|
| サイトマップ | |
||
|
| サイトマップ | |
||
“Help” -> “Tutorial Data” とクリックし、“Lady Baltimore” を選択して、結果を読み込みます。
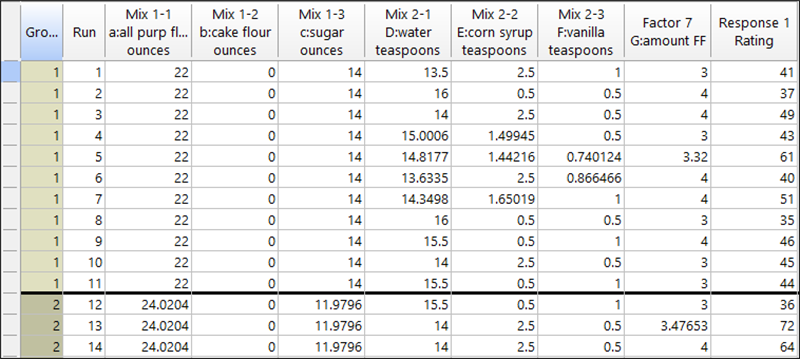
データを含む計画は、以下のスクリーンショットのようになります。構築したカスタム計画は整合性を保つために、チュートリアルの実行順序に置き換わることに注意してください。
 |
解析を始めるには Analysis ブランチ下の “R1: Rating” ノードをクリックします。標準の RSM 解析と同様に、新しいタブ一式が画面上部に表示され、解析の完了に必要な順序で左から右へ配置されます。
 |
Transform には、このページに適用できるさまざまな選択肢が用意されています。この時点でこれが役立つか不明な場合は、次の “Model” タブをクリックしてください。そこでは、どの選択肢が有益なのかを判断することができる診断があり、そこに後からチェックされます。
Model タブでは、Combined Model(4次項のみに減らされた)が検討のために表示されます(Process order において、項および計画モデルの隣には緑色で “![]() ” と表示されます)。この時点で ANOVA(REML)をクリックして次に進むと、モデルのすべての計画が評価されます。しかし、できる限り有意ではない項を除いた中から、最も適したモデルを選択するために、いくつか解析を行うことをお勧めします。
” と表示されます)。この時点で ANOVA(REML)をクリックして次に進むと、モデルのすべての計画が評価されます。しかし、できる限り有意ではない項を除いた中から、最も適したモデルを選択するために、いくつか解析を行うことをお勧めします。
 |
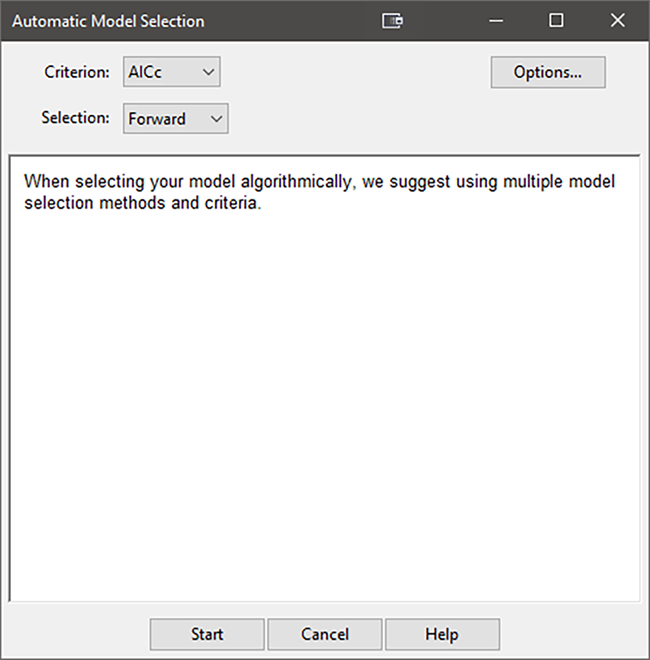
これをコンピューターで自動的に行うには、“Auto Select...” ボタンをクリックします。解析を実行するには、デフォルトのまま Criterion に AICc を、 Selection に Forward を適用し、“Start” ボタンをクリックします。計画モデルの項が検討され、AICc 基準を最も改善する項が選択されると同時に、基準の改善ができなくなるまで、それらの項がモデルに追加されます。
 |
モデルを選択する際に追加された項が、各段階における AICc 基準と共に表示されます。アルゴリズムモデルの選択と使用した基準の詳細については、Help ボタンをクリックしてください。または、“Accept” をクリックして、次に進んで結果のモデルを評価してください。“ANOVA (REML)” タブをクリックすると、選択したモデルが階層的ではないという警告が表示されます。必ず “Yes” をクリックして、階層を修正してください。こうすることで確実に低次の項が表示され、たとえ有意でなくても高次の項がサポートされ、より堅実なモデルが提供されます。これは統計的に好ましい手法です。詳細については、警告ボックス内の Help ボタンをクリックしてください。次に、モデル統計が表示されます。
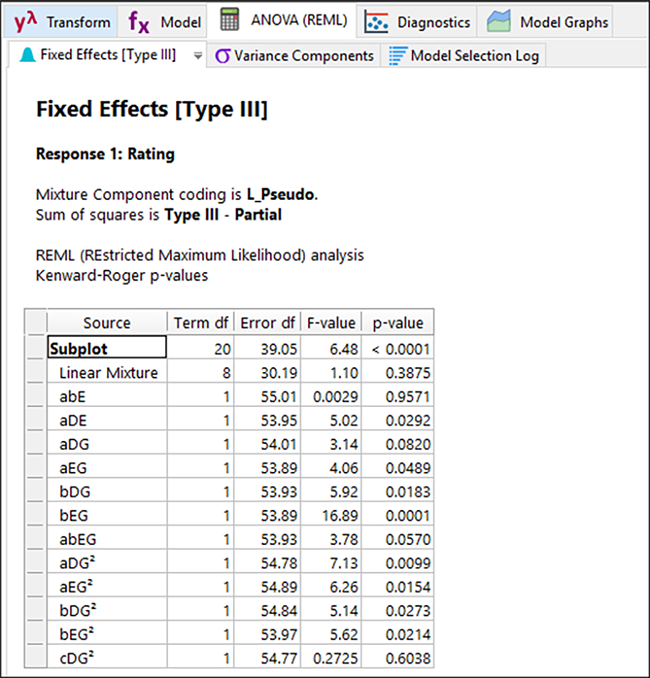 |
ANOVA 分析の結果は、妥当性を確保するため無作為化を行っているので、これと同じになるとは限りません。DX で行った分割法の解析手法は、最尤法です。結果のテーブルの上部に示されているように厳密に言えば、制限付き最尤法(REML)です。
| ※分割法の詳細:最尤法の目的は、観察データから得られる可能性が最も高いパラメータ値を見つけることです。制限付き最尤法は、Model 画面の Analysis メニューをクリックして変更しない限り、標準で使用される分散予測の手法の一つです。分割法における REML では、whole-plot における因子のグループの分散と、subplot における因子の残差の分散を予測します。分散が予測されると、一般化最小二乗法(GLS)を使用して因子効果が予測されます。それから、Kenward-Roger 法を使用して F 検定と対応する p 値が示されます。詳細については電球アイコンをクリックしスクリーンチップスのリンクを参照してください。 |
この表における統計量と通常の ANOVA の大きな違いは、HTC 因子はWhole-plot、ETC 因子は subplot で分散項がグループ化されることです。しかし、この計画では Whole-Plot 項は選択されていません。つまり単に有意な A、B、C からなる項は存在しません。A、B、C を含む項は存在しますが、これらは常にフロスティングの混合および、フロスティングの合計(G)項と交わるため、これらは subplot の一部です。これは、多少予想されていたことです。分割法では subplot の項 (およびそれらの交互作用) は、より検出力が高く、さらに簡単に検出することができるからです。実際にこれらの subplot の交互作用は、HTC 因子の検出力の不足を補えることがよくあります。
この subplot を全体としてみると、モデルには極めて有意な F 値があります(p 値<0.0001)。ほとんどの項も有意(アルファレベル 0.05)であるか、階層のために必要です。例えば、有意ではない項 ABE は、有意な ABEG 項のために必要です。
次に、“Variance Components” タブをクリックして、各種統計量が REML 解析を補足していることを確認してください。
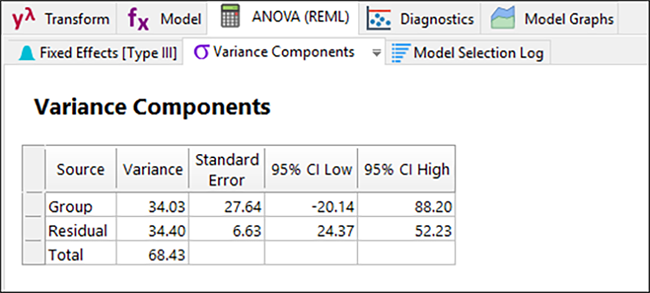 |
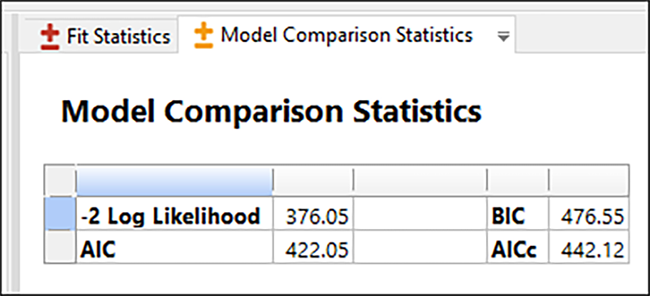
ここで、Variance Components の詳細が表示されます。“Model Comparison Statistics” タブに移動して、情報基準(AIC、BIC、AICc)を含む、選択したモデルの尤度比をさらに詳しく見ることができます。詳細についてはヘルプメニューを参照してください。。
 |
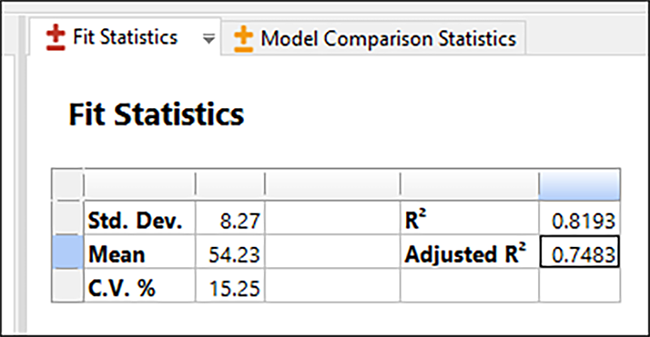
確認すべき重要な数字のひとつに、“Fit Statistics” タブにある Adjusted R2(自由度調整済み決定係数)があります。この数字は 0 から 1 までの間で推移し、1 が最も優れています。この例の場合、自由度調整済み決定係数は 0.75 です。決定係数では、選択したモデルがデータ内における変動の大部分(~75%)を捉えていることが表示されます。
 |
モデルの基準についてさらに詳しく調べたい場合は、文脈依存ヘルプを参照してください。目的の番号をクリックして強調表示したら、F1 キーを押してください(または、右クリックしてヘルプを選択します)。例えば、Adjusted R2 基準について得られた情報を見てください。
モデル統計量は、十分な値です。モデルは、かなり強力なようです。“Diagnostics” タブを押して、残差のグラフを確認します。
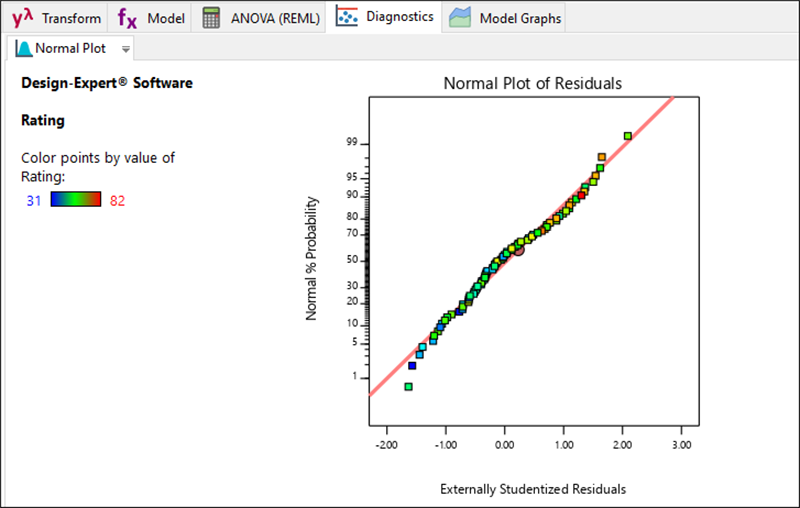 |
フローティングの Diagnostics ツールから見つけた残差のグラフは、重要で確認する必要があります。しかし、これらについては別のチュートリアルで詳しく説明しています。例えば『多因子における RSM』チュートリアルを参照してください。この場合、診断に問題はなさそうなので “Model Graphs” をクリックして混合(三角)空間における応答を表示します。
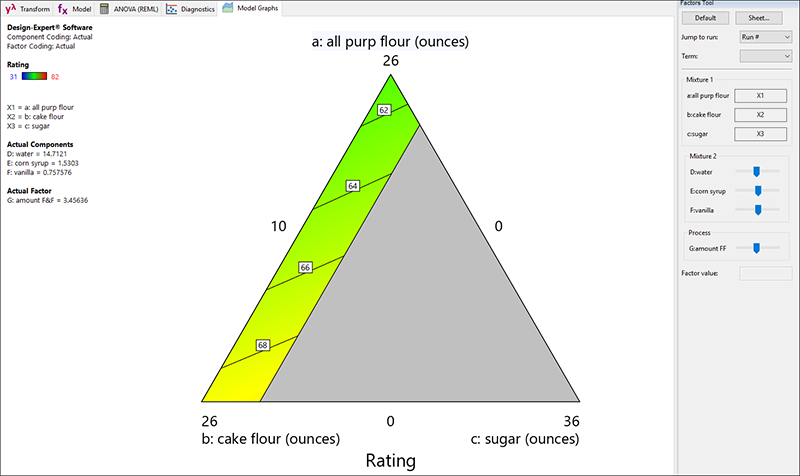 |
フローティングの Factors Tool に表示されるように、この混合物は Mixture 2(フロスティング)とプロセス因子(F&F の量)が相互作用することを忘れないでください。これらの因子のバーを、クリック&ドラッグすると応答グラフが変化します。例えば、Factors ツールの Process リストにある F&F を左(低い値)にドラッグしてください。フロスティングの量が減るにつれて、全体的に味が落ちるのは当然です。フロスティングがかかっていないケーキを欲しがる人がどこにいるでしょうか?
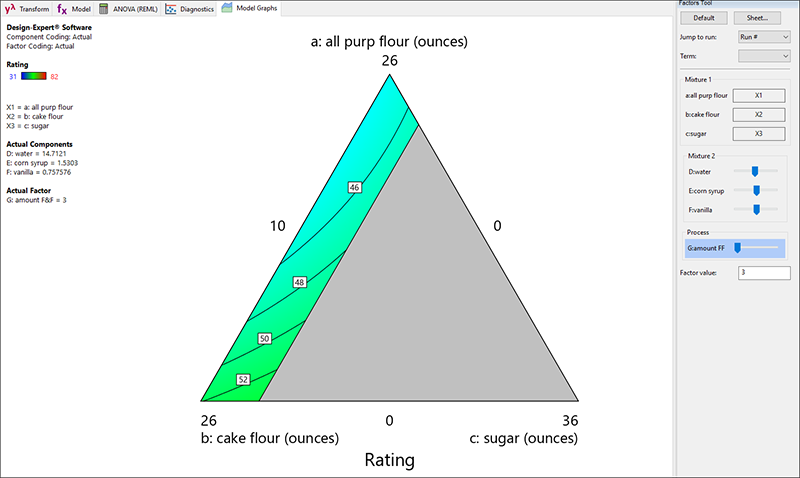 |
このプロセス因子が、そのままでどのように見えるか確認してみましょう。フローティングツールの amount F&F プロセス因子を、右クリックして “X1 axis” を選択します。グラフツールで “One Factor” が強調表示されたことに注目してください。そのボタンをクリックしても、このグラフを表示することができます。
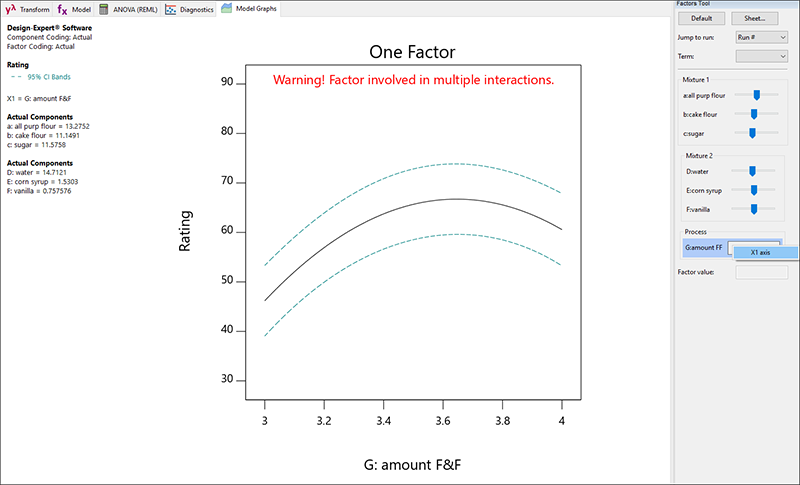 |
これにより amount F&F が X 軸に配置されます。前のグラフで見たように、amount F&F の値を上げると味が良くなりますが、これはある程度までです。量が最高水準になると、味の評価は下がります。グラフの上部に赤く示された警告で気づくかも知れませんが、これは手順全体の一部でしかありません。amount F&F は2つの混合物と相互に作用します。フロスティングの混合物がどのようにグラフに影響を与えるかを確認するために、Floating Factors ツールからMixture 2 の赤いバーをドラッグします。例えば、water の水準を高水準にドラッグし、F&F グラフがどのように対応するかを確認してみてください。。
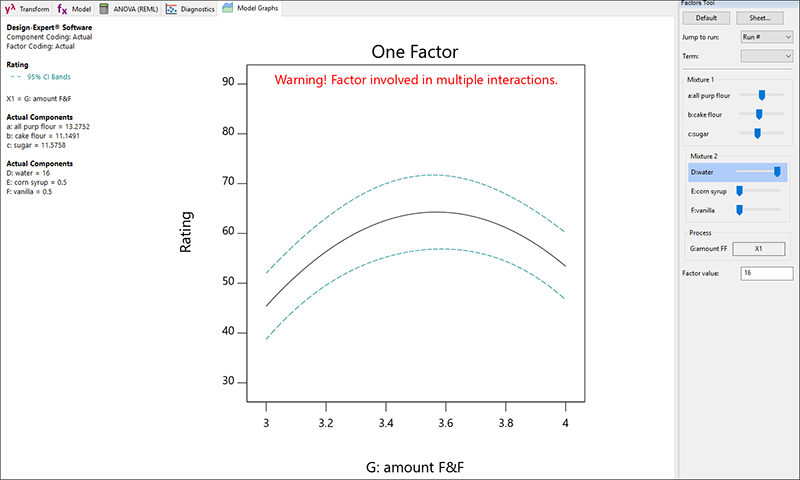 |
なお、water を加えるほど、corn syrup と vanilla を減らして、フロスティングの混合物の合計を一定に保つ必要があります。water をすべて追加しても全体的評価はさほど変化せず、amount F&F の最適条件には依然としてピーク(僅かにより鋭い)が存在しています。
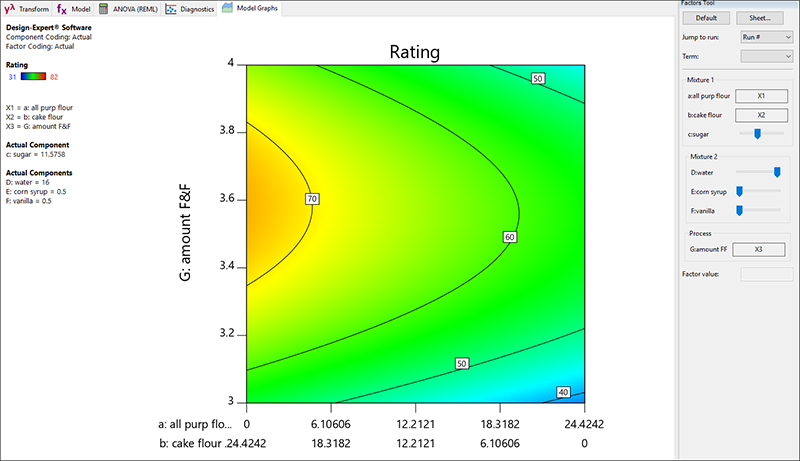
このように複合計画には、検討に値する興味深いグラフが数多く存在します。例えば、Graphs Toolbar にある “Mix-Process” ボタンをクリックしてみてください。この操作によって、薄力粉の代わりに中力粉を使用すると、amount F&F(下から上)と連動して評価にどのような影響があるのかを確認することができます。
 |
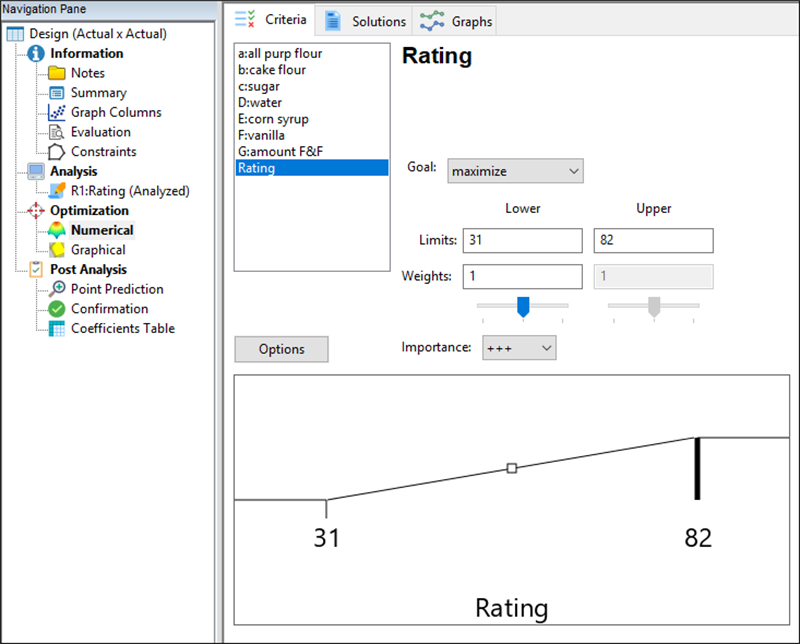
この実験プログラムの最終目標は、Lady Baltimore Cake のレシピをカスタマイズして、総合評価が最高となるような方法を知ることです。配合の最適な組み合わせを探し出すために、“Numerical” とラベル付けされた最適化ノードをクリックします。次に、 “Rating” を選択します。Goal ドロップダウンリストから “maximize” を選択し、その他の全てはデフォルトのままにします。画面は以下のようになります。
 |
“Solutions” タブをクリックします。デフォルト設定の Ramps 表示で解が表示されます。
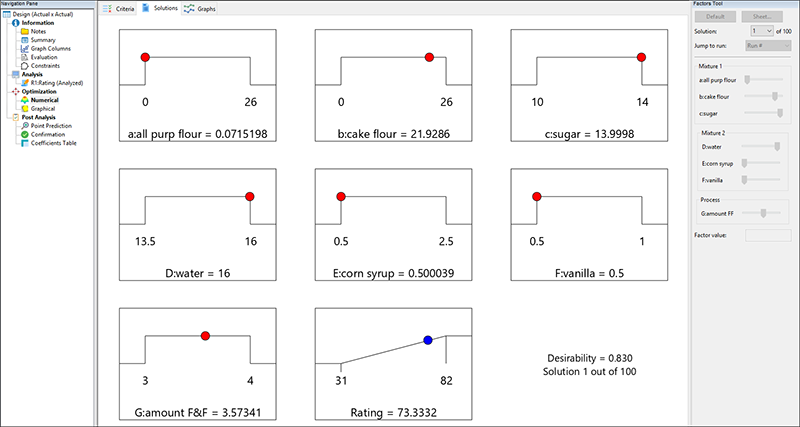 |
Ramps 表示を使用すると、各成分/因子の水準および評価結果(73)を簡単に確認することができます。残念ながら、中力粉は低水準に設定されます。レシピの制作者が薄力粉の使用を決めたとき、自らこのことを分かっていたと思われます。amount F&F(G)は、1因子のプロットで因子を検討した際に、以前に見たように上中央の水準に設定されます。
これが解の番号 1 であり、最高の評価を得ています。その他いくつかのオプションを検証するために、Factors Tool のドロップダウンメニューから別の solutions 番号をクリックしてみてください。
 |
Solutions ドロップダウンを一度クリックすると、上下の矢印キーを使用して簡単に他の解に切り替えることができます。さらに評価が低い解に移動しても、良い評価を得るには中力粉を低水準に設定する必要があるようです。
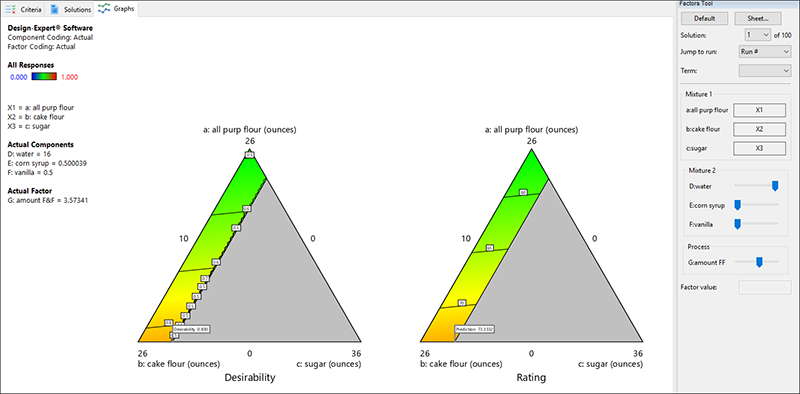
最適解におけるグラフを検証するには、“Graphs” タブをクリックします(Solutions バーの solution 番号は必ず 1 を選択してください)。最適解にはフラグが立てられています(中力粉が低水準の地点)。デフォルトではすべての応答が並んで表示され、そこには最適解の検索に使用された望ましさのプロットも含まれています。
 |
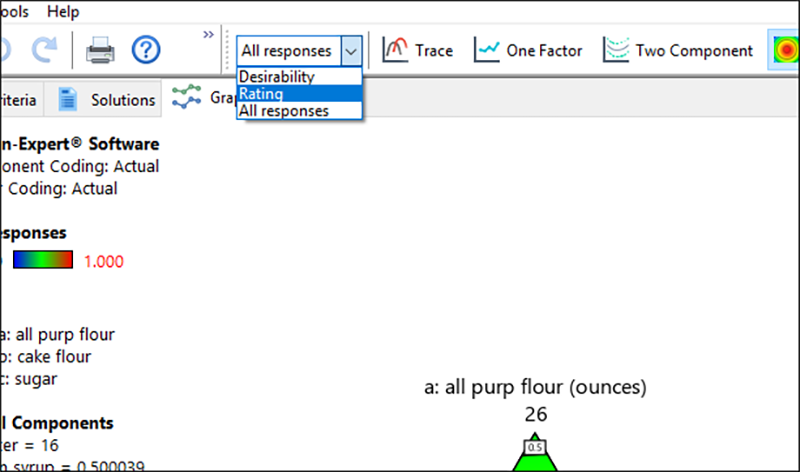
評価だけを表示するには、Response ドロップダウンリストから “Rating” を選択します。
 |
多くのグラフを探索しましたが、レシピはかなり最適化されているようです。もう少しグラフを検討したければ、ご自身でお任せします。