21.2 z 検定を使って割合を比較する
z 検定で割合を比較するのは次の場合です:
- 比較する群が2つある場合。
- 各群のサンプルサイズ (観測数) の合計が既知の場合。
- 単一カテゴリに属する各群の割合 p が分かっている場合。
お持ちのデータが2つのカテゴリに属する各群の観測数である場合は、代わりに分割表の LogRank 生存分析 (LogRank Survival Analysis of contingency tables) を実行します。これによって出力される P 値は、z 検定の P 値と同じです。群またはカテゴリが2つ以上の場合も、分割表の LogRank 生存分析を実行します。
1. z 検定について
単一のカテゴリやクラスに属する2群の割合 (proportions) に有意差があるか否かを判定するには、割合を比較する z 検定を使います。z 検定の前提条件は:
- いずれの観測データも互いに排他的な2つのカテゴリのいずれかに属していること
- すべての観測データは独立であること
2. z 検定を実行する
z 検定を実行するには:
- ワークシートに適切なデータを入力または配置します。詳しくは、z 検定のデータを配置するをご覧ください。
- 必要があれば、z-test オプションを設定します。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから以下を選択します:
Rates and Proportions → z-test
- 検定を実行します。
- z-test レポートを表示して解釈します。詳しくは、割合の比較結果を解釈するをご覧ください。
3. z 検定のデータを配置する
2つの割合を比較するには、第1列に2つのサンプルサイズを、第2列に各サンプルに対応する観測割合 p を入力します。このときの配置は必ず2行2列にします。サンプルサイズは整数に、観測割合は 0 から 1 の間にする必要があります。
4. z 検定オプションを設定する
z 検定オプションを使用するのは:
- z 検定レポートにデータの信頼区間を表示する場合
- z 検定で実行する検定の検出力 (Power) をレポートに表示する場合
- イェーツの補正因子 (Yates Correction Factor) を有効にする場合
z 検定オプションを変更するには:
- 検定オプションの変更後に検定を実行するに際して、検定の実行前にデータを選択しておきたい場合は、対象とするデータ列をポインターでドラッグしておきます。
- Analysis タブの SigmaStat グループにある Select Test ドロップダウンリストから z-test を選択します。
- 現在の検定の Options をクリックします。
Options for z-test ダイアログボックスが表示されます。詳しくは、Options for z-test をご覧ください。
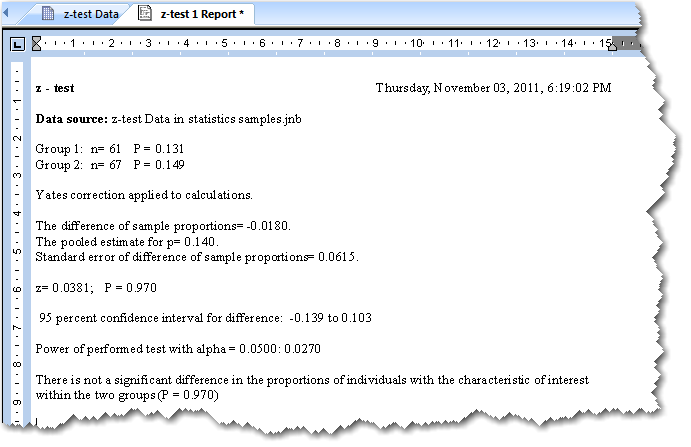
Options for z-test のダイアログボックス
 |
- 検定オプションを選択するにはチェックボックスをクリックします。SigmaPlot を次回以降起動するときは、ここで選択したオプションの内容が保持されます。
- 検定を続行するには、Run Test をクリックします。
- 現在の設定内容を適用して、オプションダイアログを閉じるには、OK をクリックします。
7.2.4.1 Options for z-test
- Power, Use Alpha Value:選択すると検定の感度を検出します。検出力、すなわち、検定の感度は、2群の割合の間に真の差があるとすれば、この検定でそれを検出できる確率です。
アルファの値を変更するには、Alpha Value ボックスの数値を編集します。
アルファ (α) は、誤って差があると判断しても良しとする確率です。SigmaPlot で提示される値は、α = 0.05 です。この設定は、誤りを許容する確率が 20分の1であることを示します。すなわち、P < 0.05 であれば有意な差があると判断できることになります。
α 値を小さくすると、有意差があると結論付ける要件がそれだけ厳格なものになりますが、差があるにもかかわらずないと結論付けてしまう可能性はそれだけ大きくなります。α 値を大きくすると、差があると結論付ける要件はそれだけ容易になりますが、誤判定をレポートしてしまうリスクが増加することになります。
- Yates Correction Factor:統計的検定に2 x 2 分割表の分析や、マクニマーの検定 (McNemar’s test) など自由度1の χ2 分布を使用する場合、算出される χ2 は、実際の χ2 検定統計量の分布と比較すると P 値が非常に小さくなる傾向があります。理論上の χ2 分布は連続的ですが、この χ2 検定統計量の分布は離散的であるからです。
計算される χ2 の値を下げてこの食い違いを補うように調整するには、イェーツの補正因子 (Yates Correction Factor) を使います。イェーツの補正を使うことで、検定を保守的なもの、例えば、P 値が大きくすることで誤判定の結論を下す可能性を低く抑えることができます。イェーツの補正は、2 x 2 分割表や自由度1の χ2 分布を元に P 値を算出するその他の統計で適用します。
選択されたチェックボックスをクリックすることで、Yates Correction Factor を有効または無効にすることができます。
- Confidence Interval:これは、割合の差の信頼区間です。指定された区間を変更するには、このボックスを選択して 1 ~ 99 までの任意の数値を入力します (最も一般に使用される区間は 95 と 99 です)。
5. z 検定を実行する
検定を実行するには、検定するデータを選択する必要があります。検定ウィザードの Select Data パネルを使用して、検定したいデータを含むワークシートの列を選択したり、お持ちのデータがどのような状態でワークシートに配置されているかを指定します。
z 検定を実行するには:
- 検定の実行前にデータを選択しておきたい場合は、対象とするデータ列をポインターでドラッグしておきます。
- Analysis タブをクリックします。
- SigmaStat グループにある Tests ドロップダウンリストから次を選択します:
Rates and Proportions → z-test
検定ウィザードの Select Data パネルが表示されます。検定を選択する前に列を選択していれば、選択された列が selected columns リストに表示されます。列をまだ選択していない場合は、データを選択するようダイアログボックスで指示されます。
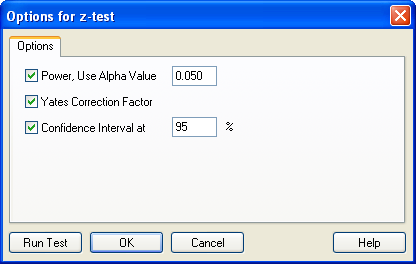
z-test — Select Data
ダイアログボックスにデータ列を選択するよう表示された例
 |
- Selected Columns リストに別のワークシート列を割り当てたい場合には、ワークシートで直接その列を選択するか、Data for Size または Data for Proportionドロップダウンリストからその列を選択します。
最初に選択した列は、Selected Columns リストの Size 行に割り当てられ、二番目の列は Proportion 行に割り当てられます。各行には、選択した列のタイトルが表示されます。選択できるデータ列は、Size および Proportion それぞれ1つだけです。
- 選択した内容を変更するには、リストの割り当てを選択したあと、ワークシートから列を選択しなおします。Selected Columns リストの内容をダブルクリックすることによって、列の割り当てを消去することもできます。
- Finish をクリックすると、検定が実行されます。z 検定の結果をあらわすレポートが表示されます。詳しくは、割合の比較結果を解釈するをご覧ください。
6. 割合の比較結果を解釈する
z 検定のレポートには、使用された統計値のテーブル、z 統計量、および、その検定の P 値が表示されます。Options for z-test ダイアログボックスを使えば、割合の差に関する信頼区間を表示させることもできます。
z 検定の割合の比較結果のレポート例
 |
結果の説明
数値による結果に加えて、拡張された結果の説明が表示されることがあります。この説明テキストは、Options ダイアログボックスで有効または無効にすることができます。また、表示する小数点以下の桁数についても Options ダイアログボックスで設定できます。
6.1 統計サマリー
z 検定のサマリーテーブルには、各群のサイズ n とそのカテゴリにおける各群のの割合 p が一覧で表示されます。これらの値は、データから直接取得されます。
- Difference of Proportions:2つの群の割合 p の間の差です。
- Pooled Estimate for P:2つの標本をプールして求めた母集団の割合 (母比) p の推定値です。「2つの標本は同一の母集団から抽出されたものである」という仮説を検定します。根底にある母集団のもつ性質と抽出する特定の標本の両方によって変ります。
- Standard Error of the Difference:差の標準誤差は、この差を見積もる精度の尺度です。
6.2 z 統計量
z 統計量は次式であらわされます:
z の絶対値が大きければ、2つの集団の割合に差があると結論付けることができます。z 統計量が大きければ、標本抽出のばらつきのみで期待される差より、2つの割合の差が大きい (例えば、2群の割合の間の差は統計的に有意である) ことを示します。z が小さければ (0 に近ければ)、2群の割合の間に有意差がないことを示します。
Options for z-test ダイアログボックスでイェーツの補正を有効にしていれば、z の計算結果は z の理論値と計算値の間の差を考慮してわずかに小さくなります。
- P Value:P 値は、2群の割合の間に差があると誤って結論付けてしまう確率です (例えば、帰無仮説を誤って棄却する、すなわち第一種の誤り (Type I error) を犯す確率)。
P 値が小さいほど、標本が異なる割合をもつ母集団から抽出される確率は高くなります。伝統的には、P < 0.05 であれば、有意差があると結論付けることができます。
6.3 Confidence Interval for the Difference
信頼区間にゼロが含まれていなければ、指定した信頼水準で割合の間に有意差があると結論付けることができます。このことは、P < α とあらわすこともできます。ここで、α は、誤って差があると結論付けても良しとする確率です。
信頼水準の調整は Options ダイアログボックスでおこないます。通常は、100(1 – α)、すなわち、95% です。信頼の値が大きいほど区間は広くなり、小さいほど区間は狭くなります。詳しくは、Power をご覧ください。
この結果は、Options for z-test ダイアログボックスで無効にしない限り表示されます。
6.4 Power
z 検定の検出力 (Power)、すなわち感度は、群間に真の差がある場合、その検定で群間の差を検出できる確率です。検出力が 1 に近づくほど、その検定の感度は高くなります。z 検定の検出力は、サンプルサイズと測定された各標本の割合によって影響を受けます。
この結果は、Options for z-test ダイアログボックスで無効にしない限り表示されます。
- アルファ:アルファ (α) は、誤って差があると結論付けすることが許容される確率です。この誤りを、第一種の誤り (Type I error) と呼ぶこともあります (第一種の誤りは、効果がないという帰無仮説が真であるにもかかわらずそれを棄却するときです)。
α 値は、z-test Power ダイアログボックスで設定します。提示される α = 0.05 という値は、許容する誤りを 20分の1にすることを示します。α の値を小さくするほど、有意差があるとの結論に至る要件はそれだけ厳格になりますが、その反面、差があるにもかかわらず差がないと結論付けてしまう可能性は高くなります (第二種の誤り:Type II error)。α の値を大きくすれば、差があるという結論付けは容易になりますが、その反面、誤った差をレポートするリスクが高まります (第一種の誤り:Type I error)。