17.3 基本統計量でデータを説明する
SigmaPlot を利用して、測定データの基本統計量、すなわち、平均値 (mean)、中央値 (median)、標準偏差 (standard deviation)、百分位数 (percentiles) などを計算することで、お持ちのデータの要約 (サマリー) を作成することができます。
データの説明に必要な作業は以下のとおりです:
- お持ちのデータを適正な形式に配置する。
- 記述統計のオプションを設定する。
- 基本統計量を計算する列を選択する。
- 記述統計の結果を表示する。
- 記述統計のデータを配置する
- 記述統計のオプションを設定する
- 記述統計の検定を実行する
- 記述統計量の出力結果
- 記述統計の結果グラフ
- 記述統計の結果グラフを作成する
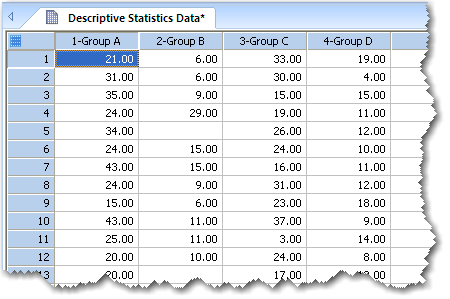
1. 記述統計のデータを配置する
記述統計 (Descriptive Statistics) を実行する対象はデータの列です。従って、分析を行いたい群や変数のデータをそれぞれ列ごとに分けて配置します。
図 3.2:処理または群を列ごとに分けたデータ配置
 |
データ列を選択する
統計量の計算は、列の全て、または、一部の列に対して行うことができます。記述統計プロシージャの実行に際しては、以下のことができます:
- 検定を行う前に列またはデータブロックを選択するか、
- 検定の実行中に列を選択する。
| ※ Tip |
| データの範囲を限定して統計量を計算するには、検定を実行する前にデータを選択します。記述統計に選択できるデータの列数は、最小1列から最大32列までです。 |
2. 記述統計のオプションを設定する
計算したい統計量は、Descriptive Statistics Options ダイアログで選択します。
記述統計の検定オプションを変更するには:
- 検定オプションを変更してから検定を行うに際して、事前にデータを選択しておきたい場合は、そのデータ範囲にポインタをドラッグします。
- Options for Descriptive Statistics ダイアログボックスを開くには、Analysis タブの SigmaStat グループにあるドロップダウンリストの中から Descriptive Statistics をクリックします。
- Options をクリックします。
Options for Descriptive Statistics ダイアログボックスが表示されます。
図 3.3:
Options for Descriptive Statistics ダイアログボックス
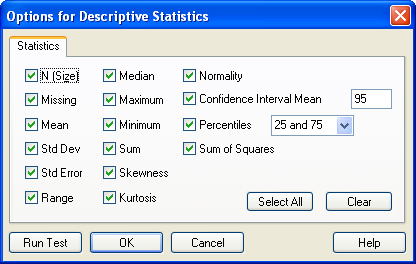 |
- このうちレポートに含めたくない統計量があれば、そのチェックを解除します。詳しくは、記述統計量の出力結果 をご覧ください。
与えられたデータセットにふさわしい要約統計量は、そのデータの性質によって異なります。測定値が正規分布に従っていれば、平均値 (mean) と標準偏差 (standard deviation) でそのデータの特徴をうまく説明できます。もしそうでなければ、多くの場合、中央値 (median) と百分位数 (percentiles) でデータの特徴をうまく説明できます。
- 信頼区間 (confidence interval) を変更するには、Confidence Interval Mean ボックスに 1 から 99 までの任意の数を入力します (最もよく使われる区間は 95 と 99 です)。
- 計算する百分位数 (percentiles) または信頼区間 (confidence intervals) を変更するには、Percentile ボックスの値を編集します。
- 全ての統計量のオプションを選択するには、Select All をクリックします。全ての選択を解除するには、Clear をクリックします。
- Run Test をクリックすると、選択されたオプション設定をもとに検定が実行されます。
| ※ Tip |
| 小数点以下の桁数の表示を設定するには、Sigma ボタンをクリックして Options をクリックします。Options ダイアログボックスの Report タブをクリックしたら Number of significant digits で変更したい桁数を選択します。 |
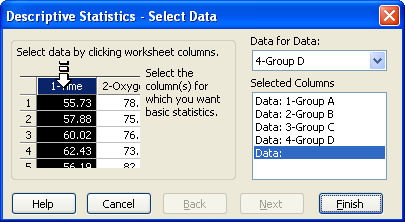
3. 記述統計の検定を実行する
このプロシージャを実行する前にお持ちのデータを選択したい場合は、そのデータにポインタをドラッグします。お持ちのデータの記述統計を行うには:
- Analysis タブの SigmaStat グループにある Tests ドロップダウンリストをクリックしたら Describe Data を選択します。
Descriptive Statistics - Select Data ダイアログボックスが表示されますのでデータ形式を指定します。
図 3.4:
Descriptive Statistics - Select Data ダイアログボックス
 |
| ※ Tip |
| 検定を選択する前に列を選択していれば、選択された列が Select Columns リストに自動的に表示されます。 |
- Selected Columns リストにワークシートの目的の列を割り当てるには、ワークシートで直接その列を選択するか、Data for Data ドロップダウンリストから対象となる列を選択します。
最初に列を選択すると Selected Columns リストの最初のエントリにその列が割り当てられ、続けて列を選択すると、そのリストに続けて割り当てられることになります。各エントリには、選択した列の番号またはタイトルが表示されます。Descriptive Statistics Test (記述統計検定) で選択できるデータ列の最大数は 64 列となります。
- 選択状態を変更するには、変更したいエントリをリストで選択してから、変更後の列をワークシートで選択します。既に割り当てられた列を消去するには、Selected Columns リストのアイテムをダブルクリックして行うこともできます。
- Finish をクリックすると、選択した列にあるデータを使用して検定が実行されます。計算が完了すると、レポートが表示されます。
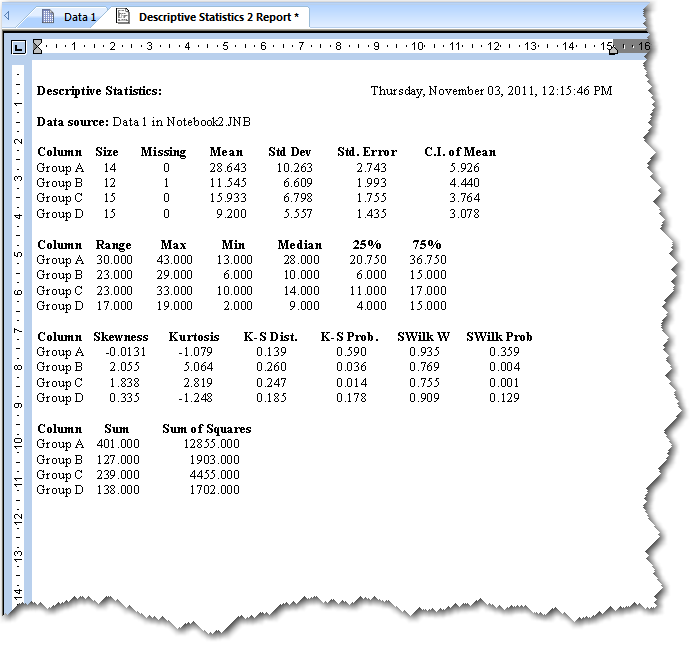
4. 記述統計量の出力結果
計算結果のレポートには、以下に示すような各種統計量が表示されます。それぞれの値は、選択した列ごとに計算されたものです。Options for Descriptive Statistics で選択した統計量についてそれぞれ計算が行われることになります。
図 3.5:記述統計の結果をあらわすレポート
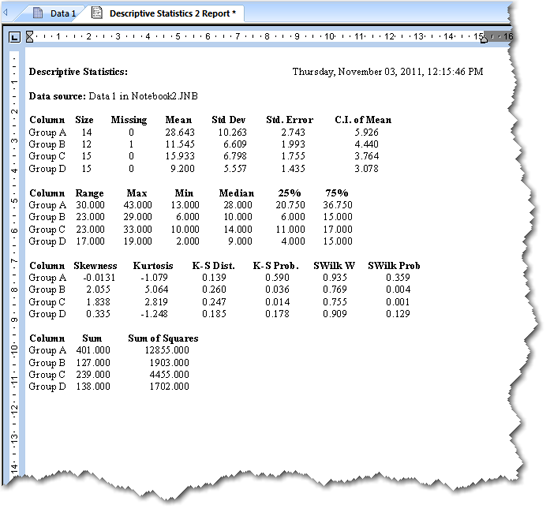 |
- Size. (サイズ) 各ワークシートの列にある観測値の件数です。(訳注:原文は non-missing observations 非欠損の観測数)
- Missing. (欠損値) 各ワークシートの列内にある欠損値の件数です。
- Mean. (平均値) 平均値は各列を算術平均した値です。観測値が正規分布に従う場合、平均値はその分布の中央になります。
- Standard Deviation. (標準偏差) 標準偏差は、データの平均値からのばらつき具合をあらわす量です。
- Standard Error of the Mean. (平均値の標準誤差) 平均値の標準誤差は、標本の平均値が真の母集団の平均値をどれだけ正確に見積っているかをあらわす量です。
- Range. (範囲) 範囲は、最大値から最小値を引いた値です。
- Maximum. (最大値) 最大値は観測された最も大きな値です。
- Minimum. (最小値) 最小値は観測された最も小さな値です。
- Median. (中央値) 中央値は、観測データの "中央" にある値です。すべての観測データを小さいものから順に並べたあと、それらを半分に分けたときの小さいほうの最大値を選ぶことで求められます。
- Percentiles. (パーセンタイル: 百分位数) データの上端と下端 (両側) を定義する2つのパーセンタイル点です。Descriptive Statistics オプションで指定します。
- Sum. (合計) 合計は、すべての観測値の合計です。合計を標本サイズで割ったものが平均値になります。
- Sum of Squares. (平方和) 平方和は、観測値をそれぞれ二乗して合計したものです。
- Confidence Interval for the Mean. (平均値の信頼区間) 平均値の信頼区間は、真の母集団の平均値が一定割合で含まれる、母集団から任意に取り出される標本の平均値の範囲です。
- Skewness. (歪度) 歪度は、観測値の平均値に対する分布の対称性をあらわす統計量です。正規分布の歪度はゼロになります。
- Kurtosis. (尖度) 尖度は、観測値の分布が正規分布と比較してどれだけ尖っているか、または平らであるかをあらわす統計量です。正規分布の尖度はゼロになります。
- K-S Distance. (K-S 距離) コルモゴロフ=スミノフの距離は、お持ちのデータのヒストグラムと、お持ちのデータのパラメータ推定値に基づく理論上のガウス曲線との間の累積距離の最大値です。
- K-S Probability. (K-S 確率) コルモゴロフ=スミノフの確率は、母集団から無作為に抽出されたデータのヒストグラムと理論上のガウス分布曲線との距離が、標本に基づく K-S 距離より大きくなる確率です。
- Shapiro-Wilk W. (シャピロ=ウィルクの W 統計量) シャピロ=ウィルクの W 統計量は、お持ちのデータが正規分布から抽出されたものであるという帰無仮説を検定するものです。W 統計量が小さければ、正規性から外れていることを示します。
- Shapiro-Wilk Probability. (シャピロ=ウィルクの確率) シャピロ=ウィルクの確率は、W 統計量と関連する有意性の確率です。
- Normality. (正規性) 正規性は、シャピロ=ウィルクの検定またはコルモゴロフ=スミノフの検定を使って観測値の正規性を検定します。
5. 記述統計の結果グラフ
記述統計のグラフを元に最大5種類のグラフを作成することができます。以下にそのグラフを示します:
- Bar chart of the column means. (列平均の棒グラフ) 記述統計の棒グラフでは、群の平均値が垂直の棒でプロットされ、それぞれに標準偏差をあらわすエラーバーが付けられます。詳しくは、列平均の棒グラフ (Bar Charts of the Column Means) をご覧ください。
- Scatter plot with error bars of the column means. (列平均のエラーバー付き散布図) 記述統計の散布図では、列平均が1点でプロットされ、それぞれに標準偏差をあらわすエラーバーが付けられます。詳しくは、散布図 (Scatter Plot) をご覧ください。
- Point plot of the column data. (列データの点プロット) 記述統計の点プロットでは、各列のすべての値がグラフ上の点としてプロットされます。詳しくは、点プロット (Point Plot) をご覧ください。
- Point plot of the column data with error bars plotting the column means. (列データの列平均をプロットするエラーバー付き点プロット) 記述統計の点と列平均のプロットでは、列平均と各列の標準偏差をあらわすエラーバー付きで各列のすべての値がグラフ上の点としてプロットされます。
- Box plot of the percentiles and median of column data. (列データのパーセンタイルと中央値をあらわす箱ヒゲ図) 記述統計検定の箱ヒゲ図では、列データのパーセンタイルと中央値がプロットされます。詳しくは、ボックスプロット (Box Plot) をご覧ください。
5.1 記述統計の結果グラフを作成する
記述統計レポートのデータからグラフを作成するには:
- Descriptive Statistics のレポートが現在表示されていることを確認します。
- Report タブの Result Graphs グループにある Create Result Graph をクリックします。Create Result Graph ダイアログボックスに Descriptive Statistics レポートで利用可能なグラフタイプが表示されます。
図 3.6:
Create Result Graph ダイアログボックス
 |
- Graph Type リストの中から作成したいグラフタイプを選択したら OK をクリックします。指定したグラフがグラフウィンドウまたはレポート内に表示されます。
| ※ Tip |
| リスト内のグラフをダブルクリックして作成することもできます。 |