12) GLM での Post Hoc テスト
DIET$ と FOOD$ の間には有意な交互作用が存在するため、主効果の判定には注意が必要です。SYSTAT の高度な仮説検定機能を使用し、「Bonferroni の修正済み確率」を実行して平均値の組の差の検定を行ってみましょう。
使用するサンプルデータについてはこちらをご覧ください。
- 次のようにメニューを選択します。
- 「Analyze (解析)」>
「Analysis of Variance」>
「Pairwise Comparisons (対比較)...」
- 「Groups」に「DIET$ * FOOD$」を指定し、「Tests (検定)」で「Bonferroni」を選択します。
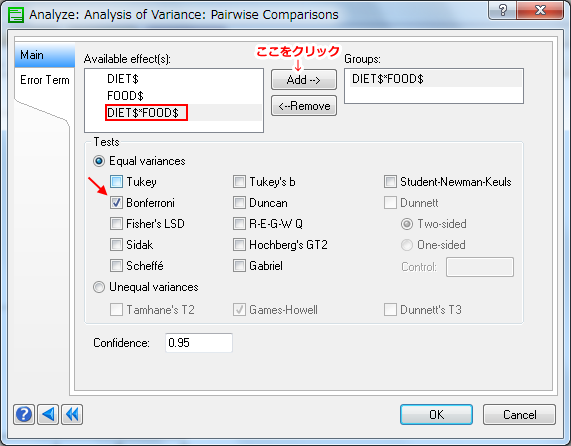
- 「OK」をクリックします。以下の結果が得られます。
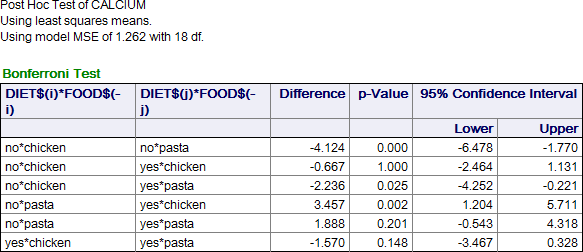
この表の 6つの差 (および確率) の 4 つに注目します。 まず食品のタイプ別に、次に食品の種類別に見てみましょう。
- 通常の食品 (DIET$ が no のもの) では、chicken と pasta のカルシウム含有量の平均の差が大きいことが分かります (平方根の差は -4.124、p < 0.0003688)。
- ダイエット食品 (DIET$ が yes のもの)では、chicken と pasta のカルシウム含有量の平均値の差は有意ではありません (平方根の差は -1.570、p = 0.148)。
- pasta 製品では、DIET$ が yes と no の群のカルシウム含有量の差は有意ではありません (-1.888、p = 0.201)。
- chicken 製品でも、DIET$ が yes と no の群のカルシウム含有量の差は有意ではありません (-0.667、p = 1.000)。
これらの平均値の点グラフを見ると、いっそう明らかになります。
点グラフ (Dot Chart) の作成
- 次のようにメニューを選択します。
- 「Graph (グラフ)」>
「Summary Charts (サマリー チャート)」>
「Dot (点グラフ)... 」
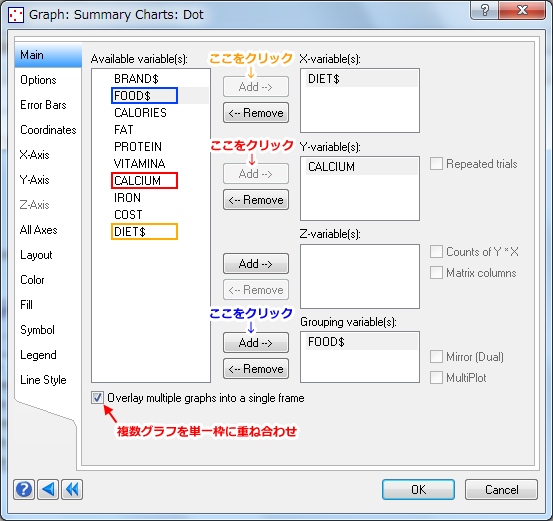
- Y 変数として「CALCIUM」を、X 変数として「DIET$」を選択します。
- Grouping variable (群分け変数) として「FOOD$」を選択します。
- 「Overlay multiple graphs into a single frame (複数グラフを単一枠に重ね合わせ)」を選択します。
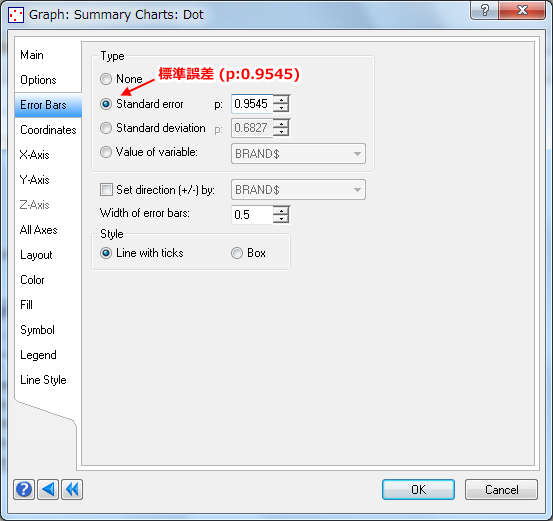
- 「Error Bars」タブをクリックし、Type グループから「Standard error (標準誤差)」を選択し、P 値として「0.9545」を指定します。
- 「Options」タブをクリックし、「Line connected in left-to-right order (左から右の順に線で結ぶ)」を選択します。
- 「OK」をクリックします。以下のグラフが得られます。
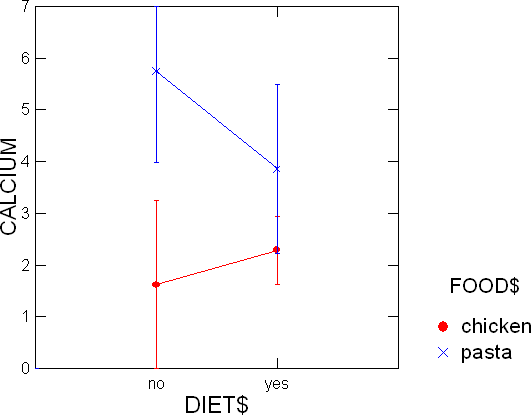
通常の食品 (DIET$ が no のもの)ではエラー バーは重なっていません。これは、パスタ製品 (x pasta) と鶏肉製品 (● chiken) のカルシウム含有量の差が有意であることを示しています。 一方、ダイエット食品(DIET$ が yes のもの)ではエラー バーが重なっていて、食品の種類による有意差はないことを示しています。
まとめ
データ分析の第一歩はデータの観察です。 SYSTAT には、変数間の関係、結果に大きな影響を与える外れ値、および詳細な解析に必要なデータ変換のためのパターンの識別に役立つグラフが豊富に用意されています。
また、データの解析に必要な統計解析プロシージャも豊富に用意されています。 この章では、最も一般的で基本的な統計解析の手法について説明し、簡単な例を使用して、初歩的な操作を実行しました。