|
| サイトマップ | |
||
|
| サイトマップ | |
||
| SYSTAT 13 テクニカルサポート | SYSTAT 製品ページ |
データ・スクリーニングの初期の段階で、群分け変数 (Grouping variables) の件数を集計したり、数値変数の各種統計量をまとめておくと便利です。
使用するサンプルデータについてはこちらをご覧ください。
「Analyze (解析)」メニューの「One-Way Frequency Tables (1元表)」プロシージャには豊富な表示オプションが用意されており、出力するレポートを自由にカスタマイズすることができます。「Frequency distribution (度数分布)」オプションを使用すれば、群分け変数の各カテゴリの出現回数 (度数)や、標本全体に対する各度数の割合(相対度数)を示すことができます。度数と相対度数は、累積的に表示させることも可能です。ここで使用する標本データには、どのような食品 (FOOD$) が含まれ、それらのメーカー別 (BRAND$) 、ダイエット タイプ別 (DIET$: yes/no) の件数はどれだけあるでしょうか。
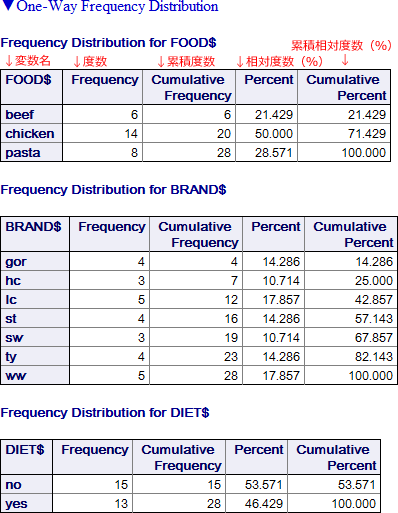
FOOD$(出力の左上に変数名が表示されています)に関するデータから、この標本の全 28 製品のうち 14 製品(Percent 列の 50.000% ) が chicken で、21.429% が beef、そして 28.571% が pasta であることがわかります。
BRAND$ 当たりの製品数はいずれも 3 ~ 5 の範囲内です (二つ目のテーブル)。
通常の食品 (DIET$ が no) は 15 種類で、ダイエット食品 (DIET$ が yes) は 13 種類あります。
Analyze (解析) メニューの Two-Way Tables (2元表) にある「List layout (リスト配置)」オプションは、2つの要因 (変数) をクロス分類して得られる結果をまとめるのに便利です。ここでは DIET$ と BRAND$ の組み合わせについて調べてみることにしましょう。
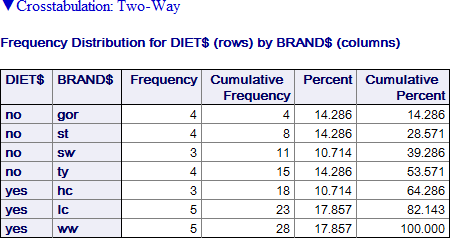
DIET$ には 2 つ (no/yes)、BRAND$ には 7つのカテゴリがあるので、その組み合わせは全部で 14 通りになるはずですが、ここではそのうち 7 通りが示されます。ダイエット食品 (yes) と通常の食品 (no) では、ブランド (BRAND$) に違いがあることがわかります。
2つの要因 (DIET$ と FOOD$) の度数を 2 元表として表示したいと思います。「List layout」オプションの選択を解除し、DIET$ と FOOD$ の関係を見てみましょう。
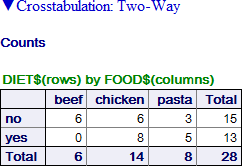
DIET$ が yes の群では beef 製品が 0 であることがわかります。