ヒューリンクステクニカルサポート
更新日:
14/04/15
1. 近似関数のフィッティング
- 近似関数と平方根
- 外挿
- 微分と積分
- 線形モデル
- TableCurve 2D のデータテーブル
- 計算
- データの選択
- 自動処理
- TableCurve 2D のフィッティングをカスタマイズ
- 線形近似式でのフィッティング
- Review Curve-Fit ウィンドウ
- バランスのよい近似式 #6204
- シンプルな近似式フィルタ
- 導関数(Derivative)フィルタ
- 浮動小数点型データと実行速度
- 標準誤差 SE によるデータポイントの色分け
- 信頼区間と予測区間
- 近似式の検索
- 参照曲線
- 近似関数の評価
- 出力オプション
- タイトルのカスタマイズ
- プリンタの設定
- グラフのプリント
- プログラミングコード生成
- スプレッドシートへのエクスポート
- SigmaPlot Output
- TableCurve 2D の終了
1. 近似関数と平方根
近似関数とは、XY 離散データにどのような傾向があるかを示すためのものです。近似関数は、補間すなわち X 値の範囲内の Y 値あるいは X 値平方根や、Y 値の範囲内の Y 値平方根を求めるときに使用されます。
2. 外挿
近似関数はまた、外挿すなわち X 値の範囲外の Y 値あるいは X 値平方根や、Y 値の範囲外の Y 値平方根を求めるためにも使用されます。
3. 微分と積分
近似関数を微分あるいは積分すると、カーブ下の面積や変曲点、累積面積など元データの特徴を正確に知ることができます。近似関数はまた、時系列データの平滑化にも使用されます。
4. 線形モデル
近似関数の選択では、よく当て嵌まるかよりも、フィッティングしやすいことの方が重視されます。やたら係数の数を増やすことは、好まれません。そのため近似関数としては、線形モデルがもっともよく使用されます。したがって以下の例でも、主に線形モデルを使用します。
5. TableCurve 2D のデータテーブル
- TableCurve 2D を起動して下さい。
TableCurve 2D を起動したら、最初に XY データテーブルを作成します。以下のファイルのどれかを開くと、データテーブルが作成されます。
- ASCII files [X-Y, single column, multi-column]
- Excel v3-v5,95,97,2000 spreadsheet files [XLS]
- Lotus 123 spreadsheet files [WK4, WK3, WK1, WRK, WKS]
- Quattro Pro spreadsheet files [WB2, WB1, WQ1, WKQ]
- SigmaPlot worksheet Files [JNB, SPW, SP5, SPG]
- SPSS v8-v10 data files [SAV]
- Systat v8,v9 data files [SYS]
- dBASE III+ and dBASE IV database files [DBF]
- DIF files [X-Y, single column, multi-column]
- Binary files with repeating data blocks [with binary configuration]
- X-Y Data entered directly into the TableCurve or ASCII editors
|
TableCurve 2D のデータテーブルの最大サイズは 65536 行で、これを超えるデータに対して (最大 6500 万ポイント) 、複数のポイントの平均をとって代表値とし、ポイント数を減らす平均化フィルタ (File|Import Digital Filter) をかけることができます。
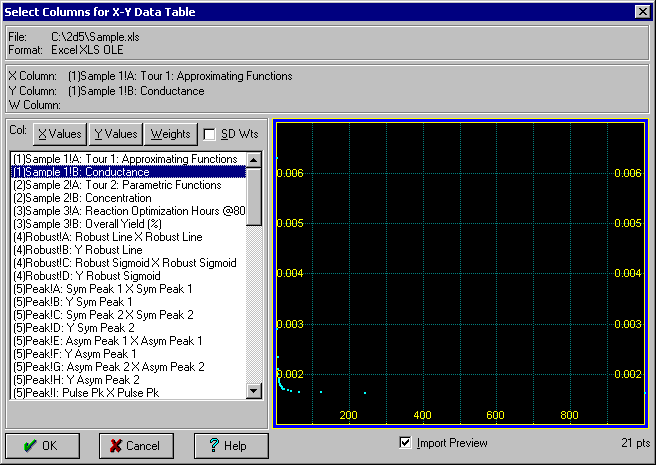
 File|Import メニューコマンドを選択し、ファイルの種類ドロップダウンリストで Excel [xls] 形式を指定して、SAMPLE.XLS を開いて下さい。
File|Import メニューコマンドを選択し、ファイルの種類ドロップダウンリストで Excel [xls] 形式を指定して、SAMPLE.XLS を開いて下さい。
データ列の判別をしやすくするために、TableCurve 2D はワークシートの最初の 100行分の文字列データをリスト表示します。少なくともその中の 1つを選択しなければなりません。
- TableCurve 2D データテーブルの X-variable として、最初の Tour 1: Approximating Functions Temperature を選択して下さい。
- Y-variable には、Conductance を選択して下さい。Import Preview チェックボックスを ON にすると、インポートするデータのグラフを表示してくれます。
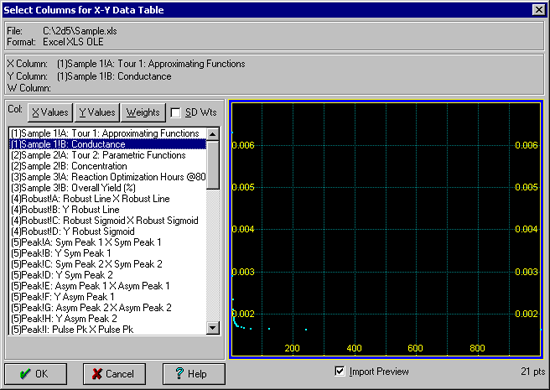
注意:最初に選択した 2列は、自動的に XY データとして読み込まれます。リストの列名をダブルクリックするだけで、選択することができます。XY 変数の列は、重み Weights の列を選択するのと同じように、変更することができます。Weights の列は、複数のY列データの標準偏差として使用することもできます。
- 選択が終わったら、OK ボタンを押します。データ列名を編集するダイアログ現れますので、もう一度 OK ボタンを押して下さい。
選択した列データが読み込まれ、その概要が表示されます。データポイント数は 21 点です。
データをインポートすると、 Process|Background Thread Processing で設定された方法で、自動的にフィッティングが実行されます。ここでは、自動フィッティングは無視します。
Process|Background Thread Processing で設定された方法で、自動的にフィッティングが実行されます。ここでは、自動フィッティングは無視します。
データをインポートすると、基本統計情報を得るために TableCurve 2D はデータの事前スキャンを行います。そして、グラフといっしょにウィンドウに表示されます。
6. 計算
Y-values の単位は、ミリ mho です。ここでは、マイクロ mho に単位を変換します。
-
 Data|Enter Calculation メニューコマンドを実行します。Y= のフィールドに Y*1000 と入力して OK ボタンを押し、続いて計算結果を直ちにデータテーブルに反映させるため、はいを選択します。
Data|Enter Calculation メニューコマンドを実行します。Y= のフィールドに Y*1000 と入力して OK ボタンを押し、続いて計算結果を直ちにデータテーブルに反映させるため、はいを選択します。
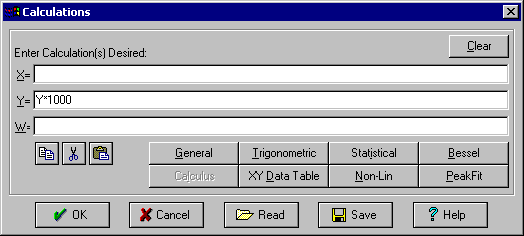
すると、TableCurve 2D の Undo グラフが表示さます。このグラフは、計算結果を反映する前に、視覚的にそれが正しいか確認するためのものです。
- OK ボタンを押すと、Y-value の変換が終了します。
7. データの選択
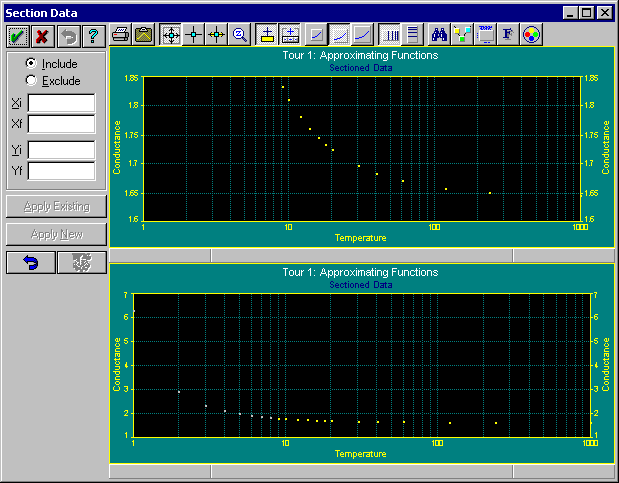
 Data|Section Data メニューコマンドを選択します。
Data|Section Data メニューコマンドを選択します。
- グラフのツールバーにある Logarithmic X Axis ボタン
 をクリックします。
をクリックします。
このデータから、絶対 0 度近辺まではコンダクタンスはだいたい一定であることがわかります。実験データとしては 1°K が観測できる下限であるため、絶対 0 度付近の値は外挿によって求めることになります。
個々のデータポイントは、その上でマウスを左クリックすると ON/OFF を切換えることができます。
 X-Sectioning Mode にすると、マウスカーソルをグラフ上の一点において左クリックし、そのまま右側にドラッグしてマウスボタンを離すと、その範囲内のデータポイントが OFF になります。同じことを右側から左側に行うと、その範囲内のポイントが ON になります。
X-Sectioning Mode にすると、マウスカーソルをグラフ上の一点において左クリックし、そのまま右側にドラッグしてマウスボタンを離すと、その範囲内のデータポイントが OFF になります。同じことを右側から左側に行うと、その範囲内のポイントが ON になります。
 XY Sectioning Mode は、上側のグラフで特定の XY 範囲の ON/OFF を指定するために使用します。矩形の開始点でマウスの左ボタンをクリックし、そのまま選択したい範囲までマウスをドラッグしてボタンを離すと、その範囲のデータポイントのみが ON になります。マウスの右ボタン (左ボタン以外のボタン) をクリックして同じことを実行すると、その範囲のデータポイントが OFF となります。
XY Sectioning Mode は、上側のグラフで特定の XY 範囲の ON/OFF を指定するために使用します。矩形の開始点でマウスの左ボタンをクリックし、そのまま選択したい範囲までマウスをドラッグしてボタンを離すと、その範囲のデータポイントのみが ON になります。マウスの右ボタン (左ボタン以外のボタン) をクリックして同じことを実行すると、その範囲のデータポイントが OFF となります。
上側のグラフは、ON とされたデータポイントを表示するためにスケールが調整されます。下側のグラフは、データポイントの ON/OFF に関係なく、すべてのデータポイントを表示します。
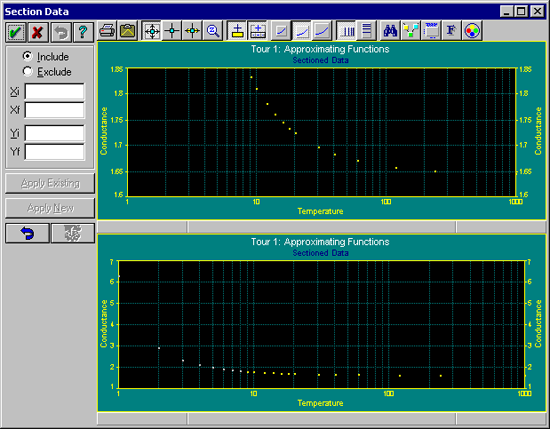
- データ範囲を ON/OFF して、個々のデータポイントの状態を変更してみてください。
 Cancel ボタンを押すと、データの選択をキャンセルできます。すべてのデータポイントを使ってフィッティングを行いますので、このボタンをクリックして下さい。21 ポイントを表示したウィンドウに戻ります。
Cancel ボタンを押すと、データの選択をキャンセルできます。すべてのデータポイントを使ってフィッティングを行いますので、このボタンをクリックして下さい。21 ポイントを表示したウィンドウに戻ります。
8. 自動処理
TableCurve 2D は、3491個の線形近似関数、174個の非線形近似関数を標準で用意しており、これを使って 1ステップでデータテーブルのフィッティングを行うことができます。
処理時間は使用する関数によって異なり、コンピュータの浮動小数点演算スピードに依存します。TableCurve 2D では、浮動小数点の指数部 (Floating Point Index:FPI) をウィンドウに表示します。IBM AT 互換コンピュータの FPI 処理能力を 100 とすると、その値が 50000 のコンピュータは、AT 互換機に対して 500 倍処理速度が速いということになります。
TableCurve 2D の Help|List Equations メニューコマンドをクリックすると、搭載している3665個の近似関数の一覧が表示されます。
9. TableCurve 2D のフィッティングをカスタマイズ
TableCurve 2D では、様々なカスタマイズを行うことができます。
 Curve-Fit Peak Functions、
Curve-Fit Peak Functions、 Curve-Fit Transition Functions、
Curve-Fit Transition Functions、 Curve-Fit Kinetics Equations のオプションメニューをクリックすると、非線形近似関数のオプションを設定することができます。
Curve-Fit Kinetics Equations のオプションメニューをクリックすると、非線形近似関数のオプションを設定することができます。
 Curve-Fit Custom Equation Set は、
Curve-Fit Custom Equation Set は、 Edit Custom Equation Set オプションメニューを使って定義した近似関数を使用してフィッティングを行うことができます。
Edit Custom Equation Set オプションメニューを使って定義した近似関数を使用してフィッティングを行うことができます。
Peak、Transition、Kinetic 関数以外は、 Curve-Fit Preferences オプションメニューを使って設定のカスタマイズができます。
Curve-Fit Preferences オプションメニューを使って設定のカスタマイズができます。
- Process|Curve-Fit Preferences メニューコマンドまたは ボタンを選択して下さい。
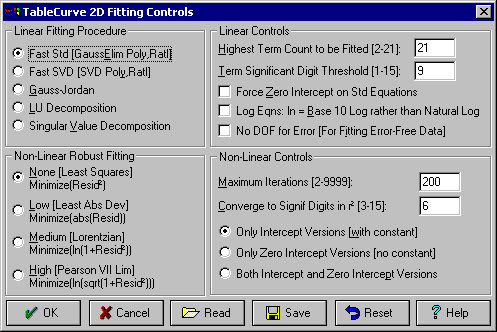
フィットの最大項数 Highest Term Count to be Fitted は、すべの近似関数に対して 21 がデフォルト設定になっています。項の有効閾値 Term Significant Digit Threshold の設定値 9 は、y 値に対して 1E-9 以上の効果がある場合、項として関数に加えられることを意味しています。強制ゼロ切片 Force Zero Intercept on Std Equations オプションは、TableCurve 2D の 3205 個の標準線形関数 (多項式関数、有理関数ではないもの) でフィッティングする際、原点を通過させるためのものです。
その他、常用対数の使用、誤差なしデータの作成すなわちフィット時の誤差の自由度を無効にするオプションがあります。
Fast Std 線形フィッティング法は、解ベクトル (係数) と逆行列 (誤差と信頼区間) の両方を用いてフィッティングを行います。最も早いフィッティング法です。Fast SVD 法は、高次の多項式および有理式のフィッティングに特異値分解を使用するのを除けば、よく似た手法です。概して安定した係数を求めることができます。行列について知識をもっているならば、またすべての処理に同一の手法を採用したいならば、その他のオプションを選択することもできます。
- OK ボタンを押して、設定ダイアログを終了して下さい。
10. 線形近似式でのフィッティング
チュートリアルでは、標準で用意された線形近似関数を用いてフィッティングを行います。まず、自動カーブフィッティングを行ってみましょう。
 Process|Curve Fit Linear Equations オプションを選択して下さい。
Process|Curve Fit Linear Equations オプションを選択して下さい。
カーブフィットが自動的に実行されます。このとき、Process|Curve-Fit Preferences|Cancel ボタンを押すと自動フィッティングをキャンセルすることができます。自動フィッティングでは、まず総和 Sums を計算します。そのあと、 3491 個ある線形近似関数の処理が続きます。
フィッティングが終了したら、2100個以上の近似関数がフィッティングセットに加えられています。
- フィッティングが終わったら、Graph Start ボタンを押して Review Curve-Fit ウィンドウで結果を見て下さい。(近似式リストが表示されていない場合は、ウィンドウ左側に並んだボタンのうち、Equation List が表示できるボタン
 のどれかをクリックして下さい。)
のどれかをクリックして下さい。)
あるいは、OK ボタンを押してから Review|Graph Start メニューコマンドをクリックしても結構です。フィッティングが終わって何の操作もせず 10秒が過ぎると、自動的にフィッティングの Review Curve-Fit ウィンドウが表示されます。
11. Review Curve-Fit ウィンドウ
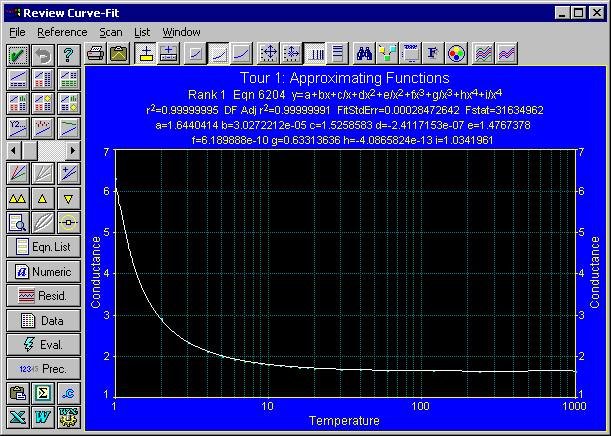
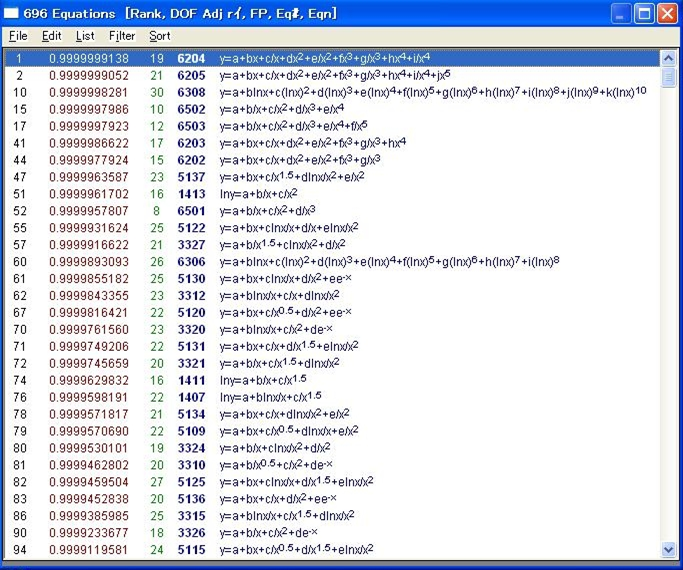
フィッティング結果には、効果のない項をもつ近似式は除外されています。フィッティングができなかった近似式も、除外されています。たとえば、データセットが負の X 値を持たない場合は、ln(x) の項を持つ近似式は意味がありません。
- Review Curve-Fit ウィンドウのツールバーにある Logarithmic X Axis ボタン を押して下さい。
- Review Curve-Fit ウィンドウの List メニュー、または Equation List ウィンドウの Sort メニューから Sort by DOF Adjusted r2 を選択して下さい。
これは、自由度調整決定係数によって、フィッティングがよい回帰式順にソートしています。近似関数を評価する場合、自由度(標本の大きさ)を考慮した最小2乗法を用いる DOF Adjusted r2、または Fit Std Error でソートするとだいたいよい結果が得られます。
近似式リストの一番上に表示された #6204 が、もっともバランスのよい多項式です。Review Curve-Fit ウィンドウには、その近似関数によるフィッティング結果がプロットされます。
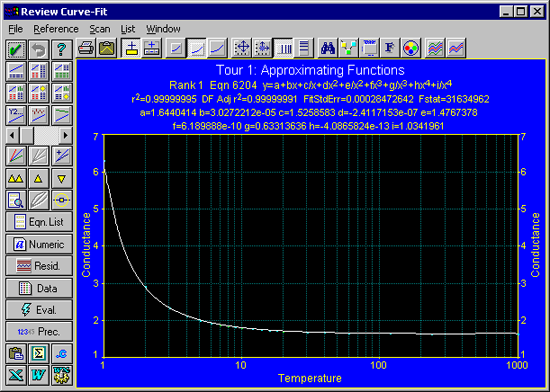
データセット毎にフィッティング可能な近似関数の候補を選び、その中でもっともよく適合するものを選択します。ここで注意していただきたいのは、近似式リストには標準で用意されているものより少ない式がリストされます。欠けているのは有理式で、デフォルトの Rationals Defined Xmin-Xmax オプションで定義された x 範囲内に、データがない、あるいは極があるものです。そのような有理式は無意味です。用意されたすべての近似式が表示されるのは、フィットする前だけです。
次に、外挿のためのスケールを設定しましょう。
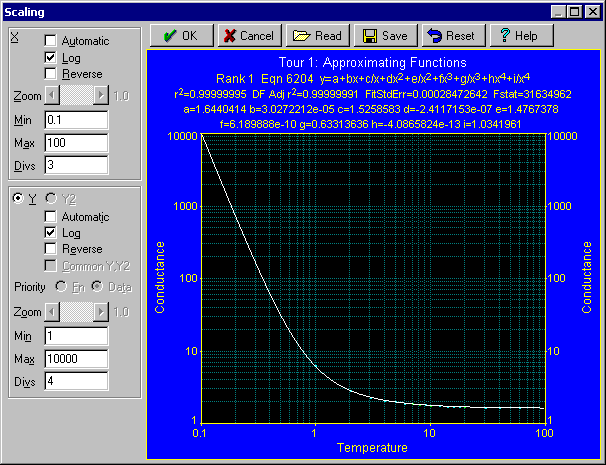
- グラフツールバーにある Modify Graph Scaling ボタン
 をクリックします。X 軸設定セクションの Automatic チェックボックスを OFF、Log チェックボックスを ON、最小値 Min を 0.1、最大値 Max を 100、仕切数(=冪乗数)Divs を 3 に設定して下さい。 Y軸設定セクションでは、Log チェックボックスを ON、Automatic チェックボックスを OFF、最小値 Min が 1、最大値 Max は 10000、仕切数 Divs を 4 にして下さい。
をクリックします。X 軸設定セクションの Automatic チェックボックスを OFF、Log チェックボックスを ON、最小値 Min を 0.1、最大値 Max を 100、仕切数(=冪乗数)Divs を 3 に設定して下さい。 Y軸設定セクションでは、Log チェックボックスを ON、Automatic チェックボックスを OFF、最小値 Min が 1、最大値 Max は 10000、仕切数 Divs を 4 にして下さい。
グラフは以下のように表示されるはずです。
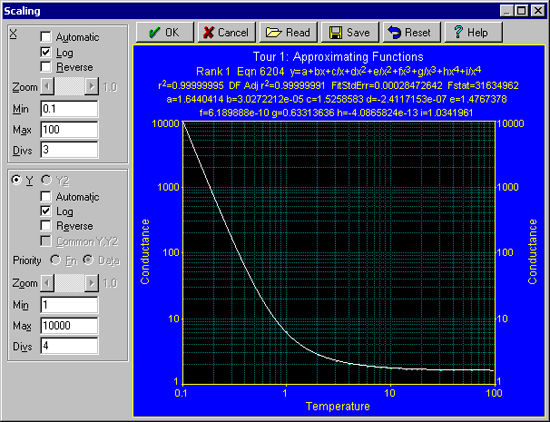
- スケールの設定がよければ、OK ボタンを押します。
12. バランスのよい近似式 #6204
リストの最上位の近似式が、もっともバランスのよい多項式となります。そのような多項式は、通常、整式の項目と逆数の項目をもっています。その次の 2つの近似式も、バランスのよい多項式です。その下の 5つの近似式は、制約条件をもった非線形の有理式モデルとなっています。
- 近似式リストで、上位 15 の近似式を観察して見て下さい。
- Review Curve-Fit ウィンドウ左側のコントロールパネルにある 矢印ボタン


 を使って、近似式リストでの移動が行えます。
を使って、近似式リストでの移動が行えます。
- 近似式リストがアクティブになっている場合は、キーボードの矢印キーを使って、同様に移動することができます。
- Review Curve-Fit ウィンドウがアクティブになっており、スクロールホイール付きのマウスを使用している場合は、ホイールを使って近似式を移動することができます。
注意:3番目に挙げた近似式のグループには、グラフに緑色の垂直線が描かれています。これらの線は、未定義の状態あるいは算術エラーとなるデータ範囲を表しています。以下の近似式では、対数スケールに対して負の値となる部分が表示されています。
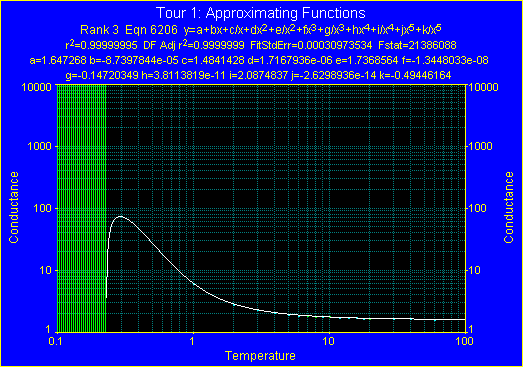
13. シンプルな近似式フィルタ
今回は、線形の近似式のみをリストアップするメニューコマンドを使用しました。この中でもさらにシンプルな 2変数線形近似式で、どれぐらいのフィットが行えるのか見るために、フィルタを適用してみましょう。
- Review Curve-Fit ウィンドウの List メニューまたは Equations ウィンドウの Filter メニューで、Simple Equations オプションを選択して下さい。
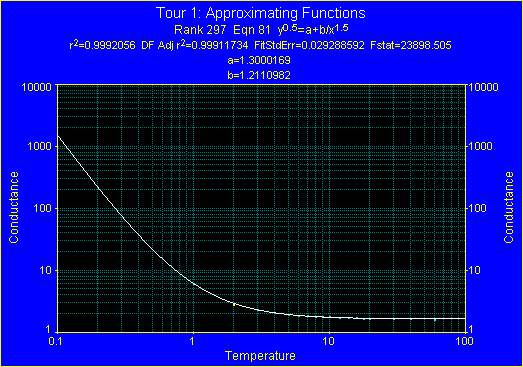
自由度調整決定係数 DOF adjusted r2 を使いながら、300 あまりの近似式に絞られましたが、シンプルな 2変数モデルでもなかなかよいフィッティングが実現できます。
14. 導関数(Derivative)フィルタ
本例で必要としているは、外挿の範囲において増加傾向を示す曲線が出る近似式です。
- Review Curve-Fit ウィンドウの List メニューまたは Equations ウィンドウの Filter メニューで、Set X-Range for Derivative Filtering オプションを選択し、Derivative Scan Filter ダイアログで Minimum X for Derivative Scan に 0.1、Maximum X for Derivative Scan に 100 を入力して下さい。そして Logarithmic Intervals チェックボックスを ON にして OK ボタンを押して下さい。
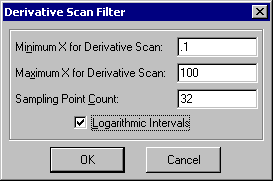
このダイアログによって、Continuous Trend First Derivative と Constant Sign in First Derivative フィルタの条件が設定されましたが、自動的にフィルタは適用されません。
- Review Curve-Fit ウィンドウの List メニューまたは Equations ウィンドウの Filter メニューで、Continuous Trend First Derivative オプションを選択して下さい。
2100 の近似式の 1つ 1つに対して、設定した範囲内で連続的に増加または減少する傾向があるかどうか判断するために、32 の X 値を使って1次導関数を計算するため、わずかながら計算時間がかかります。
フィルタ処理が終わると、リストにあるのは 696個の近似式になっているはずです。最初のトップ 2つの近似式は、そのままリストに残っています。このリストに表示されているのは、すべての近似式に対してフィルタリングした結果が表示されています。最初に表示された上位 25 の近似式のうち、5つの近似式のみが、外挿した範囲で望ましいフィッティングとなります(近似式リストの File 列の番号でそれが確認できます)。
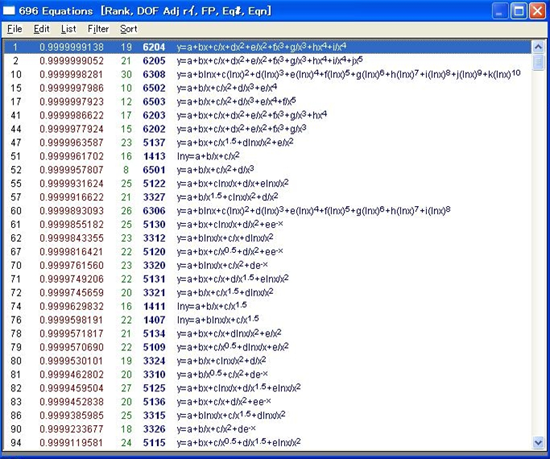
- ここにリストされた近似式はすべて、外挿に適した特性を有しています。再度、最上位ランクの近似式に戻って下さい。
15. 浮動小数点型データと実行速度
TableCurve 2D のオプション設定に基づいた生成された近似式は、それぞれ浮動小数点演算の複雑さ、すなわち計算速度に違いが生じます。近似関数の場合、係数が少ない関数よりも、シンプルな関数の方が演算速度は速くなります。TableCurve 2D は、15桁または 18桁の精度をもつ実行コードを自動生成します。1つの浮動小数点型データは、1つの浮動小数点演算ユニット(FPU)に割り当てられます。45 の浮動小数点型データをもつ近似式は、15 の浮動小数点型データをもつものよりも、3倍計算時間がかかることになります。パラメータの数によって、実行速度に大きな違いが出ることに注意して下さい。
16. 標準誤差 SE によるデータポイントの色分け
残差と標準誤差 SE によって、データポイントが色分けされていることに注意して下さい。デフォルト設定では、フィッティング曲線から 1 SE 以内のポイントは青、1 SE〜2 SE の範囲にあるポイントは緑、2 SE〜3 SE の範囲内は黄、3 SE よりも遠いポイントは赤で色分けされています。
17. 信頼区間と予測区間
信頼区間は、フィッティング曲線の平均の誤差範囲を表します。予測区間は、個々のフィッティング曲線が通る範囲を表します。予測区間は常に、信頼区間よりも幅が広くなります。次の曲線の Y値を推定する予測区間が、最も重要です。
- Review Curve-Fit ウィンドウのツールバーにある Set Confidence/Prediction Intervals, %Confidence ボタン
 をクリックして下さい。Prediction Intervals チェックボックスを ON、Confidence Intervals チェックボックスを OFF にし、99% Confidence にチェックを入れて OK ボタンを押して下さい。
をクリックして下さい。Prediction Intervals チェックボックスを ON、Confidence Intervals チェックボックスを OFF にし、99% Confidence にチェックを入れて OK ボタンを押して下さい。
99% 予測区間は、比較的厳しい条件です。しかしながら、外挿する範囲において幅が十分狭く、実際の曲線にきわめて近くなっています。
18. 近似式の検索
より広い予測区間を調べるため、大きな誤差をもつ 1つの近似式をみてみましょう。
- Search for Specific Equation ボタン
 をクリックし、Equation Number に 17 と入力して OK ボタンを押して下さい。予測区間の広いフィッティング曲線が表示されます。
をクリックし、Equation Number に 17 と入力して OK ボタンを押して下さい。予測区間の広いフィッティング曲線が表示されます。
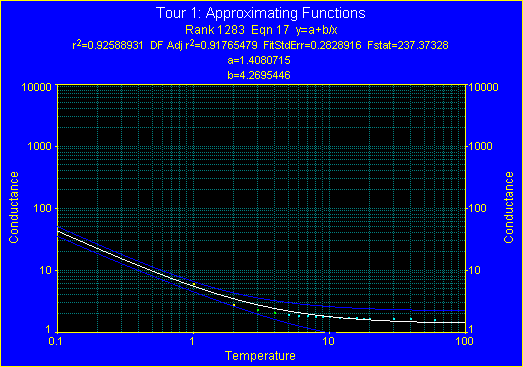
- Show Confidence/Prediction Intervals ボタン
 をクリックして、予測区間を非表示にして下さい。
をクリックして、予測区間を非表示にして下さい。
- トップに戻るボタン を押して、リストのトップに移動します。
区間の計算は、特にX値の範囲外の場合、コンピュータの演算精度に依存します。特定の範囲で信頼区間に誤差が生ずる場合は、その範囲で近似式があまりよく当て嵌まっていないものと考えて下さい。
また外挿の場合は、特に注意が必要です。幅の狭い予測区間は、他の近似式特にリストのランク上位の近似式とはあまり一致しません。
19. 参照曲線
この段階では、近似式 #6204 がフィッティング近似関数として適しているかよりも、絶対零度方向へ外挿した場合、それがどれだけ信頼できるかという問題になっています。どのような外挿でも、データ範囲内の値を使って近似式を導き出しているということを忘れないで下さい。例えばサンプルのデータセットで、観測値のある 1°K 以下の領域で、思いもやらない現象が発生するとしたら、どうなるでしょうか?
外挿がどれだけ信頼できるかを見るために、リストの最高ランクの近似式を参照曲線とします。
- Add Current Equation as Reference ボタン
 または Reference|Add Current Equation as Reference メニューコマンドを選択して下さい。
または Reference|Add Current Equation as Reference メニューコマンドを選択して下さい。
この段階では、参照曲線とカレント曲線は同一です。
- 次に近似式リスト 3番目の #6308 を選択し、Add Current Equation as Reference ボタン をクリックして下さい。
- さらに近似式リスト 5番目の #6503 を選択し、Add Current Equation as Reference ボタン をクリックし、同様に 6番目の #6203 を追加して下さい。
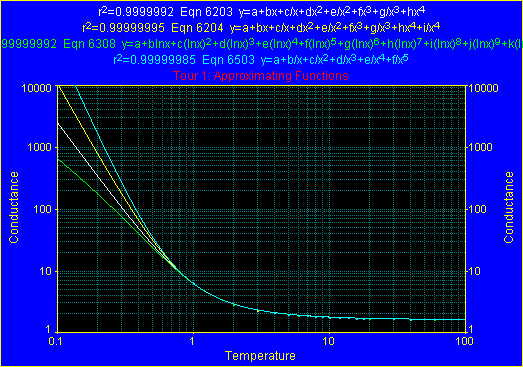
これら4つの近似式の外挿には、かなりの乖離があります。
- ボタンを使って、これら参照曲線と他の近似式の曲線を色々比べてみて下さい。
- 比べ終わったら、 ボタンをクリックしてリスト最上位の近似式 6204 に戻って下さい。
- Toggle Display of Equation References ボタン
 をクリックすると、参照曲線が非表示となります。
をクリックすると、参照曲線が非表示となります。
20. 近似関数の評価
選択している近似式について、数値的な評価を行うことができます。評価テーブルには、すべての計算の履歴を残すことができます。1つ1つ入力する方法と、テーブルに情報を自動的に追加する方法の 2つがあります。
- Eval ボタン
 をクリックして、評価を開始します。
をクリックして、評価を開始します。
- Evaluation セクションの X のフィールドに「.5」を入力し、y=f(x) ボタン
 を押すと、シンプルに近似関数の評価を実行します。
を押すと、シンプルに近似関数の評価を実行します。
- X のフィールドに「.1」を入力し、y=f(x) ボタン を押します。
- また Yのフィールドに「100」、「1000」、「10000」を入力して、それぞれに x=root(y) ボタン
 を押して評価を実行することもできます。
を押して評価を実行することもできます。
- Generate Table ボタン
 をクリックします。Generate Table ダイアログの Data Source は Generate、Write Data に To Evaluation Table、Computation として X is Input, Y=Fn at X を選択して OK ボタンを押します。Generated Data Parameters ダイアログで、Starting Value に「.01」、Ending Value に「1.0」、Increment として「.01」を入力して OK ボタンを押して下さい。
をクリックします。Generate Table ダイアログの Data Source は Generate、Write Data に To Evaluation Table、Computation として X is Input, Y=Fn at X を選択して OK ボタンを押します。Generated Data Parameters ダイアログで、Starting Value に「.01」、Ending Value に「1.0」、Increment として「.01」を入力して OK ボタンを押して下さい。
テーブルに、100 の計算結果が表示されます。
- Generate Table ボタン を再度クリックし、Y is Input, X=Root of Fn at Y オプションを選択して下さい。Starting Value に「100」、Ending Value に「10000」、Increment として「100」を入力して OK ボタンを押して下さい。
100 の平方根をとった結果が追加されます。
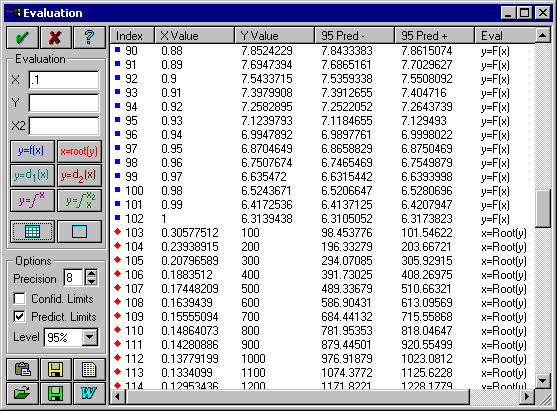
これらのオプションには、ASCII、Lotus、Excel、Quattro、SigmaPlot、SPSS、Systat、dBase、DIF ファイルのデータ列を指定することができます。
Options セクションの Confid. Limits または Predict. Limits がチェックしてある場合、信頼区間または予測区間の列がテーブルに追加されます。
評価の結果は、印刷、クリップボードへのコピー、ファイル(ASCII、Excel、 Lotus、SPSS、Systat 形式)への保存が行えます。またリスト表示し、MS Word で RTF 形式ファイルとして保存することもできます。別のデータセットでも同じ評価が行えるように、評価手順をファイル保存しておくことも可能です。
- ボタンを使って、リスト 2番目の近似式に変更してみて下さい。自動的に評価テーブルも変更されます。リスト最上位の近似式に戻り、OK ボタン(チェックマークのボタン)を押して評価を終了して下さい。
21. 出力オプション
Review Curve-Fit ウィンドウのキーには、それぞれ出力のオプションがあります。近似式リストのウィンドウなどの場合は、ASCII、WK1、RTF ファイルへの保存や MS Word への出力オプションがあります。
 ボタンを使って、カーブフィットのグラフを印刷することができます。Numeric Summary ウィンドウを印刷する場合は、同ウィンドウの File|Print メニューコマンドを使用して下さい。
ボタンを使って、カーブフィットのグラフを印刷することができます。Numeric Summary ウィンドウを印刷する場合は、同ウィンドウの File|Print メニューコマンドを使用して下さい。
Review Curve-Fit ウィンドウでは、以下の出力が可能です。
- カーブフィットの全情報(Excel 様式の近似式)から生成された XY 情報のみのシンプルな 2列のシートまで、3種類の Excel XLS ワークシートファイル
- 12種類のグラフ、カーブフィットの統計情報、元データおよび生成データセクション、Lotus 様式の近似式をもった Lotus WK1 ワークシートファイル
- 出版品質の 4ページ構成の SigmaPlot グラフファイル(変換式を含む)
- カーブフィットグラフの Harvard Graphics chart ファイル
- C、Pascal、Fortran 77 または 90、Visual Basic または Qbasic 形式のプログラムコード
- 信頼区間を含む ASCII 形式ファイル
- データ精度、区切り文字の指定が可能な ASCII ファイル
- フィッティングの共分散行列をもつ ASCII ファイル
- 近似式に基づいた TableCurve 2D の User Defined Function ファイル
22. タイトルのカスタマイズ
メインウィンドウの Edit|Modify Titles メニューコマンドは、データテーブルのタイトルを変更するために使用します。このタイトルは、グラフ以外のすべての出力で使用されます。
Review Curve-Fit ウィンドウの Modify Graph Titles ボタン  は、タイトルをカスタマイズしたいときに使用します。
は、タイトルをカスタマイズしたいときに使用します。
- ツールバーの Modify Graph Titles ボタンをクリックして下さい。X のフィールドの「Temperature」の後に「(K)」、Y のフィールドの「Conductance」の後に「(mho)」と入力して下さい。
- X のタイトルに挿入した「K」の前にマウスのカーソルを置き、Symbol ボタン
 をクリックしてシンボル「 ° 」を選択して下さい。
をクリックしてシンボル「 ° 」を選択して下さい。
- Y のタイトルに挿入した「mho」の前にマウスのカーソルを置き、Symbol ボタン をクリックして「μ 」を入力して下さい。
- Copy ボタン
 と Paste ボタン
と Paste ボタン  を使って、Y2 のフィールドも修正し、OK ボタンを押して下さい。
を使って、Y2 のフィールドも修正し、OK ボタンを押して下さい。
23. プリンタの設定
最後にプリンタの設定を行います。Print Setup ボタン をクリックすると、プリンタの設定が行えます。
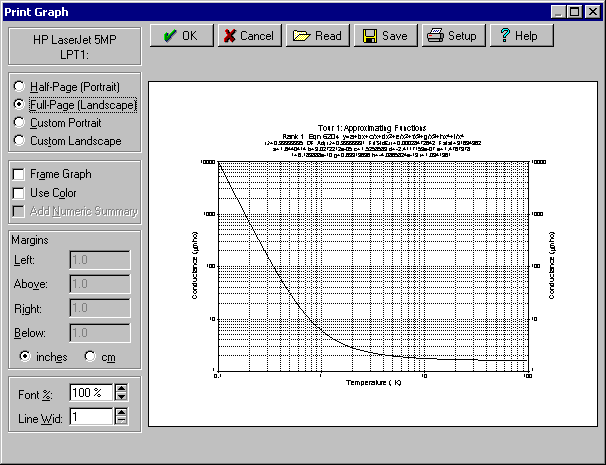
24. グラフのプリント
- Review Curve-Fit ウィンドウのツールバーにある Print Graph ボタン をクリックして下さい。印刷のプレビューが自動的に表示されます。印刷形式とオプションを設定して OK ボタンを押して下さい。
フォントのサイズとラインの太さも設定することができます。
25. プログラミングコード生成
プログラミング言語を何か使用している場合は、TableCurve 2D のコード生成機能が役に立つでしょう。
-
 File|Code Generation メニューコマンドをクリックし、表示されたダイアログで Full Test Code オプションと、プログラミング言語を選択して下さい。関数、サブルーチン、プロシージャとして適した名前を Function Name のフィールドに入力して下さい。OK ボタンを押して、ファイル名 temp を入力して下さい。
File|Code Generation メニューコマンドをクリックし、表示されたダイアログで Full Test Code オプションと、プログラミング言語を選択して下さい。関数、サブルーチン、プロシージャとして適した名前を Function Name のフィールドに入力して下さい。OK ボタンを押して、ファイル名 temp を入力して下さい。
プログラミング言語にてきしたフィアル拡張子が付けられます。ソースコードが生成された後、確認のために ASCII 形式のファイルリストが生成されます。
- ソースコードを確認した後、リストウィンドウを閉じて下さい。
標準で用意された 3665 のすべての近似式のソースコードを生成することができます。コードは、多項式や有理式でも簡潔で、倍精度(15桁)を使用しています。近似式に誤差の関数が含まれている場合は、それもコード化してくれます。
26. スプレッドシートへのエクスポート
 MS Excel export コマンドには、保存内容(3種類)、xls ファイル形式(3種類)、近似式、生成データのオプション設定があります。
MS Excel export コマンドには、保存内容(3種類)、xls ファイル形式(3種類)、近似式、生成データのオプション設定があります。
Save Lotus-123 コマンド(WK1 形式)は、Excel のフル出力形式とほぼ同じですが、2種類のグラフオプションがあります。
- Excel、Lotus、Quattro Pro のユーザーであれば、Review Curve-Fit ウィンドウの File メニューにある Save Lotus 123 または Save Excel コマンドを選択し、OK ボタンをクリックして、デフォルト設定でファイルを保存することができます。
ワークシートには、Lotus または Excel 形式で近似式のテキストデータを保存することができます。近似式を使用する場合は、その前に付いているヘッダー情報を削除し、ワークシートセルにコピー&ペーストします。X データは、その前の列に入力します。Excel v5 以上では、ワークシートのモジュールとして Visual Basic コードを埋め込むことができます。この機能を使用すると、Excel の組み込み関数と同様に近似関数を使用することができます。
スプレッドシートに生成されたデータは、すべてアクセスすることができます。Excel からデータをエクスポートする場合は、ワークシートの XY データ列、信頼区間、予測区間を選択して下さい。
27. SigmaPlot Output
- SigmaPlot のユーザーの場合は、Review Curve-Fit ウィンドウの File|Save SigmaPlot メニューコマンドまたは
 ボタンをクリックし、OK ボタンを押して下さい。SigmaPlot Format セクションでエクスポートする内容を選択します。
ボタンをクリックし、OK ボタンを押して下さい。SigmaPlot Format セクションでエクスポートする内容を選択します。
このオプションを使用すると、出版品質のグラフを含んだ SigmaPlot のワークシートを生成できます。ワークシートには、データの範囲やサイズを指定することができます。ほとんどの近似式は、[.XFM] の拡張子の付いた SigmaPlot XFM Transform ファイルとして保存することができます。
28. TableCurve 2D の終了
- Review Curve-Fit ウィンドウの OK ボタン
 をクリックすると、フィッティングモデルを終了します。
をクリックすると、フィッティングモデルを終了します。
- TableCurve 2D を終了する場合は、メインウィンドウの File|Exit メニューコマンドまたは閉じるボタンをクリックして下さい。