LLM は学習外の内容に対応できない問題がありますが、RAG (Retrieval Augmented Generation) 技術の使用により、未知の情報にも対応可能になります。
RAG の仕組みは以下となります。
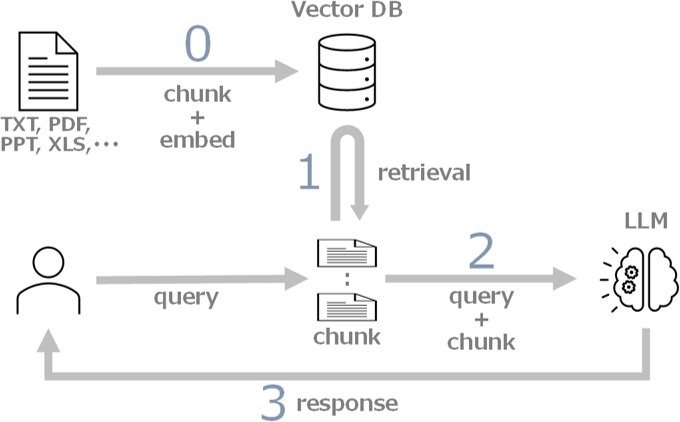
では、Mathematica で RAG を実装する方法を日本国憲法を題材として説明します。
なお、ここで使用している LLM は、gpt-4-32k です。
まず、RAG を使わない場合の問題点を検証します。
質問は、以下とします。
「日本国憲法で定められた両院議員の任期を教えてください。また、それは何条に書かれていますか?」
正解は、以下となります。

任期の情報は正確ですが、第54条ではなく第45条が正しいです。また、第102条については言及されていません。
日本国憲法の全文を用意します。

日本国憲法全文の文字数は約1.1万、トークン数は約1.3万
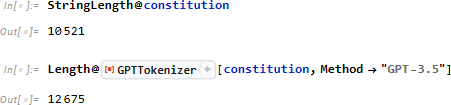
ここで使用する LLM の最大トークン数は 3.2万であるため、日本国憲法全文を与えて LLM に問い合わせてみます。

任期と条番号は正確になりましたが、第102条については言及されていません。これは、LLM に与える情報量が多すぎるためと思われます。
それでは、RAG を使って期待する回答が得られるか試してみましょう。
Web から日本国憲法に関する記載を XMLObject 形式でインポートします。

全103条に関連する部分だけを抽出します。
RAG では、意味のある塊としてのチャンク作成が回答の精度に大きく影響します。そのため、各条文を1文にまとめて1チャンクとし、それをベクトル DB に登録できるようにします。
![]()
chunks を確認しておきましょう。

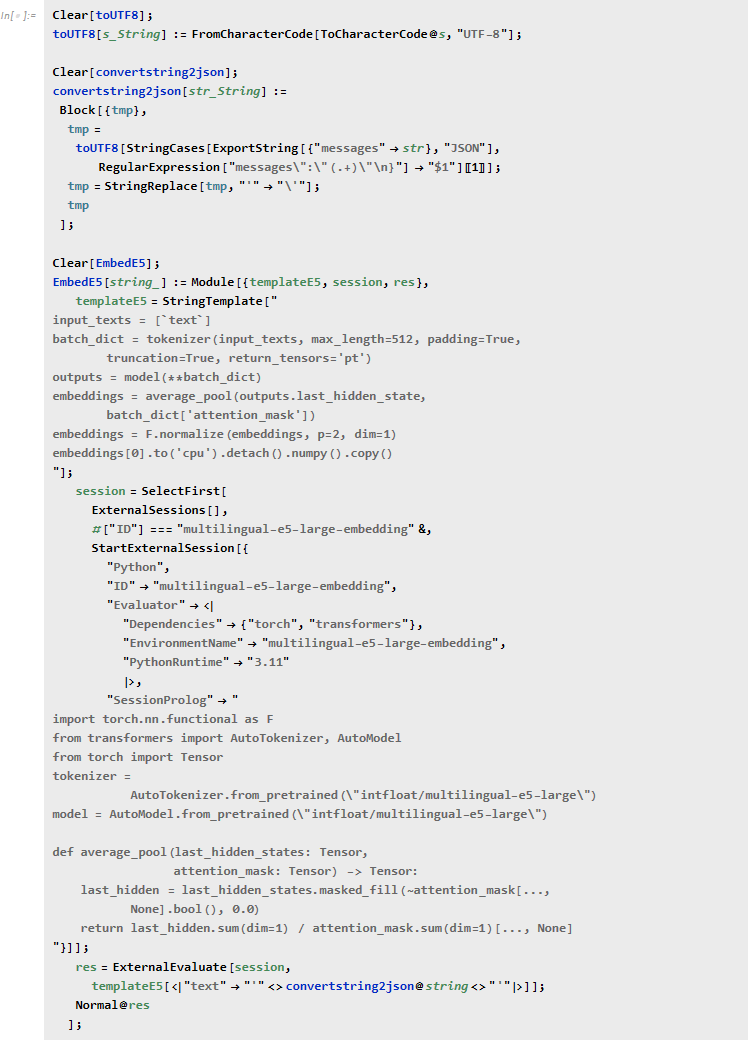
文章の埋め込みには、日本語に高性能な multilingual-e5-large を使用します (実行には少し時間がかかります)。
![]()
これにより、全103 のチャンク (条文) が 1024次元ベクトルに変換されました。
![]()
embs と chunks を用いてベクトル DB を作成します。
![]()
ベクトル DB の中身を確認しておきましょう。

質問をチャンクと同様に 1024次元ベクトルに変換します。
![]()
質問内容に近い (質問とのベクトル余弦距離が小さい) チャンクを5つ選びます (選択数は任意です)。

質問の回答に必要な第45, 46, 102条が TOP3 に選ばれました!
質問に、選ばれた5つの情報 (チャンク) を付け加えて拡張します。

拡張したプロンプトのトークン数は 436 で、日本国憲法全文を使用する場合の約1/30 になりました。
![]()
この拡張したプロンプトを使って LLM に問い合わせてみます。

期待どおりの回答が得られました!
以上の内容をまとめて関数化します。
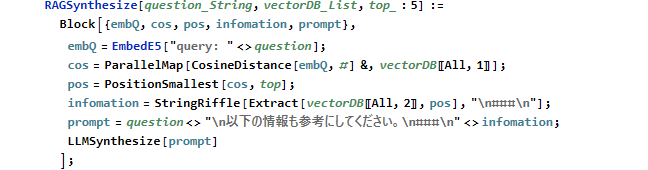
上述の質問と回答は、以下となります。

これまでの3パターンの問い合わせ結果を再掲しておきます。

LLM の問題点である、学習外の内容に対応できない、また情報過多で回答が不十分になる点を解決する RAG について説明しました。
また、RAG を使うと、非公開情報を基に LLM が回答を生成することが可能になります。
ただし、ここで説明したベクトル DB の作成はプライベートな環境で行いましたが、LLMSynthesize は OpenAI などの外部サービスを利用しているため、非公開情報を使用することはできません。
この問題を解決するために、プライベートな環境で構築できる LLM モデルが日々公開されています。ハードウェア環境や日本語対応などの課題はありますが、AI のワープスピードの進化により、個人の PC でストレスなく LLM を動かせる日も近いと思います。
multilingual-e5-large-embedding の実装については、ここを参照してください。
編集者注:執筆者募集からお問い合わせいただき、寄稿いただきました。ご協力いただきありがとうございました。