|
| サイトマップ | |
||
|
| サイトマップ | |
||
創薬予測モデルを最大限に活用するには?Author: Daniel Barr, PhD |
分子探索において予測モデルをどのように利用すべきか?
この記事では、予測精度が時として誤解を招く可能性があること、そして実験デザインの指針として予測モデルをどのように活用するのが最善であるかを Daniel が紹介します。彼は、不確実性と信頼性の指標を予測モデルに組み込むことの重要性を強調し、プロジェクトに適した化合物や実験の優先順位付けに役立つことを示します。
創薬における予測モデルの価値とは?私が以前教えていた学部生のほとんどは、ほぼ間違いなく「正しい答えを得るため」などと答えるでしょう。また、そのような当たり前の質問に対して、おそらく目を丸くして焦るでしょう。この答えの根底には、明確にする価値のある重要な前提があります:私たちは、実験に取って代わることができるような、正しい答えを得る予測モデルを求めているのです。創薬においては、関連する重要なデータはモデル化されるのではなく、実験的に収集される必要があります( ただし毒性学では、動物実験を最小限にするためにモデル化を利用できるようにする興味深い研究があります)。
Optibrium社では、可能な限り正確なモデルを作るために最善を尽くしていますが、このブログでは、予測モデルの目的に対する答えはもっと微妙なものであると主張したいと思います。単純化された答えに欠けているのは、信頼性、誤差、または不確実性という考え方であり、プロジェクトを成功に導くためにこれらの情報を活用することがいかに重要であるかということです。優れたモデルは、実験的測定に取って代わろうとするのではなく、実験的設計の指針となり、チームが最も重要で意味のある測定に優先順位をつけるを助けるべきです。
警告:予測モデルを構築する方法はたくさんあり、そうする理由もたくさんあります。それぞれのモデルには長所と短所があります。QSARモデル、kNNモデル、DNNモデル、LLMモデルの構築方法、時期、理由については、良いリソースがたくさんあります。このブログの目的は、モデルから最大の価値を得るために、予測の不確実性に関する情報をどのように組み込むかを示すことです。
まず、CEO である Matt によるマルチパラメータ最適化に関するレビュー論文から例を考えてみましょう。
・予測モデル D は、特性 Y の値を 6 と予測し、不確実性は 1 です。
・予測モデル E は、特性 Y の値を 6.5 と予測し、不確実性は 2.5 です。
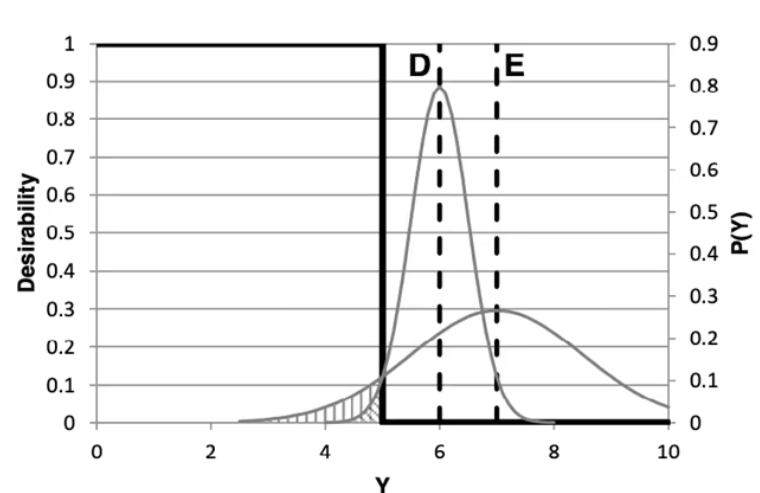
真の測定値が4.5であったとします。これは、プロジェクト成功のしきい値(私たちは、特性 Y の測定値が 5 以下となる化合物を特定するためにモデルを使用したいと考えています)である Y <= 5 を下回っています。どのモデルが最も正確だったでしょうか?
ほとんどの生徒が、モデル D が最も正確だったと答えます。予測値が測定値に最も近いからです。しかし、5 以下の化合物を識別するためにモデルを使う場合、モデルの結果は次のようになります※。
・予測モデル D は、pKi が 5 より大きいことを 84% 確信しています。
・予測モデル E は、pKi が 5 より大きいことを 72% 確信しています。
言い換えると、モデル E はこの化合物の測定値が成功基準を満たす確率は 27% 以上であると予測しています。そのため、モデル E は最も正確な情報を与えてくれています。なぜなら、もう一方のモデルは、私のプロジェクトの成功検討対象からこの化合物を除外しているからです。
一般的に、ほとんどのQSARモデルは不確かさの推定値を提供します。これは、検証セットとテストセットでのパフォーマンスに基づいています。予測モデルによっては、適用可能な範囲に基づいて、異なる不確実性を提供するものもあります(この話題は別のブログで紹介します)。モデルの予測精度を評価する際に、これらの不確実性を含めることは比較的簡単です(必ずしも簡単ではありませんが)。この不確実性の明示的な組み込みが、Optibrium社のStarDropの核心であり、推定値と不確実性が組み合わされ、特定のプロジェクト目標に対する化合物の成功の可能性を評価するために使用されます。
オンデマンド・ウェビナーでは、化合物の優先順位付けに対するOptibrium社のアプローチについて詳しくご紹介しています(Finding balance in drug discovery through multi-parameter optimisation)。
※これを計算するには、予測値を平均、不確実性を標準偏差とする(ガウス)分布を描きます。閾値の累積距離関数を計算します。ここでは、それは5の値です。これは、この化合物の測定値が 5 以下になるとモデルが予測する信頼度を示します。
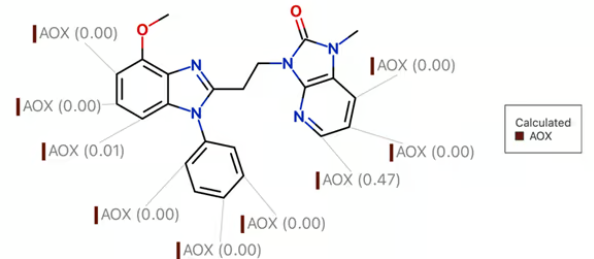
別の例を見てみましょう。ここでは、モデルの信頼性に関する情報をどのように組み込むかはあまり明らかではありません。Optibrium社は、様々な酵素ファミリーによる化合物の代謝の可能性を予測するモデルを提供しています。また、私たちのモデルは化合物上の代謝される可能性が最も高い部位を特定します。
以下に示すのは、PDE10A阻害剤の代謝予測結果です(Chino et al., J. Bioorg. Med. Chem., 2014)。この場合、WhichEnzyme™モデルは、この化合物がアルデヒドオキシダーゼ(AOX)によって代謝される可能性が、P450によって代謝される可能性とほぼ同じであると予測していることが分かります。しかし、可能性のある AOX 部位の反応性を考慮すると、位置選択性モデルはこの化合物に AOX 可溶性部位はないと結論しています。(注:分かりやすくするために、この図では AOX モデルによる位置選択性の予測値のみを示しています。) ある AOX 部位が AOX によって代謝される確率が 47% であることは、特に興味深いです。この場合、モデルは必ずしも AOX による代謝を否定しないと言えます。

そこで、このブログで取り上げることを目指した質問の核心を最後に述べましょう。特定の予測を行わない予測モデルの価値とは何でしょう?「正解」か「不正解」かを簡単に特定できないレベルの不確実性を持つ予測モデルには、どのような価値があるのでしょうか?
より多くの実験が必要な分野を強調することにはかなりの価値があります。予測にまつわる不確実性を狭めるために 1~2 回の実験を追加するコストは、機会損失や後期段階の失敗のコストに比べればごくわずかです。
Optibrium社では、可能な限り正確な予測を提供することを目指しています。それは常に可能であるとは限らないため、我々はまた、予測における不確実性に関する透明な情報を提供することを目指しています。私たちは、お客様がこれらの予測と不確実性を、お客様の化合物がプロジェクト目標に成功する可能性の明確な評価に組み込むお手伝いをしたいと考えています。
プロジェクト目標達成のために信頼性を活用した例をもっとお知りになりたいですか?Open Source Malaria (OSM) とのケーススタディにアクセスできます。この例では、Optibrium社は、新規活性化合物を正しく提案した唯一のチームでした。最も活性があると予測される化合物を選ぶのではなく、活性があると最も確信を持って予測される化合物を提出することを選びました。

Daniel は Optibrium 社のシニアアプリケーションサポートサイエンティストで、計算化学と統計学の専門知識を生かし、医薬品化学の進歩をサポートしています。データを効果的に活用し、測定の不確実性を考慮することに情熱を傾け、Daniel は創薬におけるイノベーションを推進するための有意義な洞察を育んでいます。
アリゾナ州立大学で化学の博士号を、バレット・オナーズ・カレッジで生化学の理学士号を取得しています。
(原文)https://optibrium.com/knowledge-base/blog-which-admet-properties-are-important-for-me-to-predict/