|
| サイトマップ | |
||
|
| サイトマップ | |
||
Data Summary ウィンドウには、Data Worksheet ウィンドウで定義した変量に関する標準的な記述統計量が表示されます。Z 変量に関する情報 (下図参照)、および、別の X,Y Coordinates タブには座標の変量に関する情報が提供されます。共変量を分析する場合は、別の Regression タブに共変量 Z2 に対する Z の回帰に関する情報が表示されます。
Z 変量では、地球統計学的分析を行う前に変量の分布をより規格化するために対数正規 (底 e) または平方根 (square-root) 変換を指定することもできます。変量に変換を行う場合は、GS+ のレポートに含める内挿 (kriged) 値について変換後の表記にするか、または、オリジナルの測定ドメインに逆変換した表記のいずれかを選択することができます。逆変換 (backtransformation) は、すべての分析が終わった後に行いますので、自己相関 (autocorrelation) の結果に適用されることはありません。
Data Summary ウィンドウでは、小さく表示された度数分布イメージをクリックすることでフルウィンドウの度数分布、累積確率分布、または、正規確率分布にアクセスすることができます。
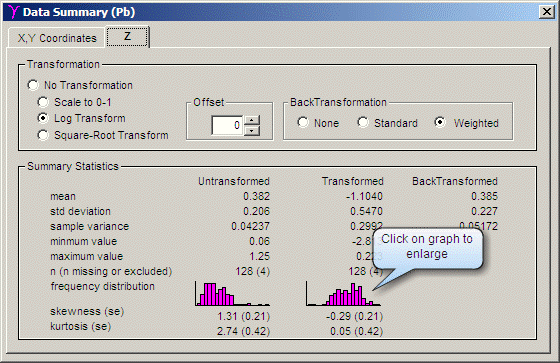 |
歪みのある (skewed) 度数分布を正規化したい場合は、Z 変量に対数正規、または、平方根変換を適用すると便利な場合が多くあります。データの値が非常に大きい場合は、その尺度を 0~1 の範囲にしても役に立ちます。指定した変換は、地球統計学的分析を行う前にデータセット内の全ての Z 値に適用されます。データワークシートのデータには変換は行いません。変換による有効性を調べるには、Frequency Distribution (度数分布図) や、Data Summary の確率分布と skewness (歪度) と kurtosis (尖度) の値を確認します。
このボックスには記述統計量 (Descriptive statistics) があります。なお、n は現在分析中のアクティブなデータ項目数である点に注目してください (上記画面では 128) 。n の missing 値は、x, y, z 値に欠損値が含まれることを理由に分析から除外されたり、Filter コマンドによって分析から除外されたワークシートのレコード数です (上記画面では 4)。重複する値を平均化した場合は (Duplicate Values ダイアログ参照)、与えられた地点の全ての重複値は1レコードとしてカウントされ、その重複が欠損値としてカウントされることはありません。
skewness (歪度) と kurtosis (尖度) の後に続く括弧内の数字は、これらの項の標準誤差 (standard errors) です。
分析データに共変量 (Z2) が含まれている場合は、以下の規則が適用されます:
これは、共分散分析 (covariance analysis) では、Z に関する全てのサンプルポイントは、共変量 Z2 と共にあることを想定していますが、Z2 は Z を採集した地点の他にも採集されます。従って、Z に関する要約統計と自己相関分析は、Z2 と共にある Z 値についてしか実行されません。一方、Z2 に関する要約統計と自己相関分析は、一致する Z 値が存在するか否かにかかわらず全ての Z2 値について実行されることになります。