|
| サイトマップ | |
||
|
| サイトマップ | |
||
図 7.1 に示すのは、AutoFeature ウィンドウのサンプルです。AutoFeatures で定義できる対象は、領域 (Region) とセグメント (Segment) の2つのタイプがあります。
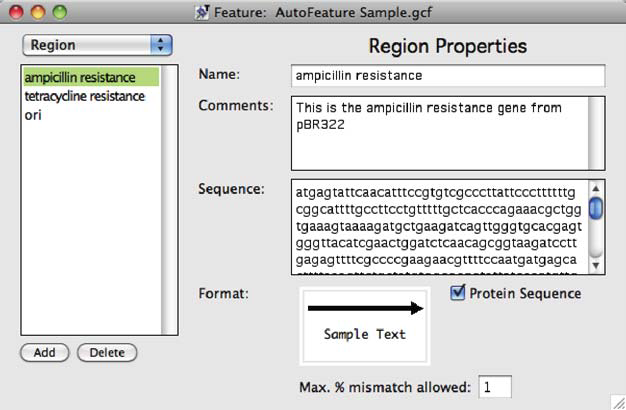 |
左側のポップアップメニューには、Regions が選択されていますので、リストボックスの項目はすべて領域に関するものとなります。GCK における領域は、DNA 配列自体の中に示されるのではなく個別の特徴 (feature) として示される装飾品 (adornments) です。これは、タンパク質のようなものをあらわすのに役立ちます。タンパク質は、DNA 配列の中には実際に表示されませんが、翻訳されるヌクレオチドの範囲 (range) として示したい場合がよくあります。
AutoFeature ファイルの Region では、関連づけられるテキストフィールドが3つあります。Name フィールドには、この特徴をマークするときに毎回割り当てる名称が入ります。
次のフィールドは Comments (コメント) と呼ばれるもので、書き込んでおきたい内容をここに自由に入力することができます。将来この特徴に関連して役立つと思われる情報を入力するのにこのフィールドを利用することができます。入力された内容は AutoFeature ファイルを使ってマークを付けられるすべての特徴に関連付けられるので、後から GCK で検索することができます。従って、冷蔵庫の場所、塩基配列のソース、関連する引用文献、または将来参照する可能性のあるその他のアイテムを記入しておくことができます。
Sequence フィールドには、ターゲット塩基配列の中の注釈をつけたい DNA 配列が入ります。ターゲット塩基配列の中からこの配列を GCK でどのように検索したいかを検討してください。塩基配列の検索と Tutorial 20: “Find Sequence” で説明した塩基配列の検索と規則は同じです。大文字で入力された文字は厳密に一致します。ある程度のミスマッチを許容するなら、クエリに小文字で入力しないとミスマッチは発生しれません。図 7.1 に示す事例では、全ての塩基配列が小文字で入力されています。この特徴では、最大 1% のミスマッチが定義されており、塩基配列はすべて小文字で入力されているので、ミスマッチはターゲット塩基配列内の全ての場所で発生します。1% のミスマッチは、多くはありませんが、ある程度の生物種のばらつきと塩基配列情報入力時の人為的エラーを許容します。許容するミスマッチの割合を多くすれば、それだけ間違った情報をつかむ割合も多くなります (クエリーで示された一致が、実際と同じ塩基配列ではありません)。正しいとされる一般的なガイドラインは、ミスマッチの割合が 5% を越えないときです。
お持ちの塩基配列がコーディング配列の場合、“Protein Sequence” のボックスにチェックを入れてください。これにより、Format ラベルの横にある矢印で示された方向にこの配列が新しい領域を作成すると分かったとき、その配列をタンパク質配列に翻訳するよう GCK に伝えられます。
この画面の最後のパートは、この特徴 (feature) のフォーマットをあらわすボックスです。この事例で示すように、この領域は太さ 5 ピクセルの右向きの黒い矢印になります (DNA の上鎖に対応) 。この領域のテキスト部分は、Monaco 12 Pt で表示されます。こうした属性は、Format メニューを使って自由に変更することができます。
AutoFeature ウィンドウの左下にある Add および Delete ボタンは、新規 AutoFeature を追加したり、既に存在する AutoFeature を削除する際に関係するものです。2つのボタンの動作は他のプログラムと同様です。Add をクリックすると、新規 (空の) AutoFeature が作成され、そこに塩基配列やその他の情報、および、好みのスタイルを入力します。もしリストで AutoFeature のいずれかひとつが選択されていれば、Delete ボタンが有効になります。Delete ボタンをクリックすると、選択した AutoFeature をこのファイルから完全に削除できます。