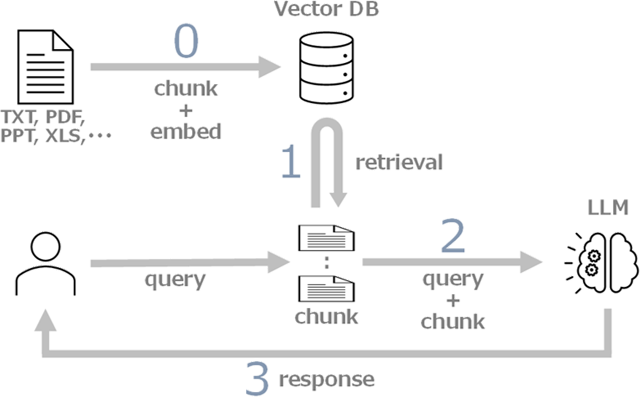
LLM には学習範囲外の内容に対応できないという問題がありますが、RAG (Retrieval Augmented Generation) 技術を使うことで、未知の情報に対応できるようになります。
RAG は次のように機能します:
Wolfram Language を使って日本国憲法を題材に RAG を実装する方法を説明します。
以前、日本国憲法を例にして Wolfram Language で RAG を実装する方法について日本語の投稿をしました。#記事はこちら
バージョン 14.1 で RAG をサポートする関数 (LLMPromptGenerator、SemanticSearch、VectorDatabaseSearch など) が追加されたので、それを使って修正します。
まず、日本国憲法の103条を分割してチャンクを準備します。
この準備は RAG のパフォーマンスを向上させる重要なステップです。これにより、RAG はより正確に検索を行えます。

5つのチャンクを確認します。

質問は以下の通りです:

回答に必要なチャンクは、第45条、第46条、第102条です。

バージョン 14.1 でサポートされている SemanticSearch を使用して、回答に必要なチャンクを取得できるかどうか試してみましょう。
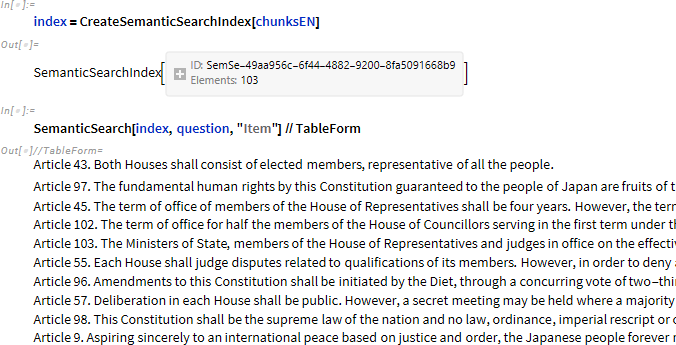
第45条と第102条はトップ10に入っていますが、第46条は入っていません。 (第46条は18番目です。)
そのため、トップ10のチャンクでは正しい回答を提示していません。回答は第46条について言及していません。

これは、CreateSemanticSearchIndex の FeatureExtractor オプションで使用される埋め込みメソッド「SentenceBERT」によるものです。
私は普段日本語の文書を使用するので、埋め込みには Hugging Face multilingual-e5-large と cohere embedded-multilingual-v3.0 を使用しています。
VectorDatabaseSearch もバージョン 14.1 でサポートされているため、cohere embedded-multilingual-v3.0 を使用してベクトルデータベースを作成します。

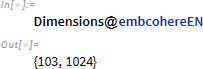
103個のチャンクを埋め込みます。

各チャンクを 1024 次元のベクトルに埋め込みます。
ベクトルデータベースを作成します。

質問を 1024 次元のベクトルに埋め込みます。

VectorDatabaseSearch の結果、第45条、第46条、第102条がトップ3に入っています。

LLMPromptGenerator に指定する関数を準備します。関数は、指定された質問に近い5つのチャンクをベクトルデータベースから取得します。

正しい回答を提供するようになります。

LLM の課題である、学習範囲外の内容に対応できないことや、情報過多による対応不足といったことを解決する Wolfram Language による RAG について説明しました。
RAG は、プライベートな情報に基づいて LLM が回答を生成することも可能にします。
しかしながら、CreateVectorDatabase や LLMSynthesize は外部サービスを使用するため、プライベートな情報を使用することができません。
この問題を解決するために、プライベート環境で構築できる LLM/embed モデルが日々リリースされています。ハードウェア環境や非ラテン語のサポートなど課題はあるものの、AI のワープスピードの進化により、LLM を個人のPCでもストレスなく実行できる日も近いでしょう。