|
| サイトマップ | |
||
|
| サイトマップ | |
||
反復測定検定のデータをワークシートに配置する方法は以下のとおりです:
反復測定検定では、データに要約統計量を使用することはできません。
| ※ Tip:検定を選択する前にワークシートのブロックを選択することでデータの一部に対して反復測定検定を実行することができます。もしこの方法を使用する場合は、全てのデータ列が互いに隣り合っていることを確認してください。 |
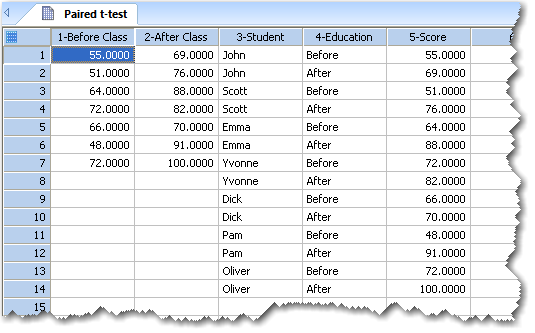 |
上記ワークシートの列1と列2は、生データ (Raw data) として配置したものです。列3、4、5は、インデックス付きデータとして配置したもので、このうち、列3は被験者 (subject) 列、列4は因子 (factor) 列、列5はデータ列となります。
生データ (raw data) フォーマットでデータを入力するには、ワークシートの列を各処理ごとに分けてデータを入力します。生データは、二元配置分散分析 (Two Way ANOVA) を除く全ての検定で利用することができます。
| ※ 重要:生データに使うワークシートの各列は、長さを同じにする必要があります。もし、欠損値があれば、その個体は無視されるか、または、パラメトリックな ANOVA の場合は、一般線形モデルを使用することで利用可能な全てのデータを活用することができます。 |
インデックス付きデータ (Indexed data) では、処理 (treatments) 用の1列と、処理に対応する個々のデータポイントが別の1列で構成されます。一元配置反復測定分散分析 (One Way Repeated Measures ANOVA) では、被験者 (subject) 用のインデックスがさらにもう1列必要となります。二元配置反復測定分散分析 (Two Way Repeated Measures ANOVA) では、因子列がさらにもう1列必要となるので、合計4列で構成されることになります。
データの一部のみの比較を検討している場合は、処理 (treatment) 用のインデックス列を左端として、第2因子 (second factor) のインデックスをその次の列に (二元配置分散分析の場合のみ)、被験者 (subject) のインデックスをその次の列に (反復測定分散分析の場合)、そして、最後にデータ列が右端になるよう配置します。
| ※ Tip:生データにインデックスを付けたり、インデック付きデータを生データに変換することができます。 |