|
| サイトマップ | |
||
|
| サイトマップ | |
||
受信者動作特性 (ROC) 曲線は、医療分野の臨床実験におけるカットオフ値 (判別点) を決定するのに利用します (この分析と名称はレーダー信号の検出に由来します)。例えば、前立腺がんの前立腺特異抗原検査 (PSA) では、カットオフ値が 4.0 ng/ml に定義されています。これを元に、検査値が 4.0 以下であれば正常、4.0 以上であれば異常であると判断します。しかし、PSA の値が 4.0 以下でも異常 (偽陰性) であったり、4.0 以上でも正常 (偽陽性) な患者は必ず存在します。受信者動作特性 (ROC) 曲線分析の目的は、このカットオフ値を決定することです。
男性のグループが 2つあるとします。"至適基準 (gold standard)" の手法を使用して、一方のグループは正常 (陰性) で前立腺がんではなく、もう一方のグループは異常あり (陽性) で前立腺がんであることが分かっているとします。すべての男性に対して前立腺特異抗原検査 (PSA) の血液検査を行い、この疾患の検査に使用します。この検査で、異常とされる人は何人かいるでしょうが、その全員が疾病を持つとは限りません。確実に疾病がある人が、この検査で異常とされる数と、疾病者の総数の割合が真陽性率 (感度 sensitivity) です。また、この検査で正常とされる人は何人かいるでしょうが、その全員がこの疾病にかかっていないとはいえません。疾病があってもこの検査で正常とされる人の数と、本当に疾病がない人の総数の割合 (「至適基準 (gold standard)」の手法として知られています) が真陰性率 (特異度 specificity) です。最終的な目標は、前立腺特異抗原検査 (PSA) の受信者動作特性 (ROC) 曲線を解析して適切なカットオフ値を発見し、偽陽性と偽陰性を最小限に抑えることです。偽陽性と偽陰性を最小限に抑えることは、感度 (Sensitivity) と特異度 (Specificity) を最小限に抑えることと同じです。
前立腺特異抗原検査 (PSA) では、4 より大きい値 (> 4) は異常で、4 より小さい値 (<4) は正常となります。しかし、この値は必ずしも適切とは限りませんので、このマクロではこれより大きい値を異常としたり、これより小さい値を異常としたときの条件を考慮することができます。
受信者動作特性曲線 (ROC 曲線) では、y 軸に感度 (sensitivity)、x 軸に特異度 (1-specificity) を使用してグラフを作図します。以下に例を示します。感度 (sensitivity) を最大にすると、ROC 曲線の y 値が最大化します。特異度 (specificity) を最大にすると、ROC 曲線の x 値が最小化します。そのため、ROC グラフの左上隅に最も近い ROC 曲線上のポイントの値が、カットオフ値の第一候補として適したものであることになります。ただし、この値が常に正しいとは限りません。例えば、異常の検出を逃さないことに重きをおくことから、感度の最大化 (偽陰性を最小にする) を特異度よりも重要視するスクリーニングアプリケーションもあります。この場合、ROC 曲線上で適切なカットオフポイントは左上隅付近から右上隅の方に移ります。しかし、前立腺がんのスクリーニングでは良性前立腺肥大で PSA が異常値 (高い値) になることから 、偽陽性が普通になり望ましくありません (費用のかかる生体検査、心理的影響の生起)。このような場合は、特異度 (specificity) を最大化するのが重要です (ROC 曲線の左下隅側への移動) 。
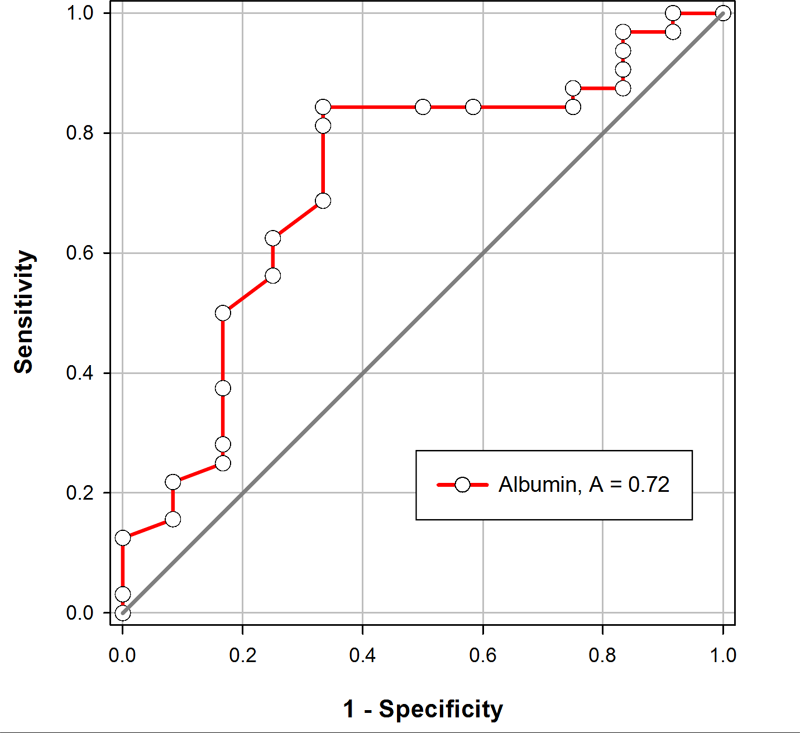 |
臨床検査の精度で重要な指標は ROC 曲線の下の面積です。この面積が 1.0 である場合、ROC 曲線は、縦方向 (0,0 から 0,1) と 横方向 (0,1 から 1, 1) の 2つの直線で構成されます。感度と特異度が両方とも 1.0 であるため、この検査の精度は 100% で、偽陽性と偽陰性は存在しません。これに対して、正常か異常かを区別できない検査では、ROC 曲線は 0,0 から 1,1 までの対角線に相当します。この線の ROC 面積は 0.5 です。ROC 曲線の面積は、上述の 0.5 と 1.0 の間になるのが一般的です。
各検査の ROC 面積を統計的に比較して 2つ以上の検査を比較することができます。同一個体に対して行った複数の測定結果であれば、検査間に相関があるかも知れません。異なる個体の測定から得られた結果であれば、相関性はないかもしれません。ROC Curves Analysis Module は、それぞれ "Paired"「対あり」、"Unpaired"「対なし」として参照し、どちらの場合でも分析することができます。
検査測定には欠損値が含まれることもありますので、ROC 面積を比較する際に欠損値を処理する 2つの方法 (ペアワイズ除去およびケースワイズ除去) が用意されています。これに関しては後で詳しく説明します。
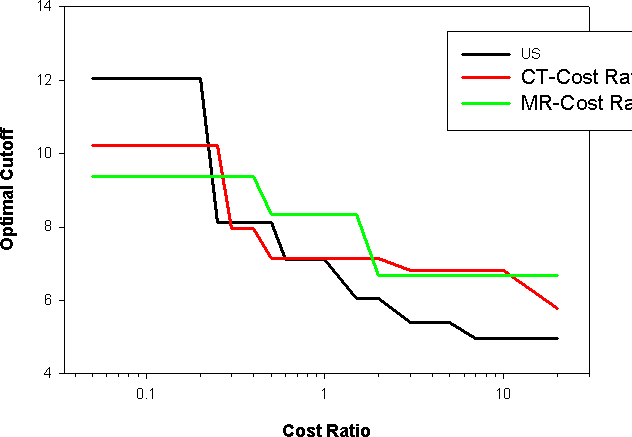
患者が疾病である確率値 (検査前確率, Pre-test probability) がわかっていれば、検査の測定値からその患者が疾病である確率を計算することができます。また、偽陽性/偽陰性のコスト比 (Cost Ratio) がわかっていれば検査値の最適なカットオフ値を計算することができます (上記の検査例では、偽陰性のコストが偽陽性のコストよりも大きくなります)。現在のマクロでは、検査前確率 (Pre-test probability) および、偽陽性/偽陰性のコスト比 (Cost Ratio) を入力することが可能です。
データは次の2つの形式で入力することができます:
Indexed data は、Systat や SigmaStat (SigmaPlot の統計機能) 等の統計プログラムで使用されるデータ形式です。"Indexed" とは、SigmaStat で使用されている用語です。他の列 (単一または複数の列) のデータにインデックスを付けるための列が1つ設けられています。 ROC 曲線を使用して異なる複数のロジスティックモデルの性能を判断する際、検査結果の陽性と陰性 (異常と正常) を区別するロジスティック回帰の出力結果もこの形式です。いずれのデータセットも、分類変数 (classification variable) と検査変数 (test variable) という対になる複数の列で構成されます。分類変数には、陰性 (正常) または陽性 (異常) の二つの状態が存在します。多くのプログラムでは、陽性 (positive) を 1 に、陰性 (negative) を 0 したものが使用されます。分類変数は、Worksheet の 1列目に配置する必要があります。検査変数は連続的な数値変数からなるもので、ここに検査の結果を入力します。検査変数が1つの場合は、列2に配置することになります。検査変数が複数ある場合は、列2以降の列に複数配置します。検査変数の数に制限はありません。検査変数が複数あっても分類変数は1つしか無く、列1に配置します。検査変数の列は、左揃えで連続して配置する必要があります。従って、使用するデータの左側やデータ間に空白の列があってはなりません。
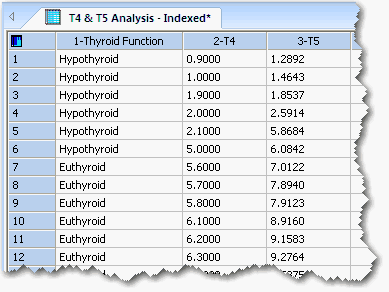
以下の例は、2つのデータセットを数行のデータで示したものです。列1は、分類 (classification) 変数です。列タイトルが "Thyroid Function" (甲状腺機能) となっていますが、これは、分類変数の名称です。この中には、"Hypothyroid" (甲状腺機能低下) と "Euthyroid" (甲状腺機能正常) という2つの分類状態も記入されています。Hypothyroid と Euthyroid が、それぞれ、異常 (abnormal) と 正常 (normal) の分類状態に対応します。T4 と T5 は、この ROC 解析で正常と異常を見分けるのに使用するそれぞれ異なる血液検査の名称です。これらを比較して、どちらが適切な検査であるかを判断します。なお、分類変数は必ず列1に配置し、また、2つの検査の変数は互いに隣り合うように2列に配置する必要があります。
列1に列タイトルがあれば、その内容が分類変数の名称として取得されることになります。検査変数の各列にタイトルがあれば、それぞれの内容が各検査変数の名称として取得されることになります。分類状態 (classification state) の名称は、列1のセルに入力された内容から取得されます。検査変数の列タイトルに何も入力していなければ、各検査のデフォルトの名称、すなわち、"Test 1", "Test 2" 等がグラフやレポートの名称として使用されることになります。各検査変数の名称はそれぞれ異なるものにすべきですが、同じ名称であってもプログラムによって添え字がつけられ区別されます。
 |
いずれの検査の分類状態にも、欠損値でないデータポイントが2つ以上あるはずです。欠損値があれば、この分析で自動的に処理されます。データ列では、数値以外の全てのデータ (空白のセル、SigmaPlot の二重ダッシュによる欠損値シンボル、"+inf", "-inf", "NaN" など) が欠損値になります。欠損値の処理に選択可能な2種類のアルゴリズムを使用する Paired 型の面積比較 (詳細については「欠損値メソッド」のセクションを参照) を除いて、欠損値は全ての計算で無視されます。
Grouped (グループ化) データ形式は、データ列のペア (各検査のための1つのペア) で構成されます。ペアデータは、1つの列は陰性 (正常) の値、もう一方の列は陽性 (異常) の値で構成します。そのため、2つの検査を比較する場合、最初の 2列は最初の検査、3列と 4列目は 2番目の検査というように、Worksheet には 4つのデータ列が必要です。
特定の列タイトル形式は、各ペア内のデータ列のペアと分類状態に関連付けられている検査を識別するために使用されます。Worksheet 内のデータが明確に識別され、生成されるすべてのグラフとレポートに注釈が付けられるため、この形式を使用することをお勧めします。生成された検査名「Test 1」、「Test 2」などからなる 1列目から開始する列のペアをプログラムが識別するために列のタイトルを使用する必要はありません。「1」 および 「0」 の分類を最初と 2番目の列にそれぞれ割り当てられますが、これはデータの整理に最適な方法ではありません。検査名と分類状態は数値のため、結果を解釈するのもさらに難しくなってしまいます。
グループ化されたデータの列タイトル規則
この列タイトルの規則はグループ化されたデータ形式のデータを識別する簡単な方法です。次の例では 2つのデータセット用のデータ列がいくつか示されています。最初の 2列には T4 検査のデータが格納されています。最初の列 「T4 – Euthyroid」 は、T4 検査で正常とされるデータの列です。マイナス記号の後ろに状態分類を続けた検査名が列タイトルとなっています。マイナス記号の両側にあるスペースは無視されます。2番目の列「T4 – Hypothyroid」は、T4 検査で異常とされるデータの列です。3列目と 4列目の列タイトルは 2回目の検査名である T5 を使用している以外は、最初の 2つと同じです。
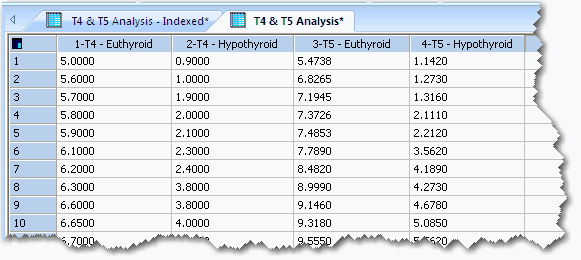 |
ペアの列の検査名は共に同じでなければなりません。また列タイトルは、はっきりと 2つの分類状態を示すものでなければなりません。
インデックス付けされた形式と同様に、Worksheet のセルにある欠損値は無視されます (ROC 面積を比較するときの特別な処理をする場合を除く。詳細については「欠損値メソッド」のセクションを参照)。
ROC 曲線解析 (ROC Curve Analysis) を実行するには:
Data Format: ほとんどの場合、プログラムは Worksheet のデータ情報からデータ形式を識別します。上のダイアログでは、Indexed (インデックス付き) の形式として認識されました。ユーザーは Indexed (インデックス付き) および Grouped (グループ化) の 2つの形式から選択することができます。
Data Type:2つ以上のデータセットを選択すると、Data Type オプションが有効になり、相関検査が可能になります。
相関検査には Paired (ペアである) または、Unpaired (ペアでない) のどちらも選択することができます。Paired を選択した場合、DeLong, Delong および Clarke-Pearson method(2) を使用して ROC 面積比較が実行されます。Unpaired を選択した場合、Hanley および McNeil method(3) を使用して領域が計算され、Z 検定を使用して面積が比較されます。
Missing Value Method:欠損値が存在する場合、ROC 領域のペアワイズ比較のための 2つのオプション - Pairwise Deletion (ペアワイズ除去) および Casewise Deletion (ケースワイズ除去) を使用できます。欠損値が存在しない場合、このオプションは使用できません。
ペアワイズ除去では、解析された特定のペアに欠損値が含まれている行のみが削除され、データの行全体は削除されません。この方法で削除されるデータの値はわずかです。ペアワイズ除去がうまくいかないこともあり得ます。ケースワイズ除去の場合は、欠損値を含むすべての行のセルがすべて削除されます。このオプションの使用で、さらに多くのデータが削除されることがあります。この違いをさらによく理解するために簡単な例として、同じ長さの 2つのデータ列で、一方には欠損値がなく、もう一方には欠損値が存在する場合を考えてみてください。ROC 曲線が比較されているとき、一定の計算が - 1列目とそれ自身、1列目と 2列目、2列目とそれ自身 - といったペアワイズで実行されます。欠損値のない列がその列自身と比較されると、ペアワイズ除去による行の削除は実行されません。しかし、ケースワイズ除去の場合は欠損値を含む行が両方のデータセットから削除されます。そのため、ケースワイズ除去の場合、その列自身に欠損値が存在しない列の計算では、1行 (他のデータセット内にある欠損値に対応する行) が削除されます。ペアワイズ除去が有効かどうかはモジュールによって決定され、有効でない場合はユーザーにその情報が提供されます。
Positive State Options - Classification State and Direction:「Negative」 (normal) または「Positive」 (abnormal) として、2つの分類が示されます。ユーザーは ROC 解析ソフトウェアに、どちらの State (状態) が「Positive (陽性)」であるかを指定する必要があります。また Positive State の検査測定値が「High」で、Negative State より高いか、または「Low」で Negative State よりも低いかどうかも指定する必要があります。
PSA (前立腺特異抗原) 検査では 4 ng/ml より低い値が正常とされ、これよりも高い値は異常とされます。そのため、2つの分類状態の名前が「positive」 および 「negative」 の場合、正常な状態は 「positive」 で、Positive Direction が 「High」 です。この場合、ラジオボタンは 「positive」 と 「High」の並びを選択します。
一方、甲状腺機能低下に対する T4 (サイロキシン) 検査については、T4 値は正常な状態よりも異常な状態で低くなっています。この場合、異常の Positive State は「Hypothyroid」 で Positive Direction は「Low」です。そのため、ラジオボタンは「Hypothyroid」 と 「Low」 の並びを選択します。
適切でないオプションを選択した場合、どうなるでしょうか? 感度 (特異度) は positive (negative) 状態という観点から定義されます。そのため positive state が正しく選択されないと、感度と特異度が間違って (取り違えられて) 定義され、ROC 曲線の X と Y 軸が切り替わります。そこには 0.5 未満の領域が存在します。モジュールによりこれが検索され、オプションが提供されます。
データに何か問題があることもあります。その場合、分析を中断して問題を修正することが可能です。ほとんどの場合、適切でない Positive State か Direction を選択したことが原因です。ユーザーは選択を変更して再試行することができます。複数の検査において、まれに 0.5 以上の領域が存在する検査がいくつか存在したり、0.5 以下の領域が多少存在したりすることがあります。その場合は、この警告を無視して分析を続けることができます。
Available Data Sets - Selected Data Sets:Available Data Sets ウィンドウ内で使用可能なデータセットを 1つ以上クリックして選択したら、Add ボタンをクリックしてください。必要に応じて、Selected Data Sets ウィンドウ内の検査名を選択し、Remove をクリックすると、選択を解除して元に戻すことができます。
Confidence Intervals:Sensitivity (感度) と Specificity (特異度) 、および面積比較レポートの両方の解析のために Confidence intervals (信頼区間) が計算されます。90, 95 および 99% の信頼区間を作成することができます。
Create Sensitivity and Specificity Report:(ソートされた) データセット内の各検査データ値の間でカットオフ値が作成されます。データポイントが多く、かつ検査がいくつかある場合、多数のカットオフ値が存在することになり、Sensitivity & Specificity Report (感度と特異度のレポート) が非常に長くなることがあります。このオプションをオフにすると、この下のダイアログにあるすべてのレポートオプションは必要なくなり無効になります。
Fractions/Percents:感度、特異度および確率は、小数点またはパーセントで表示することができます。Percents (パーセント) を選択する場合は、Pre-test probability (検査前確率) もパーセントで入力されている必要があります。
Create Post-Test Results:このオプションをオンにすると pre-test probability (検査前確率) を入力できるようになります。偽陽性/偽陰性のコスト比 (cost ratio) を入力することもできます。Pre-test probability (検査前確率) を入力すると陽性的中率 (PV + = 陽性の検査結果で疾患のある確率) および、陰性的中率 (PV - = 陰性の検査結果で疾患がない確率) の両方の検査後確率が各カットオフ値のために作成されます。Cost ratio (コスト比) オプションを選択すると適切なカットオフ値が計算されます。これらすべての結果が各検査の Sensitivity & Specificity Report (感度と特異度のレポート) に表示されます。
ROC Graph Options:ダイアログのすべてのグラフオプションが ROC グラフに適用されます。グラフには、斜線やグリッドラインを追加したり、各カットオフポイントに sensitivity (感度) と specificity (特異度) のシンボルを追加したりすることができます。また、ROC 曲線のラインを実線から別のラインに変更することも可能です。
標準的な ROC 解析の結果は Notebook Manager で以下のように表示されます:
 |
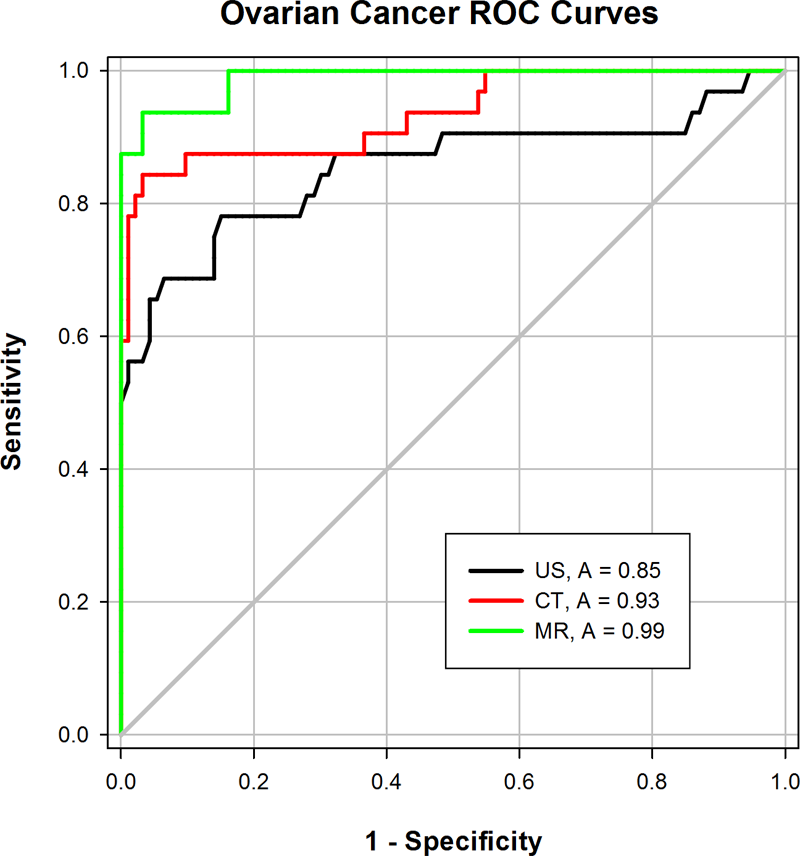
3つのデータセットのための ROC 曲線グラフを以下に示します。これらのグラフは、Graph Data と名付けられた Worksheet 内の数値結果から生成されたものです。グラフタイトルは生データを含むセクション名から取得されます。凡例には検査名と各カーブに対する ROC 面積が示されています。このグラフには対角線 (Show diagonal line) とグリッド (Show grid lines) オプションが選択されています。
 |
このグラフは目的に合わせていくらでも編集することが可能です。
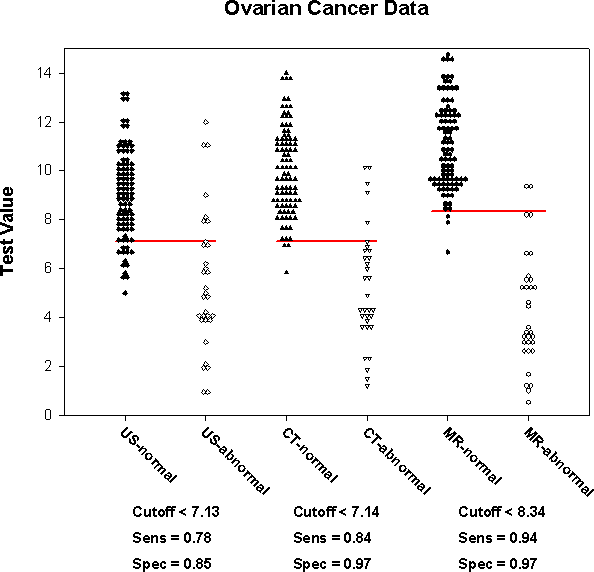
ROC 曲線に関連付けられたデータのドットヒストグラムです。
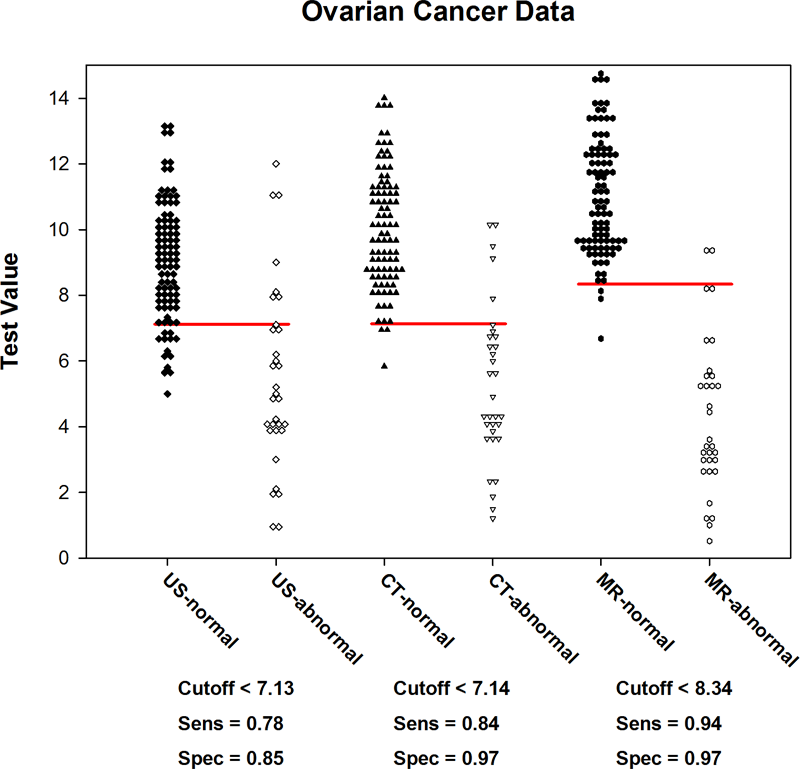 |
グラフタイトルは生データを含むセクション名から取得されます。x 軸の目盛りラベルは検査名と分類状態名から取得されます。横に適用するには長すぎる場合、目盛りのラベルは回転します。シンボルは横に隣接させたり、縦にネストさせたりして配置することができます。
検査前確率 (Pre-test probability) と偽陽性/偽陰性のコスト比 (cost ratio) を入力すると、各検査に対して適切なカットオフ値が計算され、各検査の 2つのドットヒストグラムを横断する横線として表示されます。 x 軸の下に表で示されるのはカットオフパラメーターの最適な数値です。
Sensitivity and Specificity Report (感度と特異度のレポート) にはすべての検査結果が表示されます (前のレポートの下に追加の検査レポートが表示されます)。各検査の結果は 3つのパートに分割することができます:
検査前確率 (Pre-test probability) とコスト比 (Use Cost Ratio) の両方の値を入力すると、最も適したカットオフ値が計算されます。ROC 曲線 m に対する接線の傾斜が、入力する2つの値で定義されます (P = pre-test probability (検査前確率))。
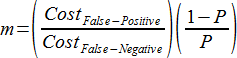 |
(1) |
カットオフの最適値は、感度(sensitivity) と特異度 (specificity) に傾き m を使用して、関数 (1) を最大化するカットオフを求めることによって算出します。
| (2) |
この計算結果の Sensitivity & Specificity Report (感度と特異度のレポート) は、以下のように表示されます。
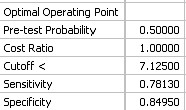 |
このデータセットの場合、検査前確率 (Pre-test probability) を 0.5 、コスト比 (Cost Ratio) を 1.0 としたとき、最適なカットオフ値 (Cutoff <) は 7.125 となります。
感度、特異度および、それらの信頼区間が、レポートの第2部にカットオフ値の関数としてリスト表示されます。これらの結果の一部を以下の表で示します。これらの結果は Fractions/Percents オプションを使用して、小数またはパーセントであらわすことができます。
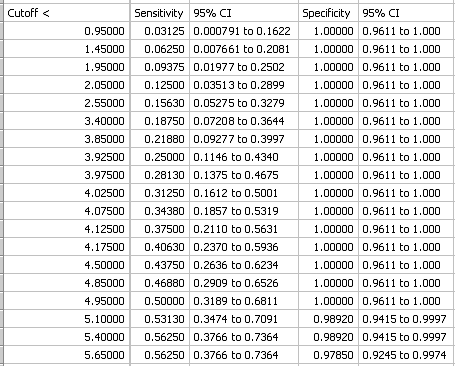 |
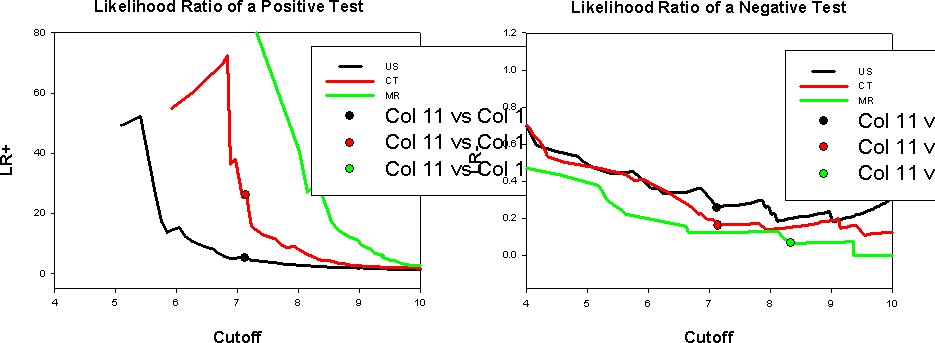
このレポートの第3部には尤度比 (likelihood ratio) と検査後確率 (post-test probabilities) が含まれています。
陽性 (positive) と陰性 (negative) の尤度比はそれぞれ次式で定義されます。
| (3) | |
| (4) |
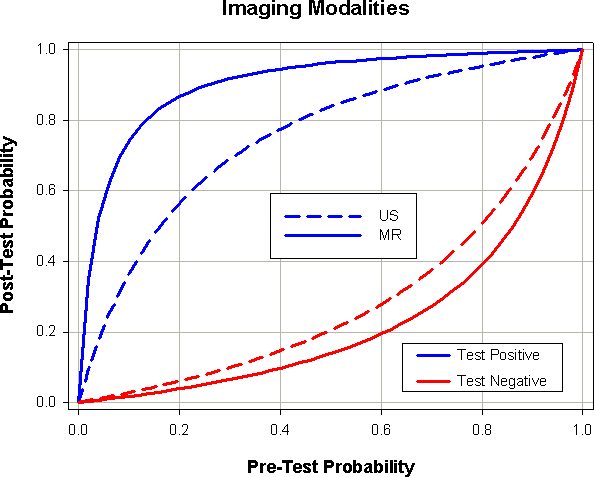
検査後確率 (post-test probabilities) は、陽性テスト (PV+) で与えられる疾患ありの確率と陰性テスト (PV-) で与えられる疾患なしの確率です。これらは、pre-test probability が入力されたときに計算されます。P = pre-test probability を使えば、これらの確率に使用する式は次式になります:
| (5) | |
| (6) |
尤度と検査後確率の結果レポートの一部を以下に示します。
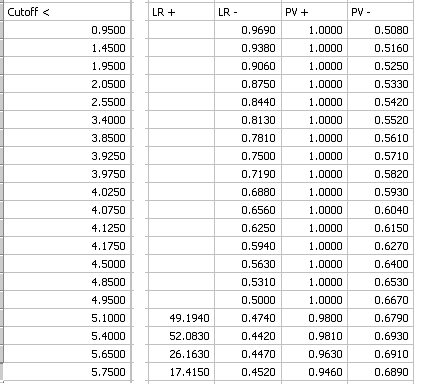 |
Positive likelihood ratio (陽性尤度比 LR +) が定義されないカットオフ値がありますが、これは、 Specificity (特異度) =1 であるためです。
ROC 面積のレポートは次の 2部で構成されます:
レポートの例を以下に示します。
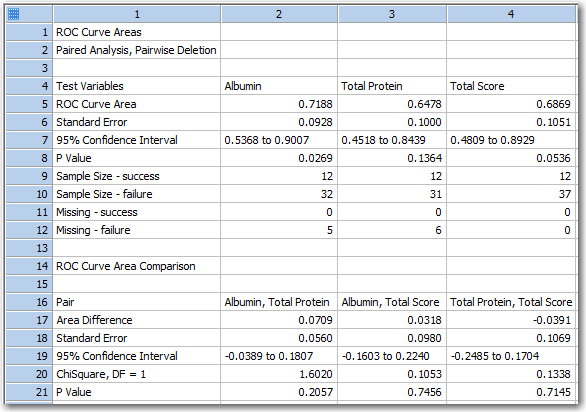 |
この事例には、関連する3つの検査があります。2行目には、ペア分析 (Paired Analysis) が実行されたこと、および、データに欠損値が存在することから、欠損値の除去にペアワイズ法 (Pairwise Deletion) が選択され、面積が比較されたことが示されています。
このレポートの最初のセクションには3つの検査の ROC 曲線面積 (ROC Curve Areas) が示されています。面積推定量の標準誤差 (Standard Error) に続いて、95% 信頼区間 (90% および 99% も選択可能) と、面積の値が 0.5 と有意な差があるかを判断する P 値があります。各分類状態に関するサンプルのサイズ (Sample Size) 欠損値 (Missing) が表示されます。欠損値の数は、データにあるものだけをあらわし、面積のペアワイズ除去の比較で各計算のペアに使用された数は反映されません。
第二のセクションでは面積のペアワイズ比較の結果が表示されます。Paired data type オプションを選択すると、DeLong, DeLong and Clarke-Pearson(2) を使用して面積が比較されます。Unpaired data type を選択すると、z 検定を使用して面積が比較されます。レポートには、データセットのすべてのペアの結果が表示されます。各面積のペアの差とその標準偏差、および 95% 信頼区間が計算されます。これに続いて、面積比較のカイ二乗解析 (Unpaired が選択された場合は Z 解析) および、それに関連づけられた P 値が表示されます。
Formatted Full Precision Display
このレポートは、完全精度が使用できる 4桁形式で数値結果を表示します。完全精度で数字を表示するには (信頼区間以外) をダブルクリックします。
Additional Graphs
いずれのレポート結果もそのデータを使用して追加のグラフを作成することができます。文献で確認できる例をいくつか示します。
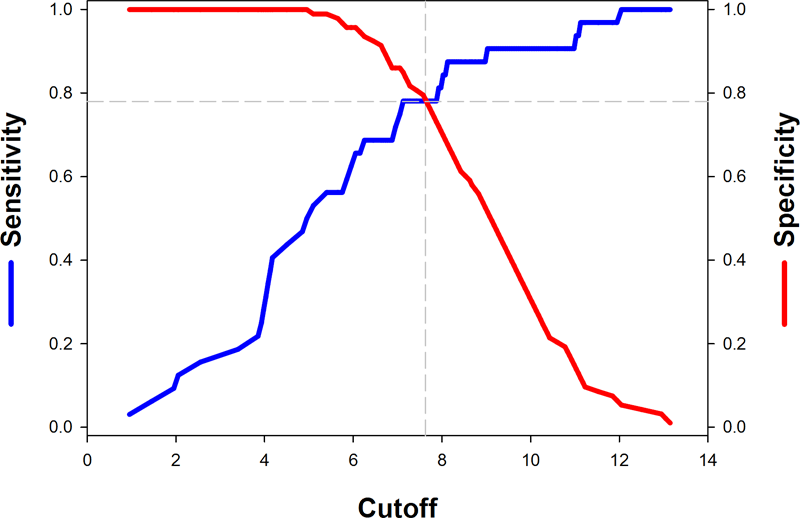 |
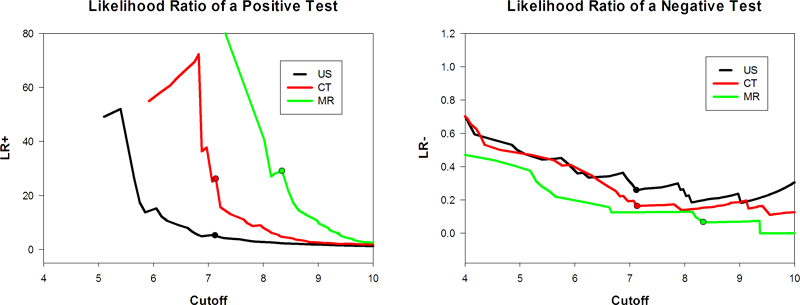 |
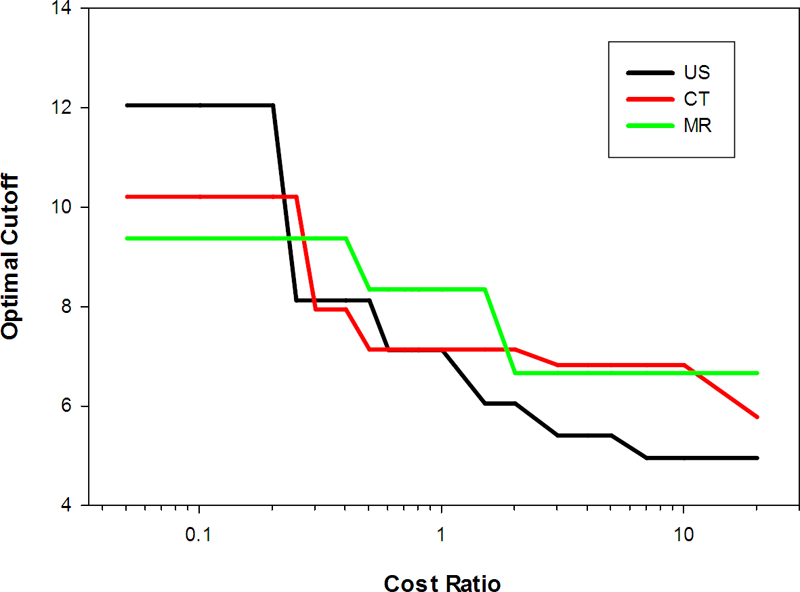 |
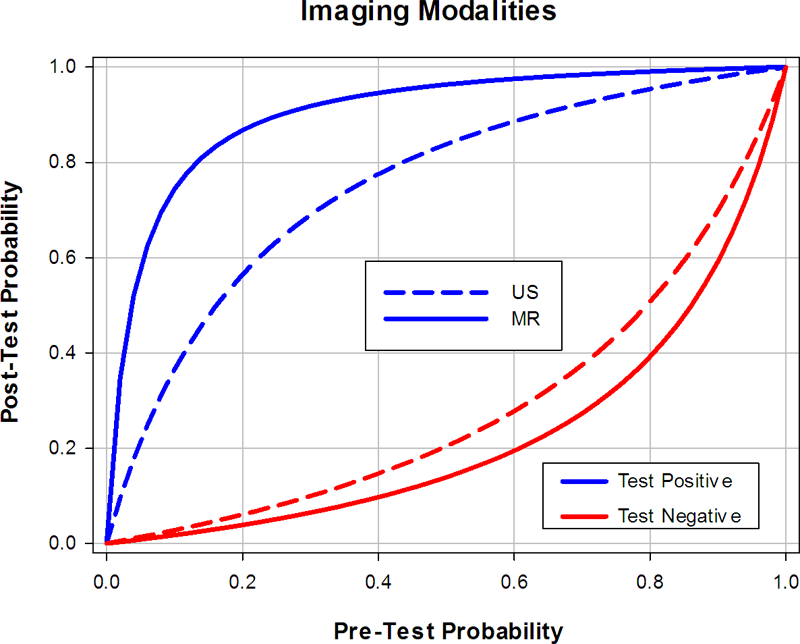 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}