|
| サイトマップ | |
||
|
| サイトマップ | |
||
ワークシートにデータを配置する方法は以下のとおりです:
t 検定 (t-Test) と一元配置分散分析 (One Way ANOVA) では、以下のデータも利用できます:
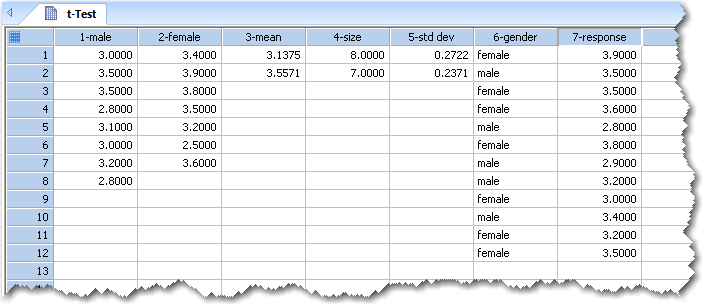 |
列1と列2には生データを配置しています。列3、4、5にはサンプルサイズ、平均値、および、標準偏差を使用した記述統計量を配置しています。列6と列7には、群別のインデックスを付けたデータを配置しており、列6を因子列に、列7をデータ列にしています。
お持ちのデータが統計値 (サンプルサイズ、平均値、標準偏差、または、標準誤差) の形式である場合、サンプルサイズ (N) をワークシートのある列に配置したら、平均値はそれ以外の列に、標準偏差 (または標準誤差) は第三の列に配置し、それぞれのデータは群ごとに同じ行に揃える必要があります。
t 検定、分散分析 (ANOVA)、反復測定分散分析、および、それらのノンパラメトリック版で分析できるデータフォーマットには、以下に示す幾つかの種類があります:
データフォーマットの設定は、検定を実行するときにその都度表示される Test Wizard の Select Data パネルで行います。詳しくは、2.3 統計的要約データ をご覧ください。
| ※ 未整理の不揃いなデータ |
| SigmaPlot では、いかなる状況でも欠損したデータポイントを自動的に処理します ("–" で表示) 。もし、2因子の分散分析でどのセルも欠損値である場合は、適切なステップが提示され、それによって目的のプロシージャーを実行することができます。 |
生データ (raw data) フォーマットは、お持ちのデータに何の分析も変換も加えられていない最も一般的なフォーマットです。データを群別に配置して個々の列ごとに比較や分析ができるようにします。群の識別には列タイトルを使いますが、このタイトルは、分析レポートでも使用されます。
生データは、二元配置および三元配置分散分析を除く全ての検定に使用できます。
| ※ Note |
| SigmaPlot の検定では、整理されていない不揃いなデータを利用できます。比較する群のサンプルサイズを同じにする必要はありません。欠損データや数の等しくない列を使っても問題ありません。欠損値は空白のセル、または、ダブルダッシュ (“–“) であらわします。数値のみを想定する検定では、テキストデータも欠損値とみなされます。 |
| ※ t 検定と順位検定 |
| 比較する群は、常に2つの列に配置します。 対応のある t 検定 (Paired t-test) と符号付き順位検定 (signed rank test) では (いずれも反復測定検定)、各被験者のデータは同じ行にあるものと想定されます。 |
| ※ 一元配置分散分析と順位に基づく一元配置分散分析 |
| 群のデータを個別の列に配置しますので、群の数だけ列が必要になります。反復測定の一元配置分散分析と、反復測定の順位に基づく一元配置分散分析では、被験者のデータはそれぞれ同じ行にあるものと想定されます。詳しくは、Arranging Two Way ANOVA Data をご覧ください。 |
インデックス付きデータは、群の名称や水準をあらわすデータを含む因子列 (factor column) と、各行に対応するデータポイントを含むデータ列 (data column) で構成されます。このデータは、特定の順序に整理する必要はありません。
| ※ Note |
| 二元配置分散分析 (Two Way ANOVA) のデータは、常にインデックス付きになっていることが前提条件となります。 |
列1には第1の因子列が、列2には第2の因子列が、そして、列3にデータが含まれます。
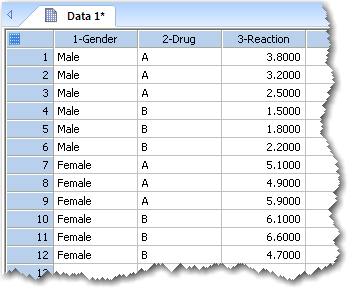 |
二元配置分散分析では、因子列が2つとデータ列が1つ必要になります。三元配置分散分析では、因子列が3つとデータ列が1つ必要で、反復測定分散分析では、測定する被験者を識別する被験者列 (subject column) を追加する必要があります。
インデックスとデータを含む行の順番は考慮されませんので、例えば、因子水準や被験者ごとに群分けしたり並べ替える必要はありません。
| ※ Note |
| データ列の全体を分析する場合、因子、被験者、データ列のワークシートにおける位置は問題になりません。詳しくは、Indexed Data をご覧ください。 |
反復測定の二元配置分散分析 (Two Way Repeated Measures ANOVA) では、データ列はもちろん、被験者用の1列と因子用の2列の両方が必要になります。
対応のない t 検定 (Unpaired t-test) と一元配置分散分析 (one way ANOVA) は、データの要約等計量に対して実行することができます。これらの統計量には以下の2つの形式があります:
サンプルサイズ (N) をワークシートのある列に配置したら、平均値はそれ以外の列に、標準偏差 (または標準誤差) は第三の列に配置し、それぞれのデータは群ごとに同じ行にする必要があります。
ブロックを選択してデータの一部だけを比較するのであれば、サンプルサイズを左端の列に、平均値を中央の列に、標準偏差や SEM を右端の列に配置します。