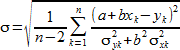23.10 デミング回帰
デミング回帰 (Deming Regression) を使うのは:
- 最適な当てはめ直線 (best-fit line) の傾きと切片を決定したいとき。
- デミング回帰について
- デミング回帰を実行する
- デミング回帰のデータを配置する
- デミング回帰オプションを設定する
- デミング回帰を実行する
- デミング回帰の結果を解釈する
- デミング回帰の結果グラフ
1. デミング回帰について
デミング回帰 (Deming Regression) の主要目的は、独立変数と従属変数の両方に不確かさ (uncertainties) が存在するときに、その最適な当てはめ直線の傾きと切片を決定することです。直線の傾きを b であらわし、切片を a であらわした場合、与えられた観測データが得られる尤度を最大化することは、以下の最小化問題を解くのと同じです:
ここで、(xk, yk) は k 番目の観測データ、σxk は xk の標準偏差、そして、 σyk は yk の標準偏差です。
デミング回帰には2つのタイプがあります:単純デミング回帰 (Simple Deming Regression) と一般デミング回帰 (General Deming Regression) です。全ての観測データで2変数のデータの誤差がそれぞれ一定である場合は、単純デミング回帰を使います。独立変数と従属変数の2つの定誤差の値が互いに等しい場合、単純デミング回帰はしばしば直交回帰 (Orthogonal Regression) と呼ばれます。
一般デミング回帰を使うと、各観測データにおける任意の値の誤差を取り扱うことができます。
2. デミング回帰を実行する
デミング回帰 (Deming Regression) を実行するには:
- ワークシートに適切なデータを入力または配置します。詳しくは、デミング回帰のデータを配置するをご覧ください。
- 必要があれば、Deming Regression オプションを設定します。詳しくは、デミング回帰オプションを設定するをご覧ください。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから以下を選択します:
Regression→Deming
- レポートグラフを作成します。詳しくは、デミング回帰の結果グラフをご覧ください。
- 検定を実行します。
3. デミング回帰のデータを配置する
デミング回帰データの入力には、観測データの対をあらわす2つの列を使います。ここで、第1の座標は独立変数を、第2の座標は従属変数を参照します。
4. デミング回帰オプションを設定する
Report (レポート)
Standard errors of parameters (パラメーターの標準誤差)
- Apply correction factor estimated by the reduced chi-square :X と Y 両方に関する全てのデータの誤差が共通の倍率 σ であることしか分かっていない場合に選択します。この倍率は、この当てはめ分析で得られる Reduced chi-square (換算カイ二乗 ) 統計量の平方根として見積もります。切片と傾きの最適な当てはめのパラメーターがそれぞれ a と b で与えられ、観測数を n とする場合、その推定量は次式であらわされます:
ここで、 (xk, yk) は k 番目の観測データ、σxk は xk の標準偏差、σyk は yk の標準偏差です。
このオプションは、最適なパラメーター値の計算には影響を及ぼしませんが、両パラメーターの標準誤差の計算に影響します。
- Add table of predicted means:これを選択すると、観測データ毎に XY 両変数の予測平均 (すなわち真の値) のテーブルがレポートに追加されます。このテーブルには、観測データと予測平均間の残差 (Residual) の値も含まれます。
- Add parameter covariance matrix:これを選択すると、パラメーターの 2x2 の分散-共分散行列がレポートに追加されます。
Confidence Intervals (信頼区間)
- Confidence level (信頼水準):パラメーターと回帰直線の信頼帯の信頼区間の信頼水準を百分率で設定します。デフォルトの値は 95% です。
Graph (グラフ)
- Create new graph:これを選択すると、レポート作成後にデミング回帰の結果をあらわすグラフが作成されます。デフォルトの結果グラフは、回帰直線と生データで構成されます。このグラフにはエラーバーは表示されませんが、あとからグラフを修正することで追加することができます。
Graph features
- Add Scatter plot of predicted means:これを選択すると、各データポイントの予測平均の散布図が回帰直線上に配置されます。予測平均のデータもワークシートに表示されます。
- Add Confidence Bands:これを選択すると、入力データの範囲を超える独立変数の特定の値における予測平均の信頼区間の上限と下限をあらわす2つの曲線がグラフに追加されます。ワークシートにはこの信頼帯のデータが表示されます。
5. デミング回帰を実行する
検定を実行する前にデータを選択したい場合は、データ範囲をマウスポインタでドラッグしておきます。
- Analysis タブをクリックして、SigmaStat グループの Tests ドロップダウンリストから以下を選択します:
Regression→Deming
Regression Wizard の Deming Regression - Data Format パネルが表示され、データフォーマットを選択するよう指示されます。
- Data Format ドロップダウンリストから XY Pair または XY Pair-Errors を選択します。詳しくは、デミング回帰のデータを配置するをご覧ください。
- Next をクリックして、検定するデータ列を選択します。検定を実行する前に列を選択していれば、選択した列が Selected Columns に表示されます。
- Selected Columns リストに別のワークシート列を割り当てたい場合には、ワークシートで直接その列を選択するか、Data for Data ドロップダウンリストからその列を選択します。
Selected Columns リストの最初の行に割り当てられるのは最初に選択した列で、リストのそれ以降の行に2列目以降が割り当てられます。各行には、選択した列の番号またはタイトルが表示されます。raw および indexed データの場合、ワークシートの2列を選択するよう指示されます。統計的要約データの場合は、3列を選択するよう指示されます。
- 選択した内容を変更するには、リストの割り当てを選択したあと、ワークシートから列を選択しなおします。Selected Columns リストの内容をダブルクリックすることによって、列の割り当てを消去することもできます。
- Finish をクリックすると、選択した列に関する t 検定が実行されます。計算が完了すると、レポートが表示されます。
6. デミング回帰の結果を解釈する
デミング回帰レポートには、入力に使用したデータソースの他に、回帰分析の数値結果が含まれます。冒頭には、他の統計的検定のレポートにも含まれる通常のヘッダ情報 (日付、タイトル、およびデータソース) があります。このレポートの情報は、以下に示すセクションに分かれます:
- レポートタイトル:レポートのタイトルは、ウィザードのデータフォーマットに XY Pair を選択した場合は Simple Deming Regression、データフォーマットに XY Pair-Errors を選択した場合は General Deming Regression になります。
- 入力データ列:X および Y の測量として選択した列がそれぞれ最初に表示されます。次のエントリーは、Simple Deming Regression の場合、X および Y 測量に関する2つの標準偏差の定数です。General Deming Regression を使用した場合、X および Y 変数の標準偏差としてそれぞれ選択した列が代わりに表示されます。
- データサマリー:このセクションには、選択した観測データの総数 (Number of observations) と欠損データ行の総数 (Number missing) が単純に表示されます。欠損データ行の定義は、前のデミング回帰ウィザードの説明で紹介したとおりです。
- 回帰測量:2つのデータ変数の間の関連の強さと、このモデルで使用した誤差分散の大きさをはかる4つの値があります。
- 相関係数 (correlation coefficient) は、独立変数と従属変数のデータ間の線形相関をはかる尺度です。Simple Deming Regression では、デミング回帰の代替として使用する単純線形回帰の判定基準に、十分に大きな相関係数 (> .975) を使用することがあります。
- カイ二乗統計量 (chi-square statistic) は、最適な当てはめパラメーターを求めるのに最小化した最適な合計値です (対数尤度関数を最大化するのと同じ) 。データに関する正確な (または殆ど正確な) 標準偏差を与えた場合、この統計量は、自由度 N-2 のカイ二乗分布の近似となります。ここで、N は観測データ対の数です。
- 換算カイ二乗 (reduced chi-square statistic) は、カイ二乗統計量を単純に自由度で割った値です。データ誤差に対して倍率を適用するオプションを選択したと仮定すれば、そのデータの分散の大きさが推定されます。
- 自由度 (degrees of freedom) は、N-2 の整数値です。ここで、N は、観測データの対の数で、N-2 = (X と Y に関する観測データ 2N) – (XY 両平均値に関する線形定数 N) – (パラメーター数 2) となります。
- パラメーター推定量:最適な当てはめ直線の切片 (Intercept) と傾き (Slope) パラメータに関する推定値と統計量、および、ある統計量の漸近値のテーブルです。レポートされる統計値は、パラメーターの標準誤差とそれぞれの信頼区間です。
- この統計量は、データセットだけでなく選択したオプションによっても変化します。オプションダイアログボックスで、データ誤差の解釈を、絶対値、または、ある倍率の相対値として選択できます。また、SigmaPlot の設定ファイル (spw.ini) の設定内容を編集して、標準誤差の2つの推定法、観測データの値を直接ベースとするデルタ法と呼ばれる手法と類似する York と Williamson の手法 (York and Williamson’s method) か、予測平均の使用をベースとする最尤理論 (MLE method) に基づく手法のいずれかを選択することもできます。
- Covariance Matrix (共分散行列):2 x 2 の行列で、対角線上には2つのパラメータの分散が、非対角線上には両パラメータの共分散が配置されます。
- Hypothesis Testing (仮説検定):2つの F 検定を使用して、傾きはゼロである (Test for slope = 0)、および、傾きは 1 である (Test for slope = 1) という2つの仮説を検定します。
- Predicted Means (予測平均):データを抽出した分布に関する予測 (推定) 平均のテーブルです。観測データポイント毎に、X と Y の測量に関する2つの予測平均があります。測定値とその予測平均との間の残差 (Residual) も変数ごとに表示されます。
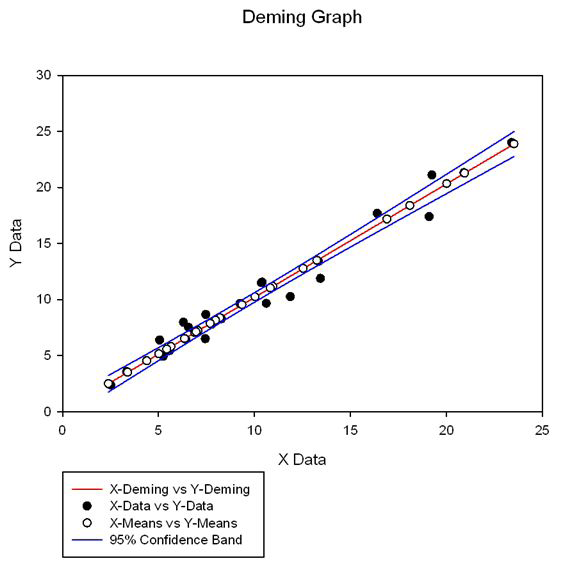
7. デミング回帰の結果グラフ
デミング回帰のデフォルトのグラフには、回帰直線と共に生データの散布図がプロットされます。オプションダイアログには、このグラフにプロットを追加するためのオプションが用意されています。
オプションの1つには、各観測データごとに推定される平均の対の散布図を追加するものがあります。回帰直線はこれらの平均の関係を直線であらわしたものなので、この散布図は、回帰直線上にプロットされることになります。
従属変数の予測値の信頼帯もグラフに加えることができます。これらの帯は、X の規定値を仮定した Y の予測値の精度をはかる尺度になります。