|
| サイトマップ | |
||
|
| サイトマップ | |
||
以上で、購入費用とリース費用の構築が完了しましたので、これらを1つの変数に結合することができます。ここでのインデックスは Finance Option になります。
Variable Payments :=
Table (Finance_option)(Car_price, Lease_payment)
Payments というタイトルの変数を新規作成します。
Definition フィールドを開き、Expression ポップアップメニューから Table を選択します。
Indexes ウィンドウが表示されます。Finance option インデックスを選択したら、Selected Indexes リストにこれを移動します。OK をクリックします。Edit Table が表示されます。
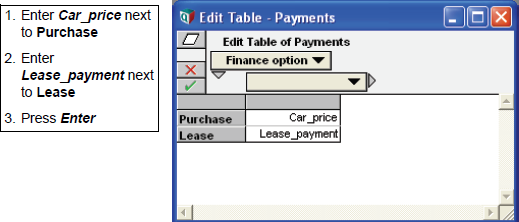 |
このテーブルと前に作成したテーブルの間に重要な違いがある点にお気づきかも知れません。前のテーブルでは、テーブルのセルに数値を入力しましたが、今回入力したのは式 (expressions) です!式をテーブルのセルに入力してもいいんです。ごくわずかな例外はありますが、通常 Definition 行に入力するような内容であれば、数式、論理式、条件式などを組み合わせることができます。これ以外の事例は、この章の後の方で紹介します。
次に、新たに作成した変数の結果を見てみましょう。
Payments 変数を選択して、Results ボタン ( ![]() ) をクリックします。
) をクリックします。
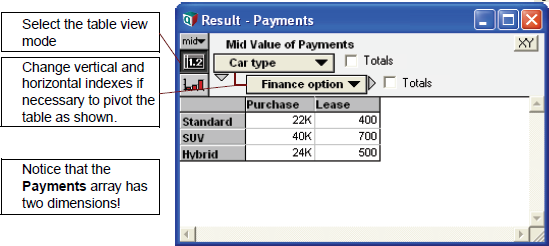 |
面白い結果になりました!この配列の定義で呼び出したのは1つのインデックスのみであるにもかかわらず、この配列には2つの次元が含まれているからです。
Variable Payments :=
Table (Finance_option)(Car_price, Lease_payment)
テーブルの定義には Finance_option しか含めていないのに、なぜ、Car type も含まれたのでしょうか?
Car type がインプット変数 Car price と Lease payment のインデックスになっているからです。
いま見たのが正に Analytica の最もパワフルな機能のひとつである配列抽出 (array abstraction) です。すなわち、配列化されたインプット変数の次元が、アウトプットされる式の結果に自動的に組み込まれる機能です。配列抽出の一般原則は、次のようにまとめることができます:
Analytica の式の結果は、使用するインプット変数の全ての次元、および、その式で定義された次元がまとめて配列化される。