20.4 ウィルコクソンの符号付き順位検定
符号付き順位検定 (Signed Rank Test) は、正規性や等分散性の前提条件を必要としないノンパラメトリックな検定手法です。符号付き順位検定を使うのは:
- 同一個体に対する単一処理の効果が有意であるか否かを調べたいとき。
- 処理効果が分散の等しい正規分布に従っていないとき。
効果が正規分布に従っていることが分かっている場合は、対応のある t 検定を使います。詳しくは、対応のある t 検定をご覧ください。比較する処理が複数ある場合は、フリードマンの順位に基づく反復測定分散分析 (Friedman Repeated Measures ANOVA on Ranks) を実行します。詳しくは、フリードマンの順位に基づく反復測定分散分析をご覧ください。
| ※ Tip:正規母集団に対して符号付き順位検定を実行しようとした場合、Signed Rank Test オプションの設定によっては、よりパワフルな対応のある t 検定でそのデータを分析できることが SigmaPlot により提案されます。 |
- 符号付き順位検定について
- 符号付き順位検定を実行する
- 符号付き順位検定のデータを配置する
- 符号付き順位検定オプションを設定する
- Options for Signed Rank Test: Assumption Checking
- Options for Signed Rank Test: Results
- 符号付き順位検定を実行する
- 符号付き順位検定の結果を解釈する
- Normality Test
- Summary Tables
- W Statistic
- 符号付き順位検定のレポートグラフ
- 符号付き順位検定データのグラフを作成する方法
1. 符号付き順位検定について
符号付き順位検定では、測定した全ての処理の差を符号を無視して (それらの絶対値に基づいて) 小さい順に順位を付け、その順位に対してそれぞれの差の符号を割り当てます。この符号付き順位を、合計して比較します。このプロシージャでは、処理効果のサイズと符号を使用します。
もし、処理効果が無いとすれば、正の順位の合計と負の順位の合計は互いに似たものになるはずです。もし順位がどちらか一方の符号に偏る傾向があるとすれば、処理効果がある (例えば、処理の事前と事後に統計的有意差がある) と結論付けることができます。
ウィルコクソンの符号付き順位検定では、「処理は被験者に対して効果がない」という帰無仮説を検定します。
2. 符号付き順位検定を実行する
符号付き順位検定 (Signed Rank Test) を実行するには:
- ワークシートに適切なデータを入力または配置します。詳しくは、符号付き順位検定のデータを配置するをご覧ください。
- 必要があれば、Signed Rank Test オプションを設定します。
- Analysis タブの SigmaStat グループにある Tests ドロップダウンリストから以下を選択します:
Before and After → Signed Rank Test
- 検定を実行します。
- レポートグラフを作成します。詳しくは、符号付き順位検定のレポートグラフをご覧ください。
3. 符号付き順位検定のデータを配置する
検定するデータのフォーマットには、生データまたはインデックス付きデータのいずれかを使用することができます。いずれの場合も、データはワークシートの2列を占めます。
ウィルコクソンの符号付き順位検定の有効なデータフォーマット例。
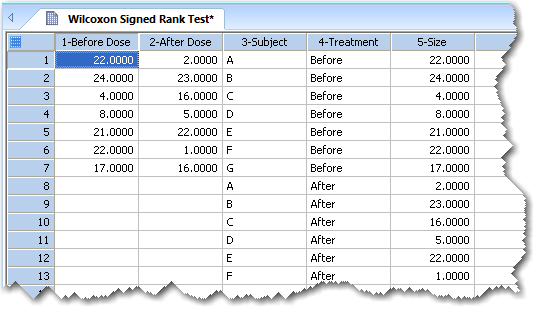 |
列1と列2には生データを配置しています。列3と列4には、インデックス付きデータを配置しており、そのうち列3が因子列となります。
4. 符号付き順位検定オプションを設定する
Signed Rank Test オプションを使用するのは:
- データの正規性検定の基準を緩和または厳格にする検定パラメータを調整するとき。
- サマリーテーブルを表示するとき。
- イェーツの修正因子を有効にするとき。
オプションの設定内容は、SigmaPlot を次回起動したときも保持されます。
Signed Rank Test オプションを変更するには:
- 検定オプションを変更したあと検定を実行するにあたり、検定の実行前にデータを選択しておきたい場合は、使用するデータをポインターでドラッグします。
- Analysis タブの SigmaStat グループにある Options を選択します。
Options for Signed Rank Test ダイアログボックスに次の2つのタブが表示されます:
- Assumption Checking:データの正規性の基準を緩和または厳格にするには、このパラメータを調整します。詳しくは、Options for Signed Rank Test: Assumption Checking をご覧ください。
- Results:レポートにデータの統計サマリーを表示したり、ワークシート列に残差を保存するかを指定します。詳しくは、Options for Signed Rank Test: Results をご覧ください。
- 検定を継続するには、Run Test をクリックします。検定ウィザードの Select Data パネルが表示されます。
- 現在の設定内容を適用して、オプションダイアログを閉じるには、OK をクリックします。
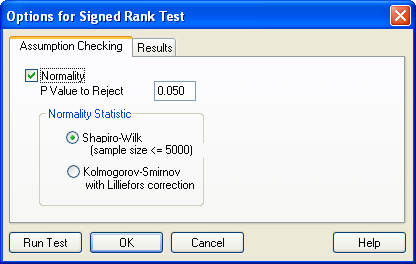
4.1 Options for Signed Rank Test: Assumption Checking
正規性の検定 (Normality) を設定するには Options for Signed Rank Test ダイアログボックスにある Assumption Checking タブをクリックします。正規性 (Normality) の前提条件の検定では、母集団が正規分布に従っているかをチェックします。
| ※ Note:符号付き順位検定には、Equal Variance の選択肢はありません。対応のある t 検定は、選択した母集団の個体それぞれに対してではなく各個体の変化に基づいて検定を行うからです。従って、等分散性を検定する必要はありません。 |
- Normality の検定:SigmaPlot では、母集団の分布の正規性検定に Shapiro-Wilk または Kolmogorov-Smirnov のいずれかを使用します。
- P Value to Reject:P Value to Reject ボックスに該当する P 値を入力します。P 値により、データが正規分布していないと誤って結論付ける確率が決定されます (P 値は、データが正規分布しているという帰無仮説を誤って棄却してしまうリスクです)。検定によって求められた P 値が、ここで設定した P 値よりも大きければ、帰無仮説が採択 (Pass) されます。
正規性の要件をより厳密なものにするには、この P 値を大きくします。パラメトリックな統計手法では、仮説の棄却が比較的ロバスト (頑健) に検出されることから、SigmaPlot ではこの値を 0.050 としています。P 値をこれよりも大きくすると (例えば、0.100)、そのデータに正規性がないとの判定が出やすくなります。
正規性の要件を緩和するには、P 値を小さくします。正規性があるという仮説を棄却するための P 値に小さい値しか要求しないということは、前提とする正規分布からデータが外れていても、それが非正規であると判定される前に、それだけ広く受け入れたいとする意思があることを意味します。例えば、P 値を 0.050 とした場合、あるデータを非正規であると判定するには、0.100 の場合と比べてそれだけ大きく正規性を逸脱していなければなりません。
| ※ 制限事項:この正規性の検定は、ロバスト (頑健) に母集団のデータを非正規であると検出しますが、データの分布が極端な状態にあると検定できない場合があります。このような条件の場合は、前提条件の自動検定に頼らずにデータを視覚的に調べることで容易に見分けることができます。 |
4.2 Options for Signed Rank Test: Results
- Summary Table:Rank Sum test レポートの符号付き順位検定のサマリーテーブルには、中央値 (Median)、パーセンタイル、および、サンプルサイズ N が一覧で表示されます。必要があれば、ボックスの内容を編集してパーセンタイルの値を変更することができます。推奨されるパーセンタイルは、25% と 75% です。
- Yates Correction Factor (イェーツの修正因子) :統計的検定で、例えば、2 x 2 分割表やマクニマー (McNemar) の検定のような、自由度1の χ2 分布を使用する場合、算出される χ2 統計量は、実際の χ2 検定統計量の分布と比べて生成される P 値が非常に小さくなる傾向があります。理論上 χ2 分布は連続型ですが、この検定の χ2 分布は離散型です。
イェーツの修正因子 (Yates Correction Factor) を使えば、算出される χ2 値を調整して、このずれを補うことができます。イェーツの修正因子を使うことで検定の取扱いが慎重 (conservative) になります:例えば、P 値が増加するので偽陽性を結論付ける可能性が少なくなります。
イェーツの修正は、2 x 2 分割表や、自由度1の χ2 分布から P 値を算出するその他の統計に適用します。イェーツの修正の導出に関する詳しい説明については、統計学の参考書をご覧ください。
5. 符号付き順位検定を実行する
検定を実行するには、使用するデータをマウスポインタでドラッグして検定するデータを選択状態にしておく必要があります。その後、検定ウィザードの Select Data パネルを使用して検定したいデータを含むワークシートの列を選択し、そのデータがワークシート上でどのように配置されているかを指定します。
Signed Rank 検定を実行するには:
- Analysis タブの SigmaStat グループにある Tests ドロップダウンリストから次を選択します:
Before and After → Signed Rank Test
検定ウィザードの Signed Rank Test — Data Format パネルが表示され、データフォーマットを指定するよう指示されます。
検定ウィザードの Signed Rank Test — Data Format
パネルでデータフォーマットを指定。
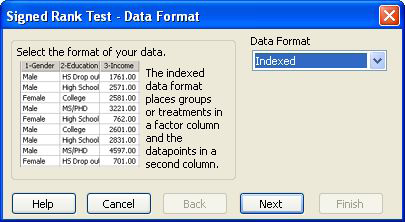 |
- Data Format ドロップダウンリストから該当するデータフォーマットを選択します。
データが各列に群分けされている場合は、Raw を選択します。データが群のインデックス列とデータ列の対になっている場合は、Indexed を選択します。
- Next をクリックして、検定するデータ列を選択します。この検定を選択する前に列を選択していれば、Selected Columns リストに選択した列が表示されます。
- Selected Columns リストに別のワークシート列を割り当てたい場合には、ワークシートで直接その列を選択するか、Data for Data ドロップダウンリストからその列を選択します。
Selected Columns リストの一行目に割り当てられるのは最初に選択した列で、以後同様に列を選択するごとにリストの2行目以降に割り当てられてゆきます。
各行には、選択した列のタイトルが表示されます。生データ (Raw) の場合は、ワークシートの2列を、インデックス付きデータ (Indexed) の場合は、ワークシートの3列を選択するよう指示されます。
- 選択した内容を変更するには、リストの割り当てを選択したあと、ワークシートから列を選択しなおします。Selected Columns リストの内容をダブルクリックすることによって、列の割り当てを消去することもできます。
- Finish をクリックすると、検定が実行されます。正規性を検定するよう選択している場合、SigmaPlot により正規性の検定 (Shapiro-Wilk または Kolmogorov-Smirnov) が実行されます。お持ちのデータが検定に合格した場合、SigmaPlot により、その結果が報告され、対応のある t 検定 (Paired t-test) を用いて分析を続行するよう提案されます。
計算が完了すると、符号付き順位検定の結果を内容とするレポートが表示されます。
6. 符号付き順位検定の結果を解釈する
Signed Rank Test では、ウィルコクソンの W 統計量とその P 値が計算されます。レポートに表示されるその他の結果は、Options for Signed Rank Test ダイアログボックスで有効または無効にすることができます。
結果の説明
数値による結果に加えて、拡張された結果の説明が表示されることがあります。この説明テキストは、Options ダイアログボックスで有効または無効にすることができます。また、表示する小数点以下の桁数についても Options ダイアログボックスで設定できます。
Wilcoxon Signed Rank Test の結果のレポート例
 |
6.1 Normality Test
Normality Test の結果には、処理の差が正規母集団から抽出されたものであるという前提条件の検定に合格したか否か (Passed または Failed)、および、この検定で計算された P 値が表示されます。ノンパラメトリックの検定法では、母集団の正規分布を前提条件としないのでこの検定には合格しません (Failed になります)。この結果は、Options for Signed Rank Test ダイアログボックスで無効にしない限り表示されます。
6.2 Summary Tables
SigmaPlot では、サンプルサイズ N、欠損値の数 (Missing)、中央値 (Median)、および、2つのパーセンタイルを一覧にしたサマリーテーブルが作成されます。この結果は、Signed Rank Test Options ダイアログボックスでこれらを無効にしない限り表示されます。
- N (Size):該当する列または群の観測値の数です。
- Missing:該当する列または群の欠損値の数です。
- Medians:全ての観測値を小さい順に並べて、観測値の小さい方の半数の中からの最大値を選択することで算出する観測値の「中央」です。観測した中央値では、その観測値よりも大きい観測数と小さい観測数が同じになります。
- パーセンタイル:観測値の上側と下側の両端を定義した2つのパーセンタイル点です。
6.3 W Statistic
ウィルコクソンの検定統計量 W は、全ての処理の事前と事後の差をそれらの絶対値に基づいて順位を付け、その順位に対してそれぞれの差の符号を割り当てます。この符号付き順位を、合計して比較します。
W の絶対値が「大きい」場合、処理効果ありと結論付けることができます (例えば、もし順位がどちらか一方の符号に偏る傾向があるとすれば、処理の事前と事後の間に統計的に有意な差があることになります)。
W が小さい場合、正の順位と負の順位は互いに似たものになるので、処理効果なしと結論付けることができます。
- P 値:P 値は、真の差があると誤って結論付けてしまう確率です (例えば、W に基づいて帰無仮説を誤って棄却する確率、すなわち、第一種の誤り (Type I error) です)。P 値が小さいほど、処理効果がある確率が高くなります。
伝統的には、P < 0.05 であれば、有意差があると結論付けることができます。
7. 符号付き順位検定のレポートグラフ
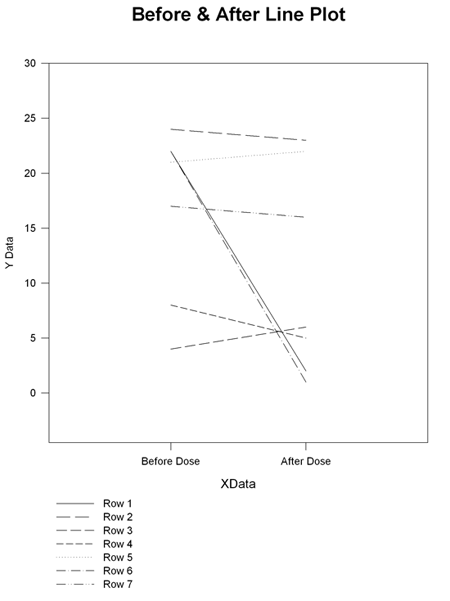
符号付き順位検定レポートでは、処理後の変化をあらわす折れ線散布グラフを作成することができます。
7.1 符号付き順位検定データのグラフを作成する方法
- Signed Rank Test レポートを選択します。
- Report タブの Result Graphs にある Create Result Graph をクリックします。
Create Result Graph ダイアログボックスが表示され、その中に Signed Rank Test の結果で利用できるグラフのタイプが表示されます。
Signed Rank Test Report の Create Result Graph ダイアログボックス
 |
- Graph Type リストの中から作成したいグラフタイプを選択します。
- OK をクリックするか、リスト内のグラフをダブルクリックします。詳しくは、レポートグラフをご覧ください。選択したグラフがグラフウィンドウに表示されます。
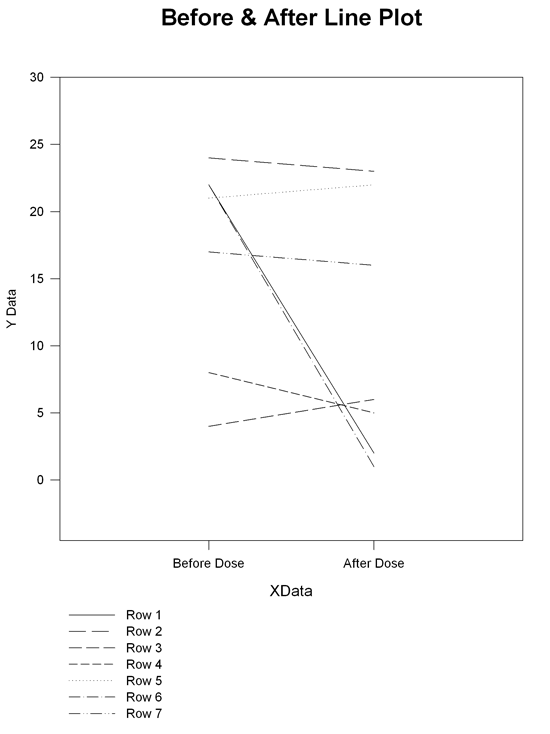
事前と事後の散布グラフの例
 |