|
| サイトマップ | |
||
|
| サイトマップ | |
||
この解析は、Fickett による論文 [Nucl. Acids Res. 17(10):5303 (1982)] に依拠します。この TestCode という名前の付いたアルゴリズムは、DNA のコード領域において、ある特定のアミノ酸を指定するコドン (同義語コドン) は、それぞれ異なる頻度で使用されるという事実を利用したものです。この結果、非コーディング DNA と比較してコーディングシーケンスを有する DNA の各3番目の位置のヌクレオチドの分布に偏りができます。Fickett は、8つの数値パラメータを定義して、ある DNA セグメントが実際にペプチドをコーディングする尤度 (likelihood) を評価するのに利用できるようにします。CodonPreference と比較して TestCode を利用するひとつのメリットは、コドン選好テーブル (codon preference table) を使用する必要がないという点です。つまり、TestCode 解析は、コドン選好テーブルが既に分かっている DNA だけでなく、任意の DNA について解析を実行できる訳です。
図 4.42 に示すのは、この解析のセットアップパネルです。デフォルトで指定された窓サイズ (Window size) は、Fickett による推奨値 200 ヌクレオチドです。窓の幅を狭くすれば、解析結果は局所的になりますので、ORF を検索する目的であればいいですが、塩基組成の局所的なバイアス (偏り) の影響をそれだけ受けやすくなります。ORF のセッティングと Display オプションについては、“CodonPreference” をご覧ください。
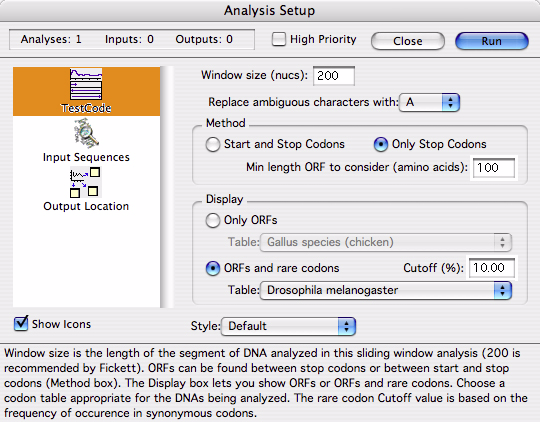 |
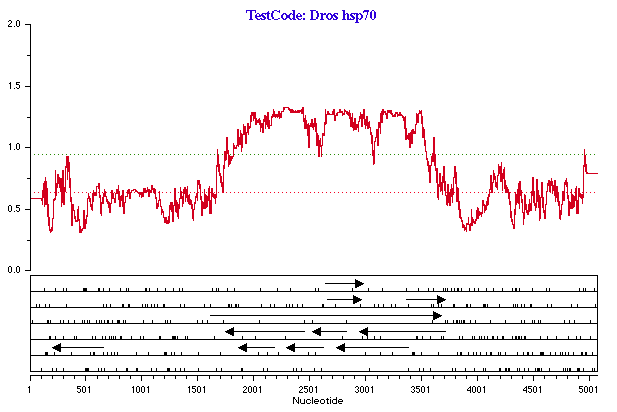
図 4.43 に示すのは、この解析の出力結果です。上の点線 (グリーン) より上の曲線部分は、タンパク質を実際にコーディングする確率が 95% となる領域です。下の点線 (赤) より下の曲線部分は、実際にコード領域となる可能性は 5% しかありません。2つの点線に挟まれた部分は、TestCode の出力結果だけで判断するなら、タンパク質をコードする領域ではないと考えるのが一番安全です。ある領域がコード領域であるかどうかを評価するには、出力オブジェクトの下側の部分にある ORF とレアコドンプロットも吟味する必要があります。プロットされた TestCode 値はあくまでも統計的属性であるため、その解釈については慎重になる必要があります。値がグリーンの点線より上にあるからといって、その領域が絶対に (definitely) コード領域であるという訳ではありません。逆に、曲線が赤の点線より下にあるからといって、その領域がタンパク質をコードする可能性が全く排除される (cannot) 訳ではありません。
 |
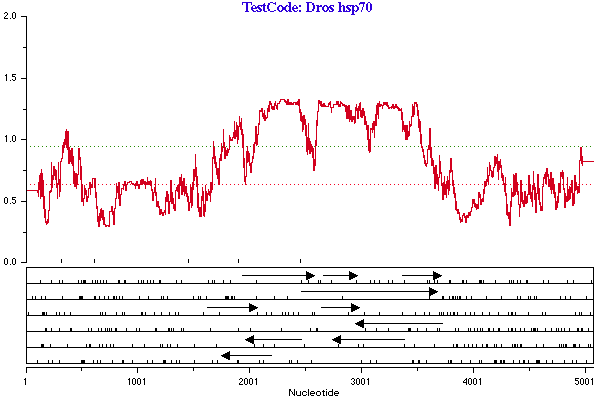
この解析には、曖昧 (多義性) 文字 (Y, R, N など) を取り扱う手段は一切ありませんので、解析するシーケンスに曖昧文字があった場合にどうするかを指定する必要があります (これはセットアップパネルの一番上の部分で指定することができます - 図 4.42 参照)。図 4.44 では、Hsp70 シーケンスに曖昧文字が一部導入されており、それらはこの解析で全て A に置き換えられています。プロット内に目盛りで示されているのが曖昧文字の位置です。2500 付近に曖昧文字があるため、2400 付近で曲線に落ち込みがあり、読み枠 #3 の ORF が途切れている点に注目しましょう。
 |
出力オブジェクトの下に表示されている ORF インジケーターは、ORF 解析の ORF インジケーターと同様に操作できますので、ORF 矢印から DNA とそれに対応するペプチドシーケンスを直接抽出することができます。