ヒューリンクステクニカルサポート
更新日:
14/04/15
2. パラメトリック関数
ここでは、特定のデータのパラメトリックモデルの構築法について述べます。パラメトリックモデルの中心テーマは、データの特性をよく表しているパラメータを見つけ出すことです。補間と外挿が目的の近似関数と違って、パラメトリックモデルではパラメータの数とパラメータ間の相互作用が、非常に重要となります。
とはいっても、データの元となる事象に関して、その理論的な仕組を知っている必要はありません。理論的な構造がある場合は、エネルギーや濃度、歩留まり、年齢などの物理的あるいは理論的なパラメータでデータの特性を説明することができますが、その必要はないということです。
理論的な背景のあるパラメトリックモデルでは、独立変数 XY と従属変数 Z の間に何らかの関係があることを前提としてモデルを構築します。
理論的な背景のないパラメトリックモデルの場合は、データが示す特徴を表現することになります。ここで使用するサンプルデータは、このタイプのデータです。データは、確かに物理的、化学的、生化学的、生理学的、あるいは人為的な因果関係から得られますが、それを理論的に解明した関係式は、必要ありません。
このタイプの解析では、データを生み出したシステムはブラックボックスとして扱い、パラメータはシステム内部ではなく、外部の様子を説明するために使用されます。理論的に説明がつけられないデータサンプルとして、人間の生化学的データほどよいものはありません。以下に、この種のデータのパラメトリックサーフェスフィッティングを紹介します。
- 反応の最適化データ
- メインウィンドウのグラフと統計情報
- 3Dピーク関数
- サーフェスフィットのカスタマイズ
- 自動フィッティング
- サーフェスフィッティングの考察
- ユーザー定義関数
- ユーザー定義関数だけのフィッティング
- ユーザー定義関数のサーフェスフィットグラフ
- ユーザー定義関数フィッティングの数値データ
反応の最適化データ
TableCurve 3D の起動
- スタートメニューで TableCurve 3D v4.0 を選択して、起動して下さい。
- 起動後、何のノートブックも表示されない場合は、File|New メニューコマンドまたは
 ボタンをクリックして下さい。
ボタンをクリックして下さい。
z = f(x,y)
TableCurve 3D では、Z が従属変数です。すべての関数は、独立変数 XY を使って Z を求めます。X と Y は、すべての関数で置換えることはできません。X、Y、Z 値の各ベクトルを用いて、XYZ データテーブルを定義することができます。
XYZ データテーブルの設定
TableCurve 3D を使用するには、まず XYZ テーブルを設定する必要があります。TableCurve 3D のデータテーブルの最大サイズは、XYZ 3列×16,384行です。これより大きなデータの場合は、ディジタルフィルタを使用すれば最大 1,600万行のデータまで対応できます (フィルタによって、データ行が間引きされます) 。
データソース
TableCurve 3D は、以下のデータに対応しています。
- XYZ 3列の ASCII ファイル
- Excel
(XLS v3 ~ XLS Office XP)
- Lotus
123 (WK4, WK3, WK1, WKS, WRK)
- Quattro
Pro (WB2, WB1, WQ1, WKQ)
- SigmaPlot
(JNB, SPW, SP5, SPG)
- XYZ 3列の DIF ファイル
- dBase
III+ および dBase IV (DBF)
- SPSS
Windows (SAV)
- Systat
Windows (SYS)
このサンプルでは Excel XLS ファイルを使用します。
データのインポート
元データが XYZ データだけの場合でも、あるいは何千列のデータがあっても、最初のステップは同じです。元データは読み込まれると、TableCurve
3D のノートブックに加えられます。
- File|Import
Data Sourceメニューコマンドまたはメインツールバーの
 ボタン、あるいはメインウィンドウの左側セクション (TableCurve
3D Explorer) にあるノード (TableCurve 3D Data Source(s)) をマウス右クリックし、Import Data Sourceetを選択して下さい。
ボタン、あるいはメインウィンドウの左側セクション (TableCurve
3D Explorer) にあるノード (TableCurve 3D Data Source(s)) をマウス右クリックし、Import Data Sourceetを選択して下さい。
- ファイルの種類のドロップダウンリストからExcel
[xls]を選択し、sample.xlsを指定して開くボタンを押して下さい。読み込まれたノードは、まだ開かないで下さい。

XYZデータの自動読込み
TableCurve 3D は、自動的に XYZ データとしてデータソースまたはワークシートを読込みます。これは、File|Autospecify
All XYZ Data Items メニューコマンド、メインツールバーの  ボタン、TableCurve
3D explorer のデータソースを右クリックしたときに表示されるオプションにしたがって実行されます。
ボタン、TableCurve
3D explorer のデータソースを右クリックしたときに表示されるオプションにしたがって実行されます。
このオプションを使用するとき、2つの選択肢があります。これは、読み込む列数の設定オプションです。
- 順番に X、Y、Z 列として読み込みます
- 順番に X、Y 列を読込み、続いて複数の Z列 (それぞれ異なるデータセット) を読み込みます
列データには、空白セル、文字型セルも可ですが、少なくとも最初の 100行の中に 1つ以上の数値型セルがなければなりません。これは、すべての Z列に対して当て嵌まります。dBase や DIF ファイルなどのフィールド形式データの場合は、フィールドの順に Z列が指定されます。Systat や SPSS ファイルなどの変数形式データの場合は、変数名によってZ列が指定されます。
sample.xls ファイルには、Excel 形式でサンプルデータが収められています。XYZ データセットのメインタイトルが、最初の行に記入されています。これは、どのファイル形式でも Z列に記入しなければなりません。2行目に XYZ 各列タイトルが記入され、3列目からデータが始まります。
- ノートブックの sample.xls データソースを選択し、File|Autospecify All XYZ Data Items メニューコマンドまたはマウスを右クリックして表示されたポップアップメニューの Autospecify
All XYZ Data Items コマンド、あるいはメインツールバーの ボタンをクリックして下さい。
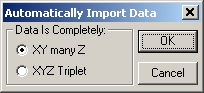
- XY many Z を選択して、OK ボタンを押します。
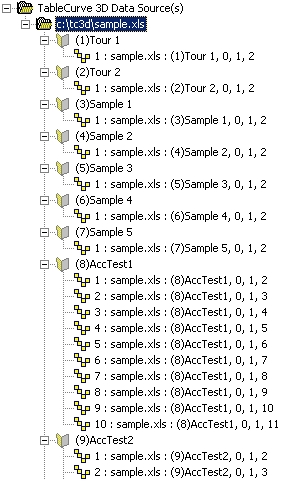
XLS ファイルに含まれているすべての XYZ データセットが表示されます。また、View|Data Graph メニューコマンドで設定した 3D グラフの設定で、メインウィンドウ内に 3D グラフが表示されます。
- 「Tour 2 : Parametric Functions」のラベルが付いた XYZ データノードを選択して下さい。
このアイテムを右クリックをし、ポップアップメニューの Titles コマンドを選択して下さい。
デフォルトの XYZ タイトル
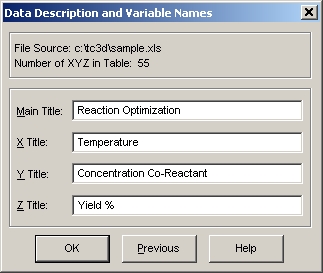
- メインタイトルに「Reaction Optimization」と入力して下さい。
XYZ 変数の列タイトルはそのままにしましょう。
- OK ボタンを押してタイトルの編集を終えます。
メインタイトルを変更すると、ノートブックのデータアイテムのタイトルも変わることに注意して下さい。ノートブックのアイテムは、直接左クリックしてタイトル名を変更することも、右クリックして表示されたポップアップメニューを使って変更することもできます。
この XYZ データアイテムには、あらかじめタイトル名が設定されています。タイトル名は、TableCurve 3D で何かの操作をする度に使用されます。また TableCurve
3D Explorer (メインウィンドウの左側セクション) にデータアイテムといっしょに保存されます。
デフォルト設定のタイトルは、いつでも Table|New
Titles メニューコマンドまたはメインツールバーの  ボタン、データアイテムを右クリックをして変更することができます。
ボタン、データアイテムを右クリックをして変更することができます。
さらに高度なタイトルの設定も、3D グラフで可能です。
メインウィンドウのグラフと統計情報
ノンパラメトリックなサーフェスグラフ
メインウィンドウの右上セクションには、データのノンパラメトリックなサーフェスプロットが表示されます。個々に表示されるグラフは、TableCurve
3D Explorer (メインウィンドウの左側セクション) で選択されたデータです。このグラフをクリックすると、View X,Y,Z Data ウィンドウが開きます。
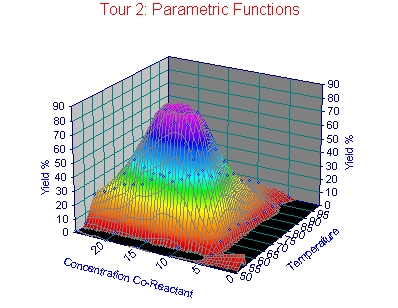
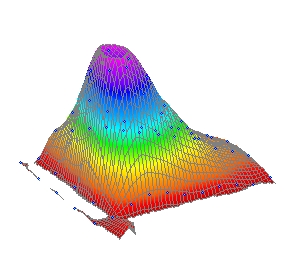
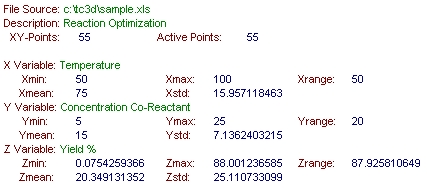
このデータは、最適温度 (X 変数) と共反応レベル (Y 変数) の 2変数を用いた反応最適化モデルです。このような DOE (実験計画法) マトリクスを用いて、最適な反応条件を求めることができます。
グラフのアニメーション
ここでは、データを観察するのに大変便利なアニメーション機能を紹介します。デフォルトのグラフ表示でも、3D ピークがよくわかるように表示されていることに注意して下さい。
- View|Animation
Setup メニューコマンドまたはツールバーの
 ボタンをクリックして下さい。
ボタンをクリックして下さい。
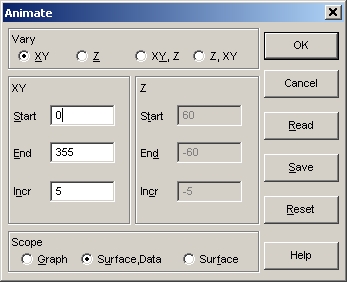
- この設定は、XY 平面上を 0 度から 355 度まで 5度刻みで回転し、サーフェスとデータの両方を表示するように指示されています。これで OK ボタンを押して下さい。
View|Animation メニューコマンドまたはツールバーの  ボタンを使って、アニメーションを ON/OFF させることができます。ノートブックでアイテムの選択を変更しない限り、アニメーションは続きます。
ボタンを使って、アニメーションを ON/OFF させることができます。ノートブックでアイテムの選択を変更しない限り、アニメーションは続きます。
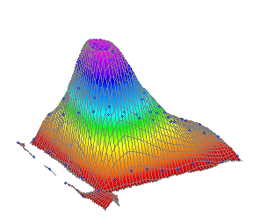
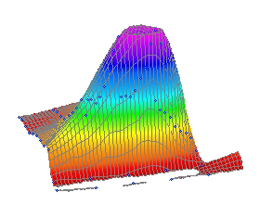
アニメーションから、温度と濃度の両方で 3D ピークは非対称であることがわかります。このデータは、対称形の 3D ピークを持っていないようです。
- ノートブックのその他のデータセットを選択して、アニメーションを切換えてみて下さい。最後にまた Reaction
Optimization のデータセットに戻って下さい。
- ボタンをクリックして、アニメーションをストップさせます。
統計情報
メインウィンドウの右下セクションには、選択したデータセットの統計情報、概要が表示されます。
3D ピーク関数
増加 3D ピーク関数では、XY 変数によってピークが形作られます。この場合、特定の温度と共反応のレベルがピークを作り出しています。低温度の境界付近では共反応のレベルも高くありません。同様にゼロ付近の共反応レベルでは、温度も高くありません。
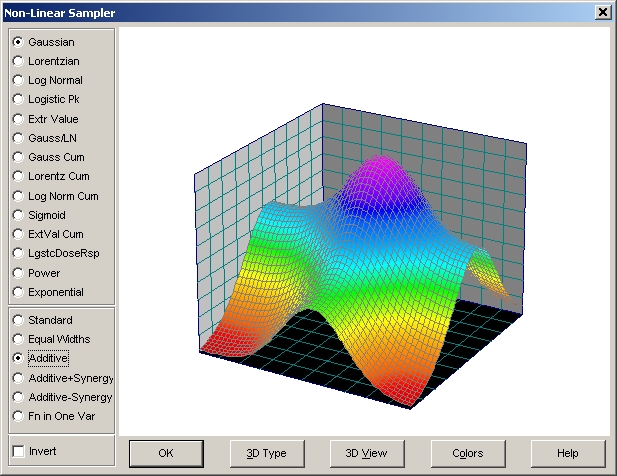
- ピークの形と特性が何を意味しているのか TableCurve 3D で知るには、View|Non-Linear
Sampler メニューコマンドを実行します。ピークの種類 (上のセクション) からどれかを選び、プロファイル (中央のセクション) でまず Standard を選択し、次に Additive を選択して下さい。
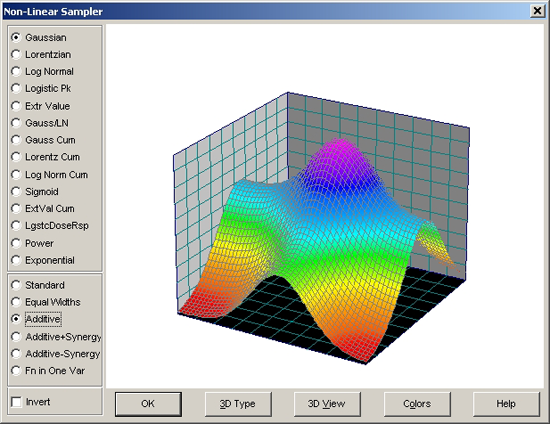
標準 (Standard) ピークと累積 (Additive) ピークでは、はっきりとその違いが表れます。
- OK ボタンを押して終了して下さい。
シンプルな 3D 乗算ピークのパラメータ
最もシンプルな 3D 乗算ピークには、5つのパラメータがあります。
- 振幅
- ピーク X 座標の中央値
- ピーク Y 座標の中央値
- ピーク X 座標の幅
- ピーク Y 座標の幅
乗算ピークは、ピークの X 座標と Y 座標を掛け合わせたものなので、一方の振幅は 1.0 とし、もう一方の振幅だけ必要となります。
サーフェスフィッティングによって、温度と共反応による最大の反応条件をみつけることが、このサンプルの目的です。したがって、2つの変数の中央値は重要なパラメータとなります。
サーフェスフィットのカスタマイズ
Process|Surface-Fit
Peak Functions メニューコマンドまたはツールバーの  ボタンをクリックすると、TableCurve
3D 標準の 72個の非線形ピーク関数でフィッティングを実行します。ここでは、データによくマッチするのがわかっていますので、標準ピーク関数についてのみ説明します。また線形モデルを使用してもよいフィッティングは行えるのですが、近似関数は2変数の中央付近とは関係のない係数を持つことになります。
ボタンをクリックすると、TableCurve
3D 標準の 72個の非線形ピーク関数でフィッティングを実行します。ここでは、データによくマッチするのがわかっていますので、標準ピーク関数についてのみ説明します。また線形モデルを使用してもよいフィッティングは行えるのですが、近似関数は2変数の中央付近とは関係のない係数を持つことになります。
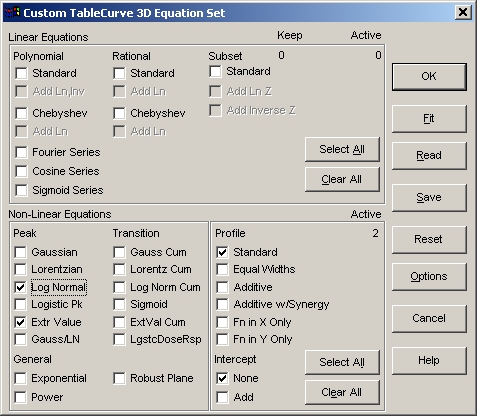
ユーザー定義の関数セット
TableCurve 3D では、フィッティングに使用する線形および非線形関数を選択することができます。
- Process|Edit
Custom Equation Set メニューコマンドまたは
 ボタンをクリックします。Linear
Equations セクションの Clear All ボタンを押し、Non-Linear Equations セクションでは 6つの Peak タイプすべてと、Standard プロファイル、Intercept オプションの None と Add のみを ON にして下さい。Active な非線形関数の数は、14 と表示されます。
ボタンをクリックします。Linear
Equations セクションの Clear All ボタンを押し、Non-Linear Equations セクションでは 6つの Peak タイプすべてと、Standard プロファイル、Intercept オプションの None と Add のみを ON にして下さい。Active な非線形関数の数は、14 と表示されます。
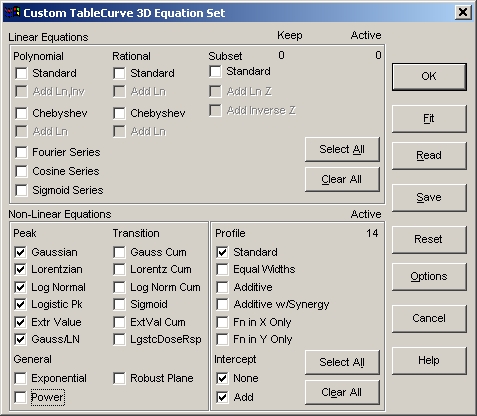
- OK ボタンを押して、ダイアログを閉じて下さい。
サーフェスフィットの設定
- Process|Surface-Fit
Preferences メニューコマンドまたは
 ボタンをクリックして下さい。一番上の Initial
Equation Sort セクションの F-statistic ラジオボタンをチェックして下さい。
ボタンをクリックして下さい。一番上の Initial
Equation Sort セクションの F-statistic ラジオボタンをチェックして下さい。
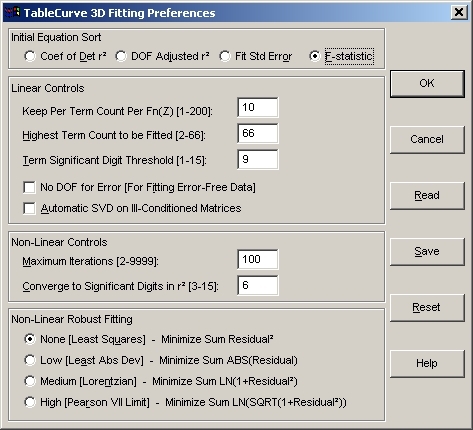
- OK ボタンを押してダイアログを閉じます。
- F 統計量
パラメトリック関数では、データの特徴をどれだけよく表しているかという観点で関数をソートした場合、F 統計量を使うのが最もよくなります。F 統計量で関数をソートすると、シンプル (=係数が少ない) で効果的なものほど上に、
効果的であるが係数の多いものは下にリストされます。言い換えれば、F 統計量はパラメータが少なくて効果的なモデルを重視し、係数が多いものは重視しません。
- 非線形関数の条件設定
非線形フィッティングは繰り返し実行されます。したがって、収束する条件と繰り返しの最大回数を設定する必要があります。最大繰り返し回数 (Maximum
Iterations) 100 は、複雑なユーザー定義関数を除いておおむね十分な回数です。収束条件 (Converge
to Significant Digits in r2) の 6 は、5回フィッティングを繰り返し、r2 の有効数字 6桁目に変化が見られない条件を表します。
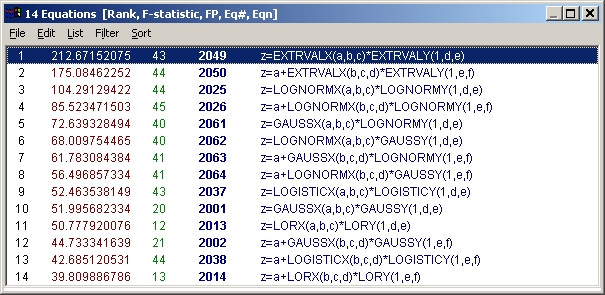
自動フィッティング
サーフェスフィッティング
- フィッティングを開始するにあたり、まずユーザー定義の関数セット
 を選択します。Fit ボタンをクリックしてフィッティングを実行したら、表示されたダイアログの Graph
Start ボタンを押して下さい。
を選択します。Fit ボタンをクリックしてフィッティングを実行したら、表示されたダイアログの Graph
Start ボタンを押して下さい。
14 関数のフィッティングは、あっという間に終わります。終了すると、ソートされ数式リストに表示されます。フィッティングが行えた非線形関数は、すべて数式リストに表示されます。
Fit ボタンを押した後、何もせずに 10秒がたつと、自動的に Review Surface -Fit ウィンドウが表示されます。
OK ボタンを押した場合は、Review|Graph
Start メニューコマンドまたは  ボタンをクリックして下さい。
ボタンをクリックして下さい。
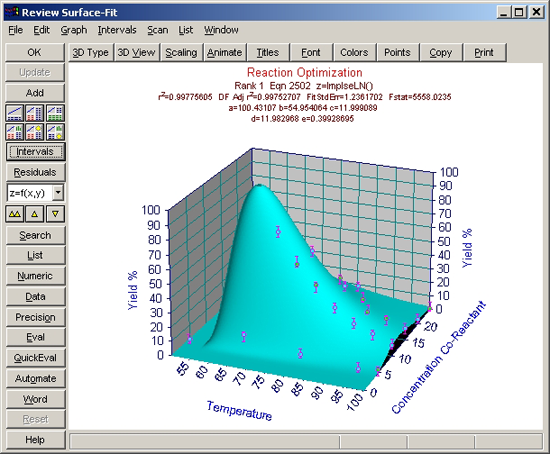
サーフェスフィッティングの考察
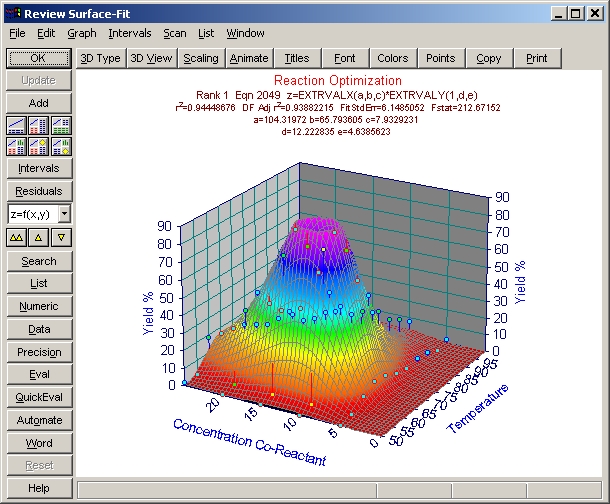
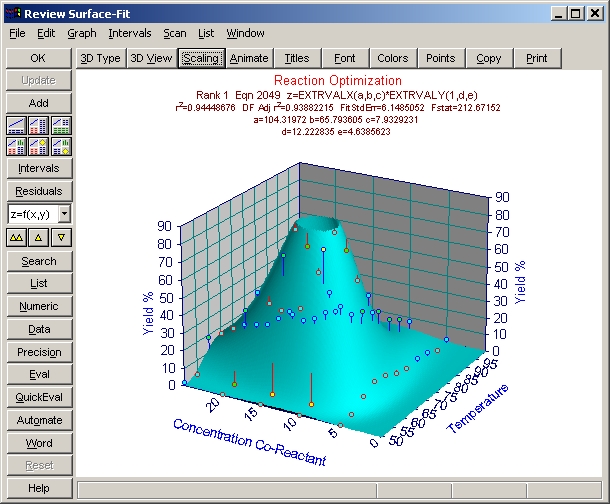
標準のピークモデルによるフィッティング
- タイル表示オプションの中で最もシンプルなタイプである
 ボタンをクリックして下さい。Review
Surface-Fit ウィンドウと Equations ウィンドウが開きます。
ボタンをクリックして下さい。Review
Surface-Fit ウィンドウと Equations ウィンドウが開きます。
数式リストの中で、もっとも上位にリストされたグラフが表示されます。
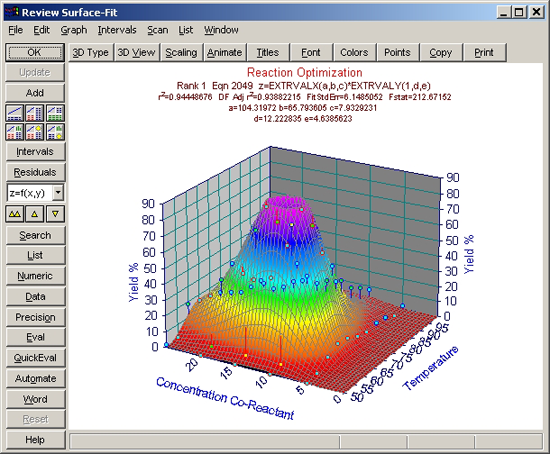
数式リストのタイトルバーに表示されているように、フィッティングの良さは F 統計量で判別されています。
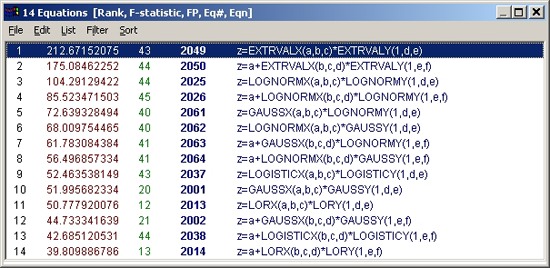
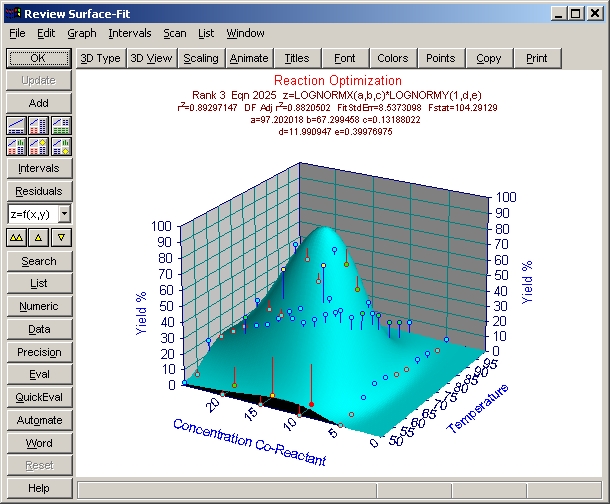
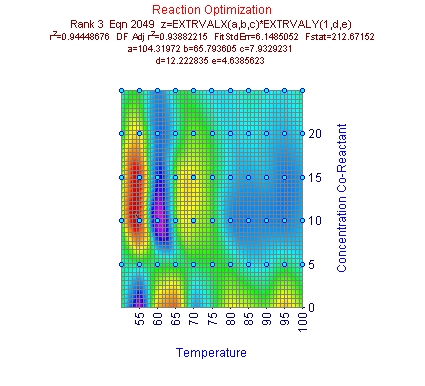
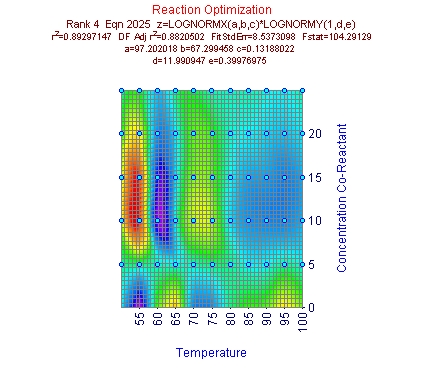
- 極値関数と対数正規分布関数
XY 方向のデータの非対称性を考慮すると、極値および対数正規分布関数が対象形ピーク関数よりもよいことは、驚くことではありません。パラメトリックモデルの方が、F 統計量が大きくなるということです。
どちらも切片を追加すると、F統計量は減少することに注意して下さい。このことから、このデータセットでは切片なしの関数を用いた方がよいことがわかります。ただし、r2 を使用した場合は、切片のある関数の方が上位となります。しかしながら、このデータセットの場合は切片なしが適切であることがわかっていますので、前者を採用します。
- モデルの妥当性
理論に間違いがないなら、答えは 1つしかないので、人生は単純なものです。このサンプルでは、今のところ最大効果を示すパラメトリックモデルしか見ていません。
検討すべき要因はいろいろあります。そこで r2 で見てみた場合、最上位の関数でも 0.944 の値しかもっていません。このデータセットの場合、XY 値は正確で、Z 値も数% の誤差と正確ですで、r2 はもっとよい数値でなければなりません。
一方で、極値関数も対数正規分布関数もこのデータセットには適切ではないという指摘があります。すべての範囲内でよい予測ができないということは、これよりももっとよいモデルがあるという印でもあります。
- 陰影付きサーフェスプロット
このタイプのサーフェスは、陰影付きサーフェスプロットにするとよいでしょう。
- 3D Type ボタンをクリックし、Shaded Plots セクションの 160
Cyan を選択し、OK ボタンを押します。
- 3D View ボタンをクリックし、Reset ボタンを押してから Mesh
Count ボックスでマウスの右クリックをし、表示されたリストから 120 を選択して OK ボタンを押します。
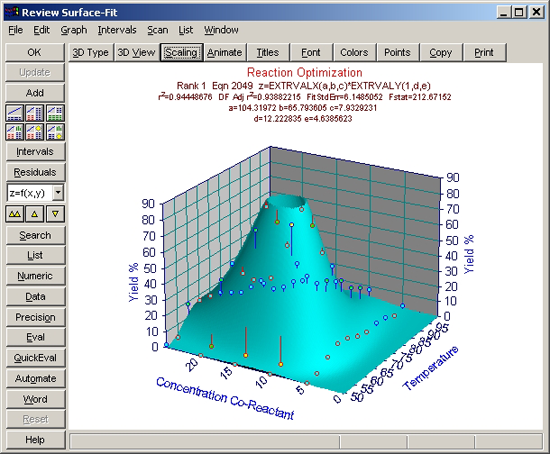
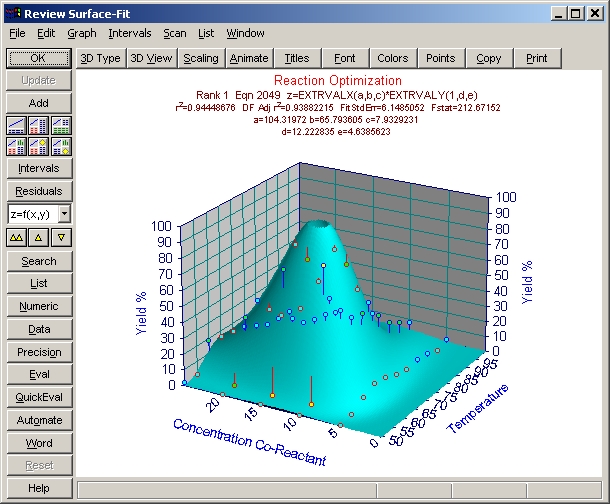
- グラフスケールの調整
TableCurve 3Dは、Zスケールの90%でサーフェスを切り捨てています。この最適化ではピークを求めているので、Z値の最大値が100%になるようにスケールを変更します。
- Scaling ボタンまたはグラフの左または右の Z軸ラベルの周辺をクリックして下さい。3D Scaling ウィンドウが表示されたら、Z軸セクションの Auto のチェックボックスを OFF にし、Max に 100、Divs に 10 を入力して OK ボタンを押します。
このモデルでは、最大値は 100% 以上に設定することもできます。
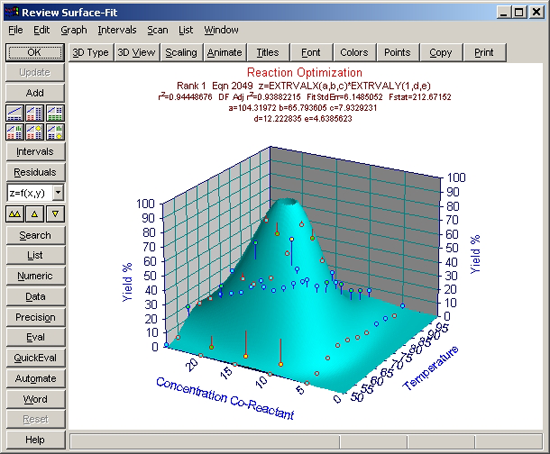
- 数式リスト 3番目の対数正規分布関数に切換えて下さい。このモデルは、求めたい最適値を正確に取り扱っていないことがわかります。
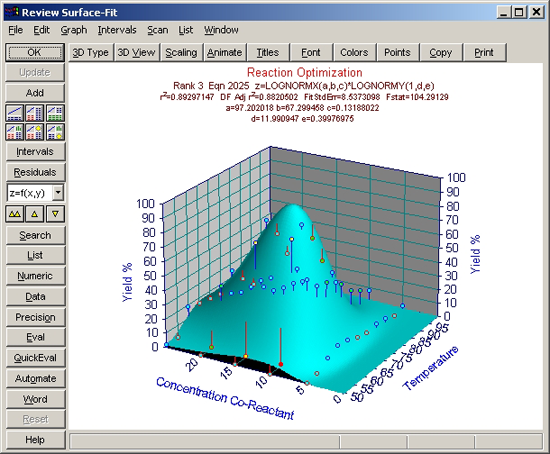
残差
適切でないモデルの場合、残差の傾向をみるとその解決策が見つかります。3次元データの場合、 X または Y 変数にある残差の特徴をまず見つ出すことが大事です。最もよい状態は、サーフェス全体にわたって残差がばらついていることです。
- 3番目の対数正規分布ピークを選択した状態で、Residuals (残差) ボタンをクリックして下さい。表示された Residuals ウィンドウの Graph|Residuals
Surface Graph メニューをチェックして下さい。Temperature 変数に、1つの特徴が明らかに見えます。
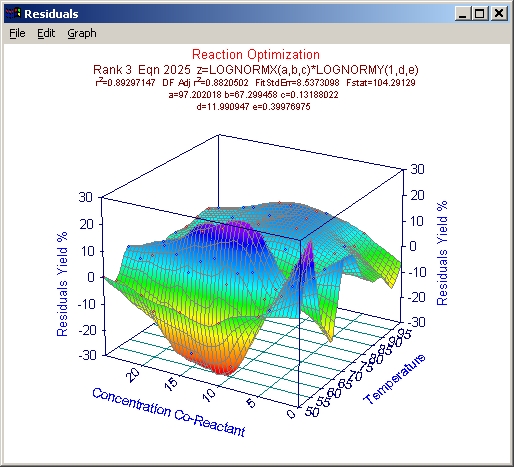
- Graph|Residuals
Graph メニューをチェックして下さい。次に Graph|Point
Format メニューコマンドをクリックし、Size セクションのスライダで 5 に設定し、OK ボタンを押して下さい。
通常の 3D 散布図では Z=0 の面にグリッドが描かれ、誤差の位置と最大値がわかりやすくなっています。それに対して 3D サーフェスの散布図では、誤差の傾向を見るときにわかりやすくなっています。
各ポイントは 4色で塗りつぶされていますが、これは標準誤差の値に基づいています。デフォルト設定では、1 SE 以下はシアン、1~2 SE は緑、2~3 SE は黄色、3
SE 以上が赤です。
- 再度 Graph|Residuals
Surface Graph メニューをチェックして下さい。
ばらつきのある残差では、各方向に対してプラスとマイナスの偏りがない値をもっています。言い換えるならば、グラフのどの領域をとっても、両方向にたくさんプラス/マイナスの切換があるはずです。一方向に特定の傾向がある場合は、それを見つけることはできません。
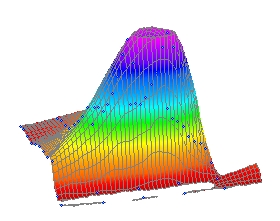
このデータセットでは、明らかに X すなわち Temperature 変数に特徴が見受けられます。ここで欲しいのは、極値あるいは対数正規分布ピークよりも、シャープなピークが X 変数に表れるフィッティング関数です。
視野角度
何が問題なのか見つける他の方法として、対数正規分布モデルが XY 範囲に適合しているかどうか見るため、視野の向きを変えてみることです。XY view
angles を 270 または 0 にすると、X 変数の特性が表示されます。Z viewの角度は、0にするかどうか自身で決めて下さい。
- 3D View ボタンまたはグラフの中央をクリックして下さい。まず XY view angle を 270 に、Z view を 0 にし、Perspective セクションの Level を 0 にします。探しているのは、立ち上がりがシャープで、緩やかに落ちる X 変数の特性です。
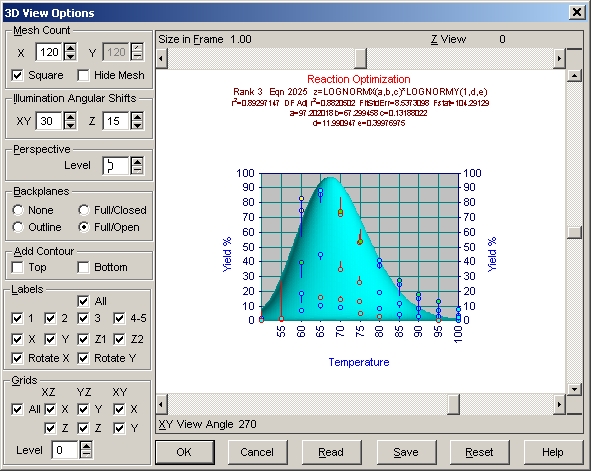
- X-Y view angle を 0 に設定して下さい。Y 変数に関しては、対数正規分布モデルで不足する点は見当たりません。
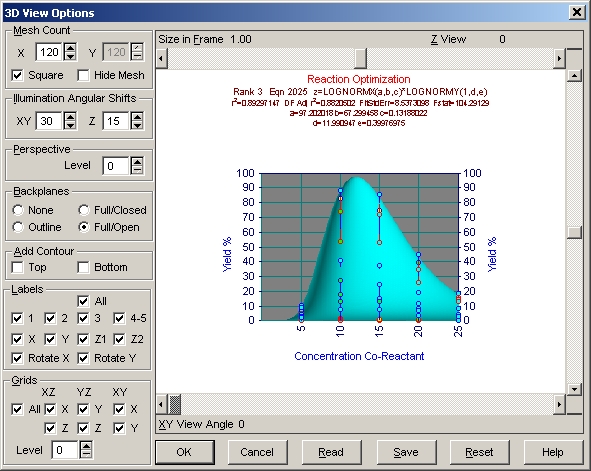
- Reset ボタンを押してデフォルト設定の視野に戻り、OK ボタンをクリックして下さい。再度 OK ボタンを押して、メインウィンドウに戻って下さい。
ユーザー定義関数
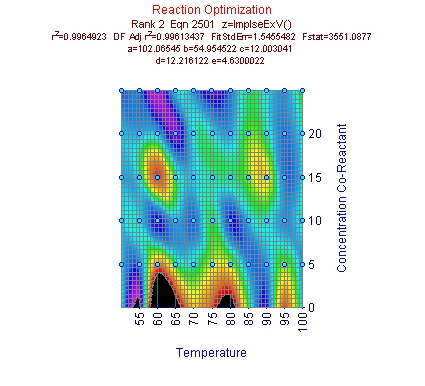
この段階で、このモデルのX変数は急速に立ち上がり、ゆっくりと下るピークが必要であることがはっきりしています。TableCurve 3Dで最も非対称のピークを持つのは極値関数で、データにもっとよく当て嵌まるようにカスタマイズする必要があります。
このインパルスピークモデルは、今必要とされているX変数の急な立ち上がりと、緩い下りの特性を持っています。
X にインパルスピーク関数、Y に極値関数
TableCurve 3D には、インパルスピーク関数は標準で用意されていません。そこで、ユーザー定義関数 (UDF:User-Defined
Function) として関数を用意します。X 変数でのフィッティングのために、2つのユーザー定義関数を作成します。1つは Y 変数に極値関数を、もう 1つは対数正規分布関数を使用します。
- Process|User
Functions メニューコマンドまたは
 ボタンをクリックします。
ボタンをクリックします。
TableCurve 3D の User Defined
Function ウィンドウが表示されます。最大 15 の関数を登録することができます。
- Read UDF Library ボタンを押して、ユーザー定義関数のライブラリ samplemt.udl を選択して下さい。2つのユーザー定義関数が表れます。
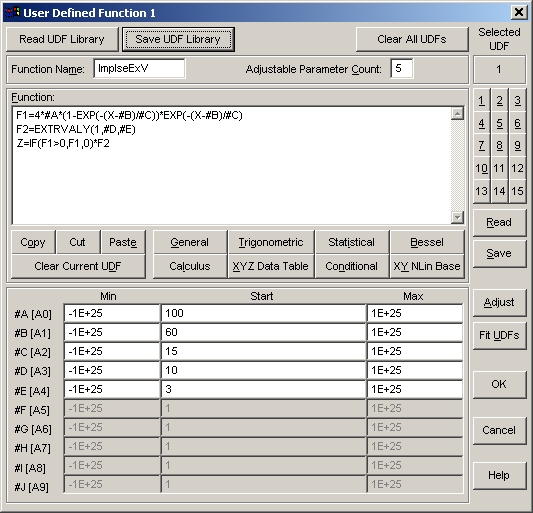
ユーザー定義変数では、調整用のパラメータとして #A、#B、#C、... という書式を使用します。F1 が、X 変数のピーク成分に使用する関数です。F2 は、極値のピークを表すために使用する非線形基底関数で、Y 変数として使用します。ユーザー定義の関数は、X、Y と調整用パラメータを持っています。関数は、F1 から F9 までの番号が付けられます。その他のシンボル名は、定数とみなされます。最後の Z= 式は、条件分岐の
IF() 関数を使用して、負の値がピークに含まれないようにした乗算ピーク関数です。
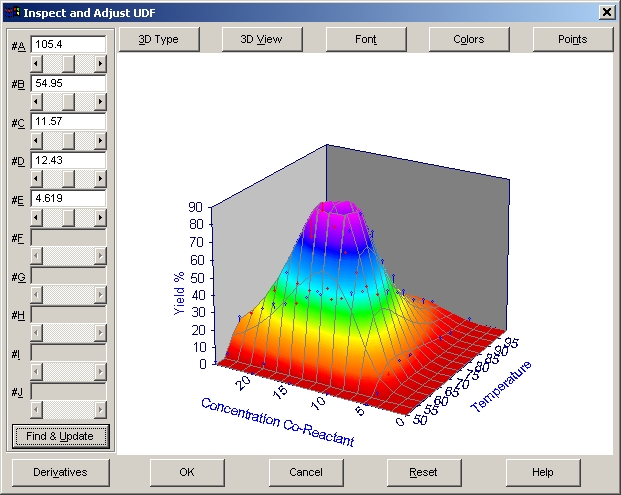
グラフの調整
- Adjust ボタンをクリックして、Inspect and aAdjust UDF ウィンドウを開きます。Find & Update ボタンを押すと、自動的に最適なパラメータ値が選択されます。
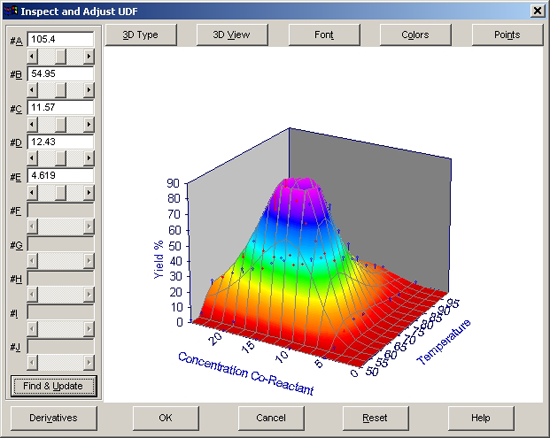
- パラメータ値がアップデートされたら OK ボタンを押します。ユーザー定義関数が変更されたら、グラフもアップデートされます。
Find and Updateオプションは、ポイント数の削減と許容度を落とした非線形フィッティングを行い、計算結果に基づいたパラメータの自動調節を行います。
この機能は、ユーザー定義関数を使ってフィッティングを行うとき、非常に便利です。パラメータ値の推定が速やかに行われれば、最小2乗法に基づいた最小値もスムーズに見つかります。
- パラメータの調整
パラメータの調節を行う際、直接値を入力したり、スライダを動かして設定することができます。スライダの増分は、パラメータ毎に異なります。パラメータの値を変更する度に偏導関数が計算され、XY データの偏導関数の範囲によって増分が決定されます。推定値が離れている場合は偏導関数が小さくなり、そのため増分が大きくなります。このようなときは、パラメータ値は直接入力した方がよいでしょう。
パラメータの推定値を変更しても、その値はユーザー定義関数ライブラリには保存されていません。推定値を保存するには、Save UDF Library ボタンを押さなければなりません。
Read と Save ボタンは、アクティブになっている 1つの関数の保存とインポートを行います。
ここで、2番目の関数を変更してみましょう。Y 変数のピークは、極値よりも対数正規分布関数が向いています。
- Selected UDF セクションにある 2 ボタンをクリックして、2番目のユーザー定義関数に切換えます。
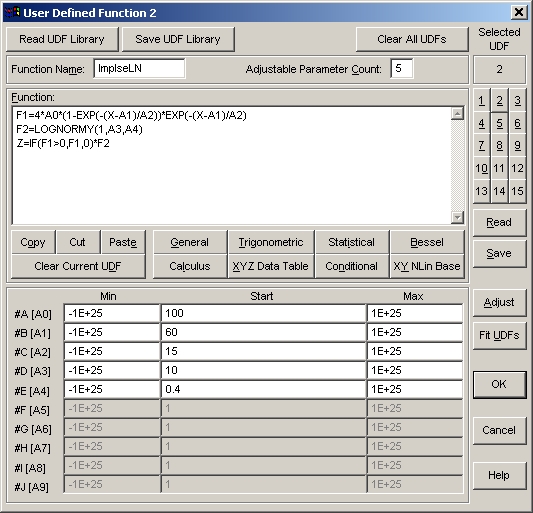
2番目のユーザー定義関数は、パラメータに#A、#B、#C、...ではなくA0、A1、A2、...という書式を使用しています。どちらの書式も使用することができます。このユーザー定義関数と、最初の関数との違いは、F2関数に非線形基底関数として標準の対数正規分布関数を使用していることだけです。
- 制約条件
最初のユーザー定義関数と同様に、最小値と最大値の条件は設定されていません。非線形の最小2乗法の場合は、特定の範囲内で値を推定します。パラメータの値が1つでも条件の境界上にある場合は、最小2乗法は適用できません。
- 最初のユーザー定義関数と同じように、Adjust ボタンを押して Inspect and Adjust
UDF ウィンドウを開き、Find and Update ボタンを押します。パラメータ値がアップデートされたら OK ボタンを押して下さい。パラメータの推定値がよければ、OK ボタンを押してメインメニューに戻ります。
ユーザー定義関数だけのフィッティング
User Defined Function ウィンドウには Fit UDFs ボタンがあり、メインウィンドウには Process|Surface-Fit
User Functions メニューコマンドがあります。どちらもユーザー定義関数だけ使ってフィッティングを実行します。最大 15 ユーザー定義関数でのフィッティングとなりますが、ユーザー定義関数またはディスクに保存したユーザー定義関数ライブラリの数は自由です。
ここでは、インパルスピークをもつユーザー定義関数の有効性を判断するために使用した極値関数と対数正規分布関数のピークも見ることができるようにします。すなわち、これらのピークをもつ関数セットを作成します。Surface-Fit
Custom Equation Set メニューコマンドを含むすべてのフィッティングオプションに、ユーザー定義関数を含めます。
- Process|Edit
Custom Equation Set メニューコマンドまたは ボタンを選択します。Non-Linear
Equations セクションの Clear All ボタンを押し、Peak タイプとして Log-Normal と Extr Value だけスイッチを ON にします。非線形関数の Active な数は 2 になります。Fitボタンをクリックして下さい。
2つのユーザー定義関数と共に、2つの標準の非線形関数のフィッティングが実行されます。数式リストには、4つの関数が表示されます。
- グラフを見るためには、Graph
Start ボタンを押す必要があります。
ユーザー定義関数のサーフェスフィットグラフ
インパルス - 対数正規分布フィッティング
先に Z 変数のスケールを変更しましたが、100% の Yield スケールを保存していないため、再設定が必要となります。
- Scaling ボタンまたはグラフの左または右の Z 軸ラベルの周辺をクリックして下さい。3D Scaling ウィンドウが表示されたら、Z 軸セクションの Auto のチェックボックスを OFF にし、Max に 100、Divs に 10 を入力して OK ボタンを押します。
このモデルでは、最大値は 100% 以上に設定することもできます。
サーフェスがシャープに立ち上がっていますので、もっと写実的なプロットに変更します。すなわち、陰影付きサーフェスプロットのメッシュの数を大幅に増やします。
- プロットの上でマウスクリックをして 3D View Options ウィンドウを開き、Mesh Count セクションの x ボックス内でマウスの右クリックをします。表示されたリストからメッシュ数 240 を選択し、OK ボタンを押します。
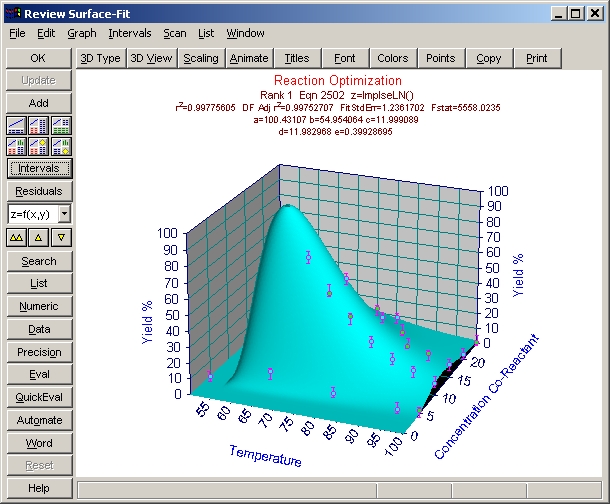
高精細なプロットを見てみると、ピークが理論的最大値の 100%にわずかに接触しているのがわかります。
- Points ボタンをクリックし、Display セクションの Visible Only をチェックし、OK ボタンを押します。
このオプションは、ピークの背後にあって見えないサーフェスのポイントを非表示にします。データポイントは、サーフェスのメッシュ上にあります。メッシュ上のポイントには、Z 方向にドロップラインが引かれています。
Visible Only で表示されるポイントは、サーフェスのメッシュ上にあるポイントだけで、実データポイントではありません。サーフェス全体が見える場合は、このオプションには何の効果もありません。
- この Visible Only オプションにより、ピークのインパルス成分のシャープな立ち上がりはごくわずかなポイントによって作られていることが明らかになります。通常は、すべてのポイントを使用するのがよいでしょう。表示されないメッシュ上のポイントは描かれないので、Visible
Only は高速であり、外れ値を見失うこともありません。
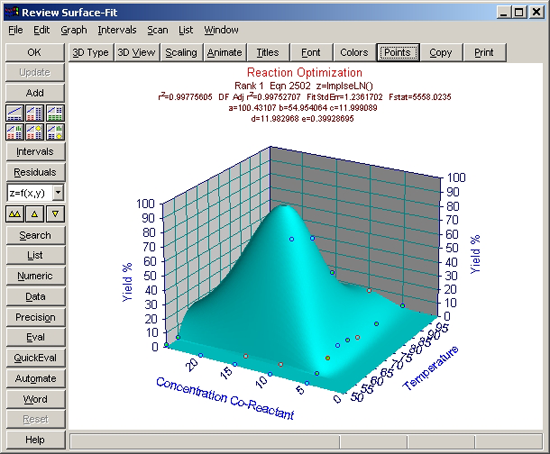
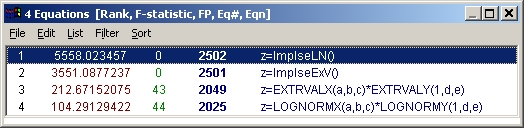
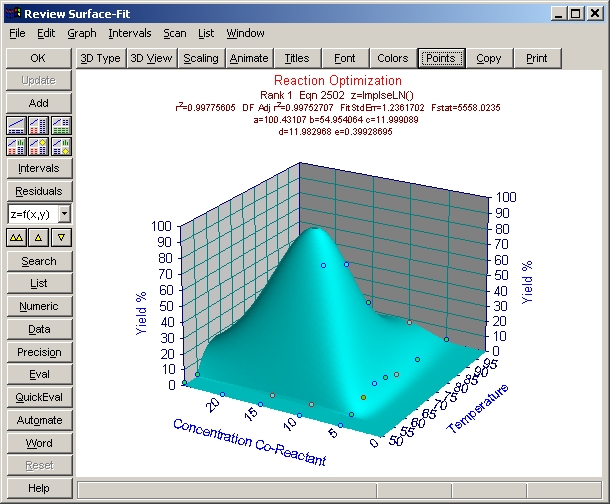
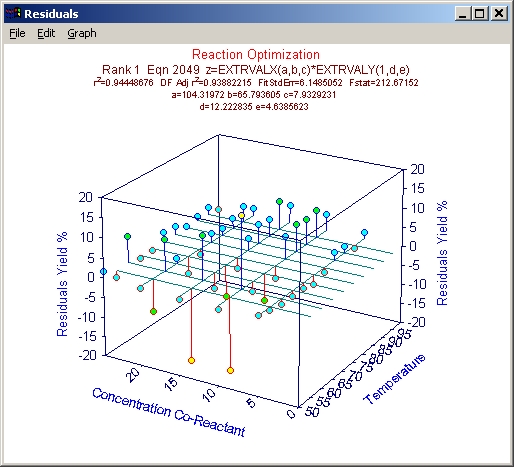
ユーザー定義関数を使ったら、F統計量が非常によくなったことに注意して下さい。X 成分のインパルスピークが、フィッティングをよくしています。r2 も、もっともよいユーザー定義関数の方は 0.997 です。
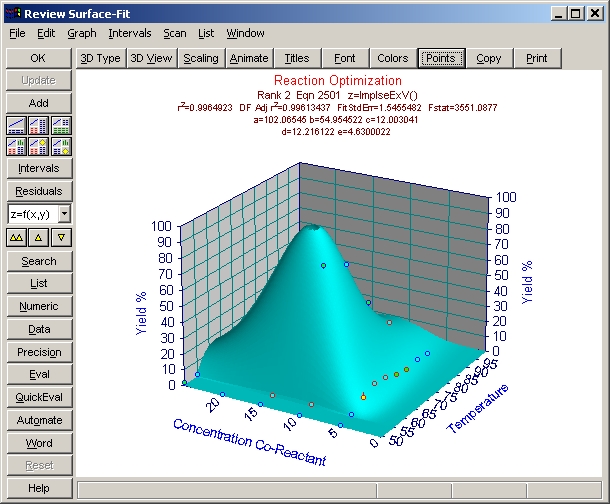
インパルス - 極値ピーク関数もよい結果が出ているのですが、データに対するモデルの適合のよさを示す F 統計量では、インパルス - 対数正規分布関数の方がよくなっています。
インパルス - 極値フィッティング
- Review Surface-Fit ウィンドウの下向き矢印ボタンをクリックして下さい。
これで 2番目のインパルス - 極値ピークユーザー定義関数が選択されます。サーフェスのピークは、明らかに理論値の 100%を超えています。このモデルの r2 は、0.996 です。
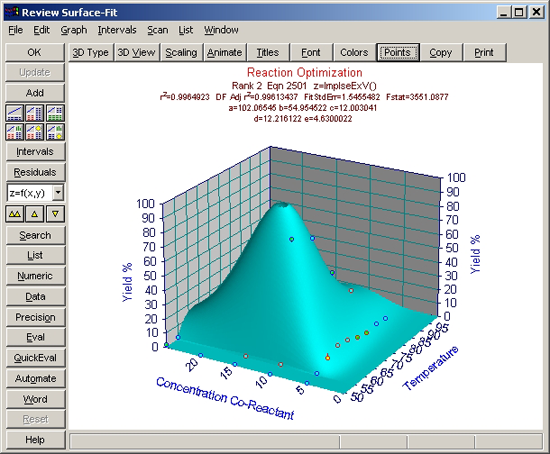
残差グラフ
- Residuals ボタンをクリックします。
- Residuals ウィンドウの Graph|Residulals Surface Graph オプションを使用します。
- Residuals ウィンドウの Graph|Select 3D View メニューコマンドをクリックします。3D View Options ウィンドウの XY view
angle を 270、Z view angle を 90、Perspective セクションの Level を 0、Set in
Frame を 0.85 に設定し、OK ボタンを押します。
- 矢印ボタンまたは数式リストを使って、4つの関数の残差を比べてみて下さい。
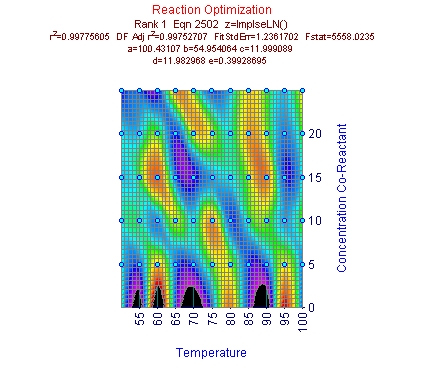
等高線プロットを見てみると、標準の関数を用いたピークモデルの残差は、偏りがあることがわかります。それに対して、極値関数を用いたユーザー定義関数は偏りが改善されています。対数正規分布関数を用いたユーザー定義関数の方は、さらに残差のバラツキが十分な状態になっています。
- Graph|3D View メニューコマンドをクリックし、Reset ボタンを押してから OK ボタンをクリックして下さい。Residuals ウィンドウは終了します。
予測区間
- 数式リスト最上位のユーザー定義関数 ImpulseLN を選択して下さい。
- Intervals メニューをクリックし、Prediction と 99% 区間を選択して下さい。
- 3D View ボタンをクリックし、Reset ボタンを押した後、XY
view angle を 290 にして OK ボタンを押して下さい。
予測区間は、サーフェス全体にほほ一定の間隔で表示されています。
サーフェスフィットグラフのアニメーション
- Animate ボタンをクリックし、Vary (回転方向) セクションで XY を選択し、Start を 5、End を 360、Incr (増分) を 5 に設定します。OK ボタンを押すと Animate
View ウィンドウが表れますので、Start ボタンを押して下さい。データとサーフェスの様子を様々な方向から観察することができます。Stop ボタンを押すとアニメーションが停止し、End ボタンでウィンドウが閉じます。
- 3D Type ボタンを押し、Reset ボタンを使ってデフォルトグラデーションのプロットに戻します。
- 3D View ボタンを押し、Reset ボタンを使ってデフォルトの視野に戻します。
- Points ボタンを押し、Reset ボタンを使ってデフォルトのすべてのポイント表示に戻します。
- Intervals ボタンを押して、予測区間を非表示にして下さい。
ユーザー定義関数フィッティングの数値データ
最後に、数値的なデータを見てみましょう。
リアルタイムでの評価
TableCurve 3D は、サーフェス内の最小最大値を捜し出すのに便利な機能を有しています。
- QuickEval ボタンを押し、Surface Max ボックスにチェックを入れます。4つのフィッティング関数を気鋭変えて下さい。それぞれの Z 最大値と位置が表示されます。
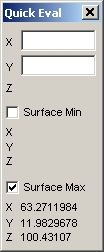
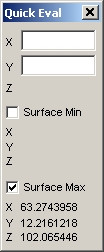
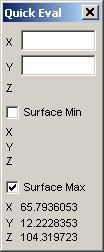
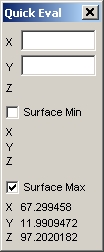
このチュートリアルの最終目的は、反応の最大値が得られる最適条件、すなわち最適な温度と共反応濃度を見つけ出すことです。最もよいフィッティング関数を使った場合、温度 63.3 度、濃度 12.0 が最適条件となります。2番目によいフィッティング関数を使った場合は、
63.3 度、濃度 12.2 です。
- 再度 QuickEval ボタンを押して、Quick Eval ウィンドウを閉じて下さい。
統計情報
パラメータに関して、その値や標準誤差、信頼区間、極値などを一覧表示することができます。
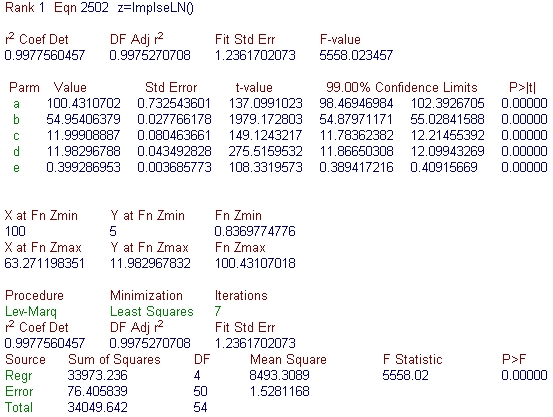
ユーザー定義関数の最大値、最小値をそれぞれ個別に入手することができることを示すため、わざわざ中央値を使わずにインパルスピーク関数のパラメータを設定しました。インパルスの中央は、実際には a1+a2*ln(2) となります。
- 数式リスト最上位のインパルス - 対数正規分布関数を選択して、Numeric ボタンを押して下さい。統計情報は、この最上位のユーザー定義関数のものです。
- データを見終わったら、Numeric Summary ウィンドウを閉じて下さい。
- 最適値の分析
対数正規分布の中央値 d は、11.983 です。同様に Y at Fn Zmax の値も、11.983 であることに注目して下さい。これにより、共反応の最適濃度は基本的に 12.0 であると判断できます。インパルスの中央値 b は、54.95 です。ただし、X
at Fn Zmax は 63.27 となっています。明らかにインパルスピークのパラメータは、Z の最大値中央を提示していません。ここで、ピーク中央は b+c*ln(2) すなわち 63.27 であることがわかっていますので、最適温度が 63.3 度であるか確認しましょう。
インパルスピークは、真の中央値と b の値が一致しないと、統計的な意味を持ちません。すなわち、さらにユーザー定義関数を吟味する必要があります (ヒント:ユーザー定義関数 F1 のパラメータ A1 を A1-A2*LN(2) で置換えてみましょう) 。こうすると、X
at FnZmax の値と b の値が一致します。
統計情報でレポートされているサーフェスの最大最小と QuickEval の最大最小は、局所的な最大最小値でなく、2次元の最小化アルゴリズムを用いて算出した値です。これらの値は、注意深くサーフェスを観察するときに役に立ちます。
この例で、もっと t-値が大きいのは 2つの中央値で、これらはゼロであることが認められないパラメータです。この位置では、非常によい 99% 信頼区間が得られます。
データ情報
- Click the Data ボタンをクリックし、Temperature (X) が 65,
Concentration (Y) が 10 のポイントの Z 値が 88%、Z 予測値が 89.0%であることを確認して下さい。

- 確認し終えたら、Data Summary ウィンドウを閉じて下さい。
このデータセットは 55 の反応サンプルで構成されており、50%を超える値をもっているのは 8 サンプルだけなので、最適値は (65, 10) の位置で 88~89%とういう結論は受け入れやすいかもしれません。サーフェスフィッティングは、厳密に最適値を導いてくれます。すなわち (63.3,
12) で、最もよい値が得られます。
許されるなら、(63.3,
12) を中心としてさらに狭い範囲のデータを集めてみるとよいでしょう。
評価
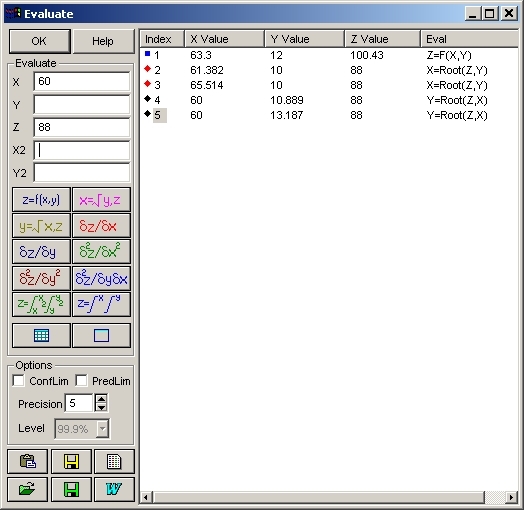
- (63.3, 12) が理想的な値であることを確認するために Eval ボタンをクリックし、Evaluate ウィンドウの X に 63.3、Y に 12 を入力して下さい (他はすべて空欄です) 。Z=F(X,Y) ボタンを押すと 100.4% と計算されます。
- 最適値の周りの状況を見るために、X に 60、Z に 88 を入力し、Y=Root at Z,X ボタンを押します。2つの計算結果が表示されます。濃度 (Y) が 11 と 13 で、11 は実験値の 10 に近い値です。
- つぎに Z は 88 のままで Y に 10 を入力し、X=Root
at Y,Z ボタンを押します。61.4 度と 65.5 度が計算され、後者は実験値の 65 度に近い値です。
- 結果的な外挿 (Partial Extrapolation)
(63.3, 12) がデータの XY 範囲内にあっても、その Z 予測値がデータセットのどこにも見当たらない場合は、意味がありません。90 また 95%の上に限界があって、この実験データにはそれが表れていないのかもしれません。この場合、外挿を行っているわけではありませんが、結果的に最適値がデータ範囲を超えて外挿のような形になってしまったのです。最大値、最小値の最適化の場合、これは常に発生する問題です。したがって、推定値の確認のためにさらに実験データを得ることが必要となります。
- Evaluate ウィンドウの OK ボタン (または Review Surface-Fit ウィンドウの Eval ボタン) を押して、Evaluate ウィンドウを閉じます。
- Add ボタンを押して、このサーフェスフィッティングを TableCurve
3D ノートブックに追加します。
- Review Surface-Fit ウィンドウの OK ボタンを押して、メインウィンドウに戻ります。
サーフェスフィッティングの出力
TableCurve 3D は、サーフェスフィッティングを行うためのすべての情報を保存していますが、フィッティングの結果はすべて保存していません。メインウィンドウのグラフをクリックし、サーフェスフィッティングのグラフが表示されていれば、前回と同じ条件でフィッティングが実行されますので、再実行して下さい。
- ノートブックのサーフェスフィッティングアイテム
 を選択し、メインウィンドウのグラフ中央をクリックして下さい。
を選択し、メインウィンドウのグラフ中央をクリックして下さい。
TableCurve 3D ノートブックに保存したときのサーフェスフィッティングの状態で、Review
Surface-Fit ウィンドウが表示されます。数式リストも同じものが表示され、フィッティングオプションも同じです。グラフの設定も同じになります。
- Review Surface-Fit ウィンドウの OK ボタンを押して、メインウィンドウに戻って下さい。
注釈アイテム
XYZ データのノードに、注釈アイテム  を追加することができます。
を追加することができます。
- ノートブックの XYZ アイテムを選択し、マウスの右クリックをしてポップアップメニューを開きます。メニューの中から Annotate を選択し、テキストを入力あるいは統計情報をコピー&ペーストして、ウィンドウを閉じます。
注釈アイテムを選択すると、その内容はメインウィンドウの統計セクションに表示されます。Edit|ASCII Editor メニューコマンドを使って、注釈を簡単に編集することができます。
TableCurve 3D の終了
- TableCurve 3D のメインウィンドウを閉じるか、File|Exit メニューコマンドをクリックすると、終了します。