多重比較を実行します。
- Only When ANOVA P Value is Significant:ANOVA で差が検出されたときだけ多重比較を実行します。
- Significance Value for Multiple Comparisons:ドロップダウンリストから値を選択します。この値は、多重比較で処理間に有意差があると誤って結論付ける見込みを決定します。値が .05 であれば、多重比較で誤って差を検出する可能性が 5% 以下であれば多重比較で差が検出されることになります。
| ※ Note:ワークシートからデータを選択して検定を実行したあと、多重比較が開始されると、Multiple Comparison Options ダイアログボックスが表示され、多重比較の手法を選ぶよう指示されます。詳しくは、順位に基づく分散分析の多重比較オプション をご覧ください。 |
| ※ Attention:不確実性からの影響を受けない統計的検定はありませんので、場合によっては多重比較プロシージャによる群分けが判然としないこともあります。 |
5. 順位に基づく分散分析を実行する
検定を実行する前にお持ちのデータを選択しておきたい場合は、対象となるデータをマウスポインタでドラッグしておきます。
ANOVA on Ranks を実行するには:
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから次を選択します:
Compare Many Groups → ANOVA on Ranks
ANOVA on Ranks — Data Format パネルが表示され、データフォーマットを選択するよう指示されます。
検定ウィザードの ANOVA on Ranks — Data Format パネルでデータフォーマットを選択するよう指示されます。
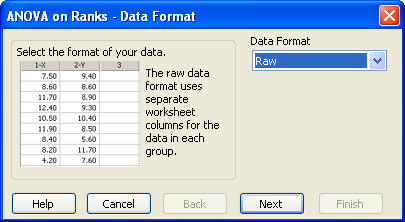 |
- Data Format ドロップダウンリストから適切なデータフォーマットを選択します。詳しくは、群比較検定のデータフォーマット をご覧ください。
- Next をクリックして、この検定のデータ列を選択します。検定を選択する前に列を選択していれば、Selected Columns リストに選択した列が表示されます。
- Selected Columns リストに別のワークシート列を割り当てたい場合には、ワークシートで直接その列を選択するか、Data for Data ドロップダウンリストからその列を選択します。
Selected Columns リストの一行目に割り当てられるのは最初に選択した列で、以後同様に列を選択するごとにリストの2行目以降に割り当てられてゆきます。
検定ウィザードの Select Data でデータ列を選択するよう指示されます。
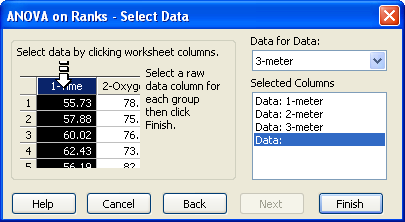 |
各行には、選択した列の番号またはタイトルが表示されます。生データの場合は、ワークシートの少なくとも2列、最大64列まで、インデックス付きデータの場合は、少なくとも3つの処理を含む2列を選択するよう指示されます。処理が3つより少ない場合は、順位和検定 (Rank Sum Test) を使用するようメッセージが表示されます。詳しくは、マン=ホイトニーの順位和検定をご覧ください。
- 選択した内容を変更するには、リストの割り当てを選択したあと、ワークシートから列を選択しなおします。Selected Columns リストの内容をダブルクリックすることによって、列の割り当てを消去することもできます。
- 正規性と等分散性を検定するよう選択しており、 お持ちのデータがどちらの検定にも合格しなかった (failed) 場合、そのまま検定を続けるか、または、データを変換したあと、その変換したデータに対して ANOVA を実行するかを選択できます。
- 多重比較の P 値が有意である場合、または、常に多重比較を実行するよう選択している場合、Multiple Comparisons Options ダイアログボックスが表示され、多重比較の手法を選択するよう指示されます。詳しくは、順位に基づく分散分析の多重比較オプション をご覧ください。
- Finish をクリックすると、ANOVA on Ranks が実行されます。 次の場合は、ANOVA on Ranks レポートが表示されます:
- 正規性と等分散性を検定するよう選択し、お持ちのデータがどちらの検定にも合格 (Pass) した場合。
- 多重比較を実行しないように選択している場合、または、P 値が有意なときだけ多重比較を実行するよう選択しており、P 値が有意でない場合。詳しくは、順位に基づく分散分析の結果を解釈する をご覧ください。
6. 順位に基づく分散分析の多重比較オプション
Options for ANOVA on Ranks ダイアログボックスで、多重比較を実行するよう選択しており、2つの因子のいずれか、または、2因子の間の交互作用について、ANOVA で算出された P 値が、多重比較のトリガーとなる P 値と等しいか小さかった場合、Multiple Comparison Options ダイアログボックスが表示され、多重比較の検定法を指定するよう指示されます。
このダイアログボックスには、2つの実験因子の P 値と因子間の交互作用の P 値が表示されます。選択できるオプションは、Options ダイアログボックスで指定した値と同じか小さい P 値を持つもののみです。選択されたオプションをクリックすることで、その因子の多重比較検定を無効にすることができます。いずれの因子も選択していなければ、多重比較の結果はレポートされません。
ANOVA on Ranks で選択できる多重比較の検定法には以下の4種類があります:
ANOVA on Ranks で選択できる多重比較には2つのタイプがあります。選択できる比較タイプは、選択した多重比較検定法によって変わります。
- Versus Control (対照群との多重比較) は、各因子の全ての組み合わせ (例えば、データテーブルの全てのセル) の差を検定します。
- All pairwise 比較は、各処理間の差や2因子内の水準の差 (例えば、データテーブルの異なる行と列どうし) をそれぞれ個別に検定します。
7. 順位に基づく分散分析の結果を解釈する
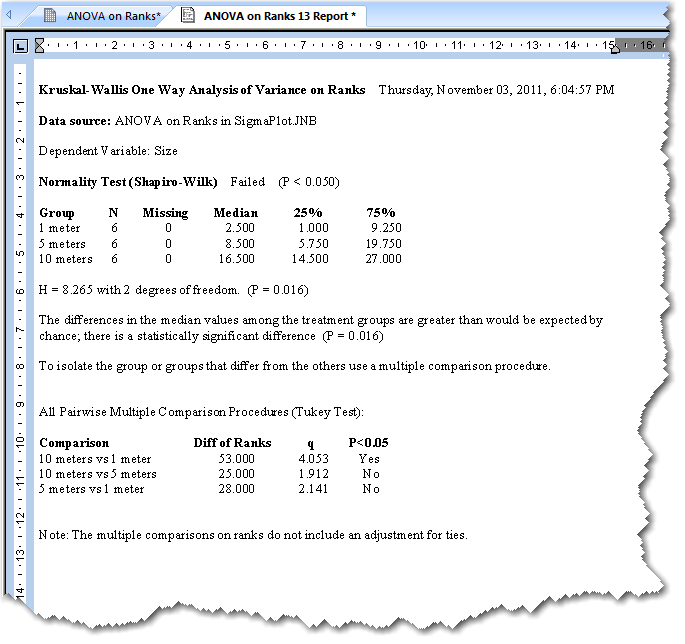
ANOVA on Ranks レポートには、H 統計量 (同順位の結び ties を補正したもの) と、それに対応する H の P 値が表示されます。レポートに表示されるその他の結果は、Options for ANOVA on Ranks ダイアログボックスで有効または無効にすることができます。
ANOVA on Ranks の結果のレポート
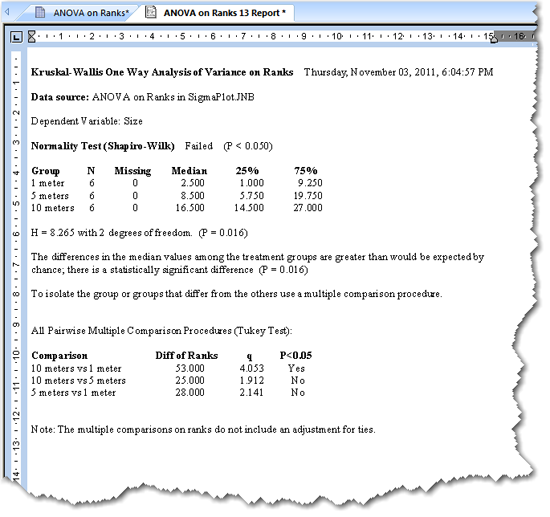 |
7.1 結果の説明
数値による結果に加えて、拡張された結果の説明が表示されることがあります。この説明テキストは、Options ダイアログボックスで有効または無効にすることができます。
表示される小数点以下の桁数についても Options ダイアログボックスで指定できます。
- 正規性の検定:正規性の検定 (Normality test) の結果には、正規母集団から抽出されたデータであるという前提条件の検定にお持ちのデータが合格したか (passed) 不合格したか (failed) 、および、この検定で算出された P 値が表示されます。ノンパラメトリックな検定では元になる母集団の正規分布が前提条件とされませんので、ノンパラメトリックのプロシージャーでは、この検定は不合格 (fail) になります。
この結果は、Options for ANOVA on Ranks ダイアログボックスで正規性の検定を無効にしていない限り表示されます。
- 等分散性の検定:等分散性の検定 (Equal Variance test) の結果には、同じ分散を持つ母集団から標本が抽出されているという前提条件の検定にお持ちのデータが合格したか (passed) 不合格したか (failed) 、および、この検定で算出された P 値が表示されます。ノンパラメトリックな検定では、元になる母集団の等分散性は前提条件とされません。
この結果は、Options for ANOVA on Ranks ダイアログボックスで等分散性の検定を無効にしていない限り表示されます。
- サマリーテーブル:Options for ANOVA on Ranks ダイアログボックスでこのオプションを選択している場合、中央値 (medians) と、Options ダイアログボックスで定義したパーセンタイル、および、サンプルサイズ N を一覧とするサマリーテーブルが作成されます。
- N (サイズ):該当する列または群の観測値の数です。
- Missing:該当する列または群の欠損値の数です。
- Median:全ての観測値を小さい順に並べて、観測値の小さい方の半数の中からの最大値を選択することで算出する観測値の「中央」です。観測した中央値では、その観測値よりも大きい観測数と小さい観測数が同じになります。
- パーセンタイル:観測値の上側と下側の両端を定義した2つのパーセンタイル点です。
- H 統計量:ANOVA on Ranks の検定統計量 H は、処理群とは無関係にすべての観測データを小さいものから大きいものの順に順位を付けることによって算出するものです。処理群ごとに順位の平均値を計算しそれを比較します。
サンプルサイズが大きい場合、この値をカイ二乗分布 (可能な全ての H 分布の推定量) と比較して、この H の発生率を決定します。サンプルサイズが小さい場合は、実際の H 分布を使用します。
H が小さければ、処理群それぞれを観測した平均順位は、ほとんど同じです。そのデータは、「全ての標本は同一の母集団から抽出されたものである」という帰無仮説から成るものである (例えば、処理効果なし) と結論づけることができます。
H が大きければ、平均順位のばらつきは、母集団に期待されるランダムなばらつきよりも大きくなりますので、「標本は異なる母集団から抽出されたものである」(例えば、群間の差は統計的に有意である)と結論付けることができます。
- P 値:P 値は、群間に真の差があると誤って結論付けてしまう確率です (例えば、H 統計量に基づいて帰無仮説を誤って棄却する、すなわち、第1種の誤り (Type I error) を犯してしまう確率です) 。P 値が小さいほど、異なる母集団から標本が抽出されている確率は大きくなります。伝統的には、P < 0.05 の場合は、有意差があると結論付けることができます。
- 多重比較:群間に差が見つかった場合、多重比較を実行するよう要求あるいは選択していれば、群同士の対を比較するテーブルが表示されます。多重比較プロシージャーは、Options for ANOVA on Ranks ダイアログボックスで有効にします。多重比較プロシージャーで使用する検定は、Multiple Comparison Options ダイアログボックスで選択します。
ANOVA の結果からは、2つ以上の群に差があるかどうかまでしか分からないため、具体的にどの処理 (処置) が異なっているかを判断するには、多重比較の結果を使用します。多重比較の結果の特定のタイプは、使用する比較検定法、および、比較の仕方、すなわち、全ての組み合わせ (pairwise) か、対照群との比較 (versus a control) かによって異なります。
- 全ての対の組み合わせ (All pairwise comparison) の結果には、組み合わせ可能な全ての群の対の一覧が表示されます。全ての対の組み合わせには、Tukey, Student-Newman-Keuls test および Dunn’s test があります。
- 単一の対照群との比較では、選択した対照群 (control group) との比較しか表示されません。対照群は実際に行う多重比較プロシージャで指定します。対照群との比較検定には、および Dunnett’s test と Dunn’s test があります。
- Tukey, Student-Newman-Keuls, および Dunnett’s Test の結果:Tukey と Student-Newman-Keuls (SNK) 検定は、群の全ての対の組み合わせを比較するものです。Dunnett’s test は、対照群とそれ以外の全ての群との比較しか行いません。いずれの検定も q 統計量を計算します。これらはまた、比較 p の間の順位和の件数も表示し、その対比較で P < 0.05 または < 0.01 であるか否かを表示します。
q の値が大きいものであれば、比較した2群の間の差は統計的に有意であると結論付けることができます。
比較した P 値が 0.05 より小さい場合は、誤って有意差があると結論付けてしまう可能性は 5% よりも小さくなります。この値が 0.05 より大きければ、確信を持って有意差があると結論付けることはできません。
Difference of Ranks (順位の差) が2群間の実際の差の大きさの尺度になります。
p は、q の算出に使用するパラメータです。p が大きければ、有意差を示すのにそれだけ大きな q が要求されます。p は、比較する群平均の順位に関する差の指標です。SNK や Dunnett’s 検定では、群の順位和に大きいものから小さい順にそれぞれ順位が付けられ、比較における順位和の数の隔たりが p になります。例えば、比較する順位和が4つある場合、最大と最小を比較すると p=4 となり、二番目に小さなものと最小のものを比較すると p=2 になります。
ある群が他の群と比べて有意差がないことが分かった場合、差のない2群の順位和の間にある順位を持つ全ての群についても、有意差がないとみなされますので、これらの比較については DNT (Do Not Test) という結果が表示されます。
- Dunn’s Test の結果:Dunn の検定は、全群の比較または対照群との比較に使用します。Dunn の検定では、順位平均の差が一覧で表示され、Q 検定統計量が計算され、各群の対ごとに P < 0.05 であるか否かが表示されます。
Q が大きい値の場合、比較する2群の差は統計的に有意であると結論付けることができます。
比較の P 値が 0.05 より小さい場合、有意差があると誤って結論づけてしまう確率は、5% よりも小さくなります。この値が 0.05 よりも大きい場合、確信を持って差があると結論付けることはできません。
Difference of Rank Means (順位平均の差) は、2群の間の差の大きさの尺度となります。
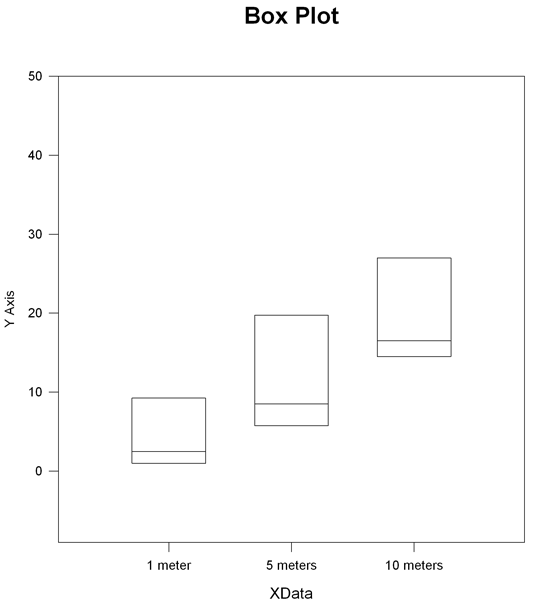
8. 順位に関する分散分析のレポートグラフ
NOVA on Ranks の結果を使用して以下に示すグラフを3つまで作成できます:
8.1 ANOVA on Ranks のグラフを作成する方法
- ANOVA on Ranks 検定のレポートを選択します。
- Report タブをクリックします。
- Results Graphs グループにある Create Result Graph をクリックします。
- Graph Type リストの中から作成したいグラフタイプを選択して、OK をクリックします。選択したグラフがグラフウィンドウに表示されます。詳しくは、レポートグラフ をご覧ください。