|
サイトマップ
|
8. Fit Summary タブ
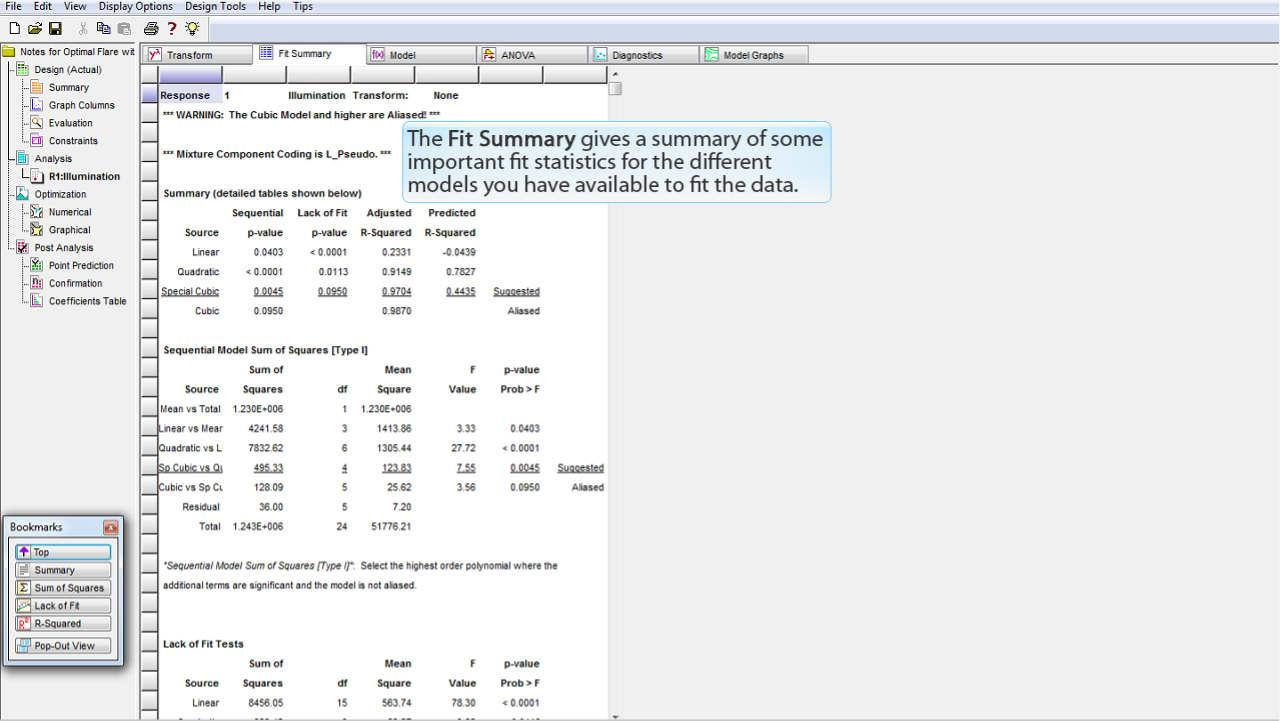
Fit Summary
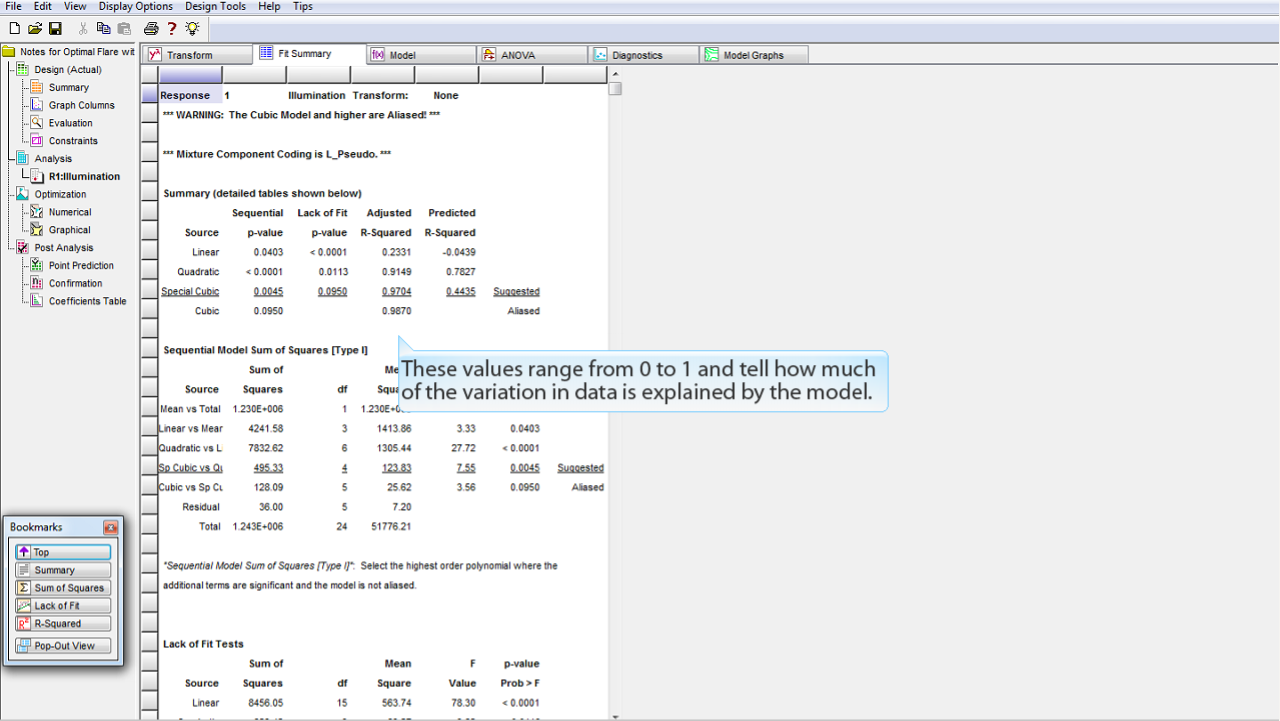
には、データの当てはめにふさわしい幾つかのモデルに関して重要な当てはめ統計量のサマリの一部が表示されます。
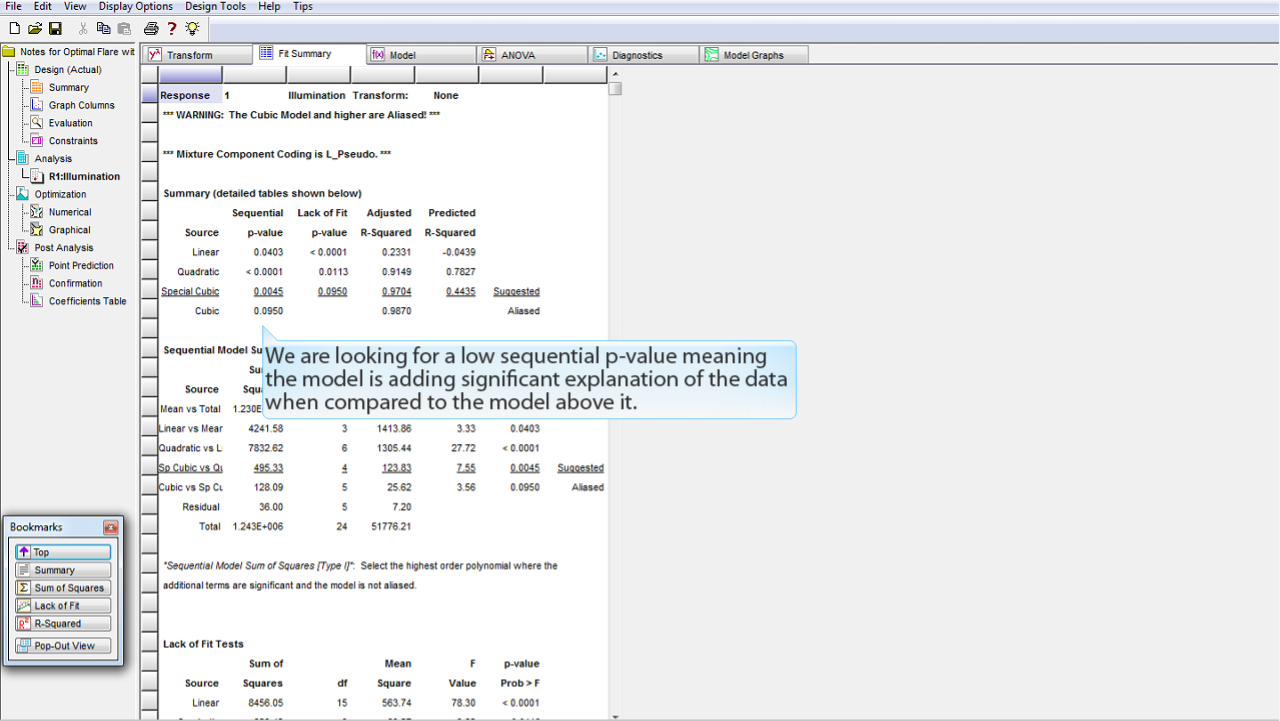
モデルによるデータの説明が上記モデルと比較して有意であることを意味する Sequential の p-value が低いものを探します。
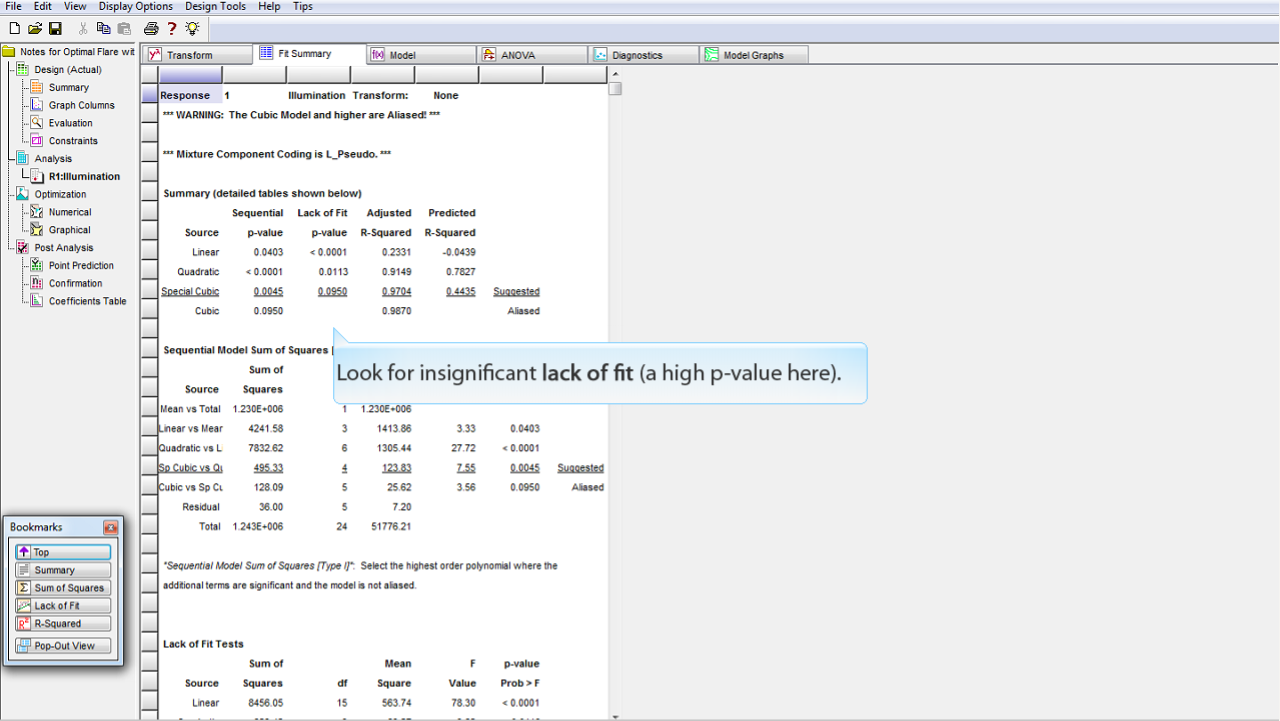
不適合度 (lack of fit) が低いもの (p 値が高いもの) を探します。
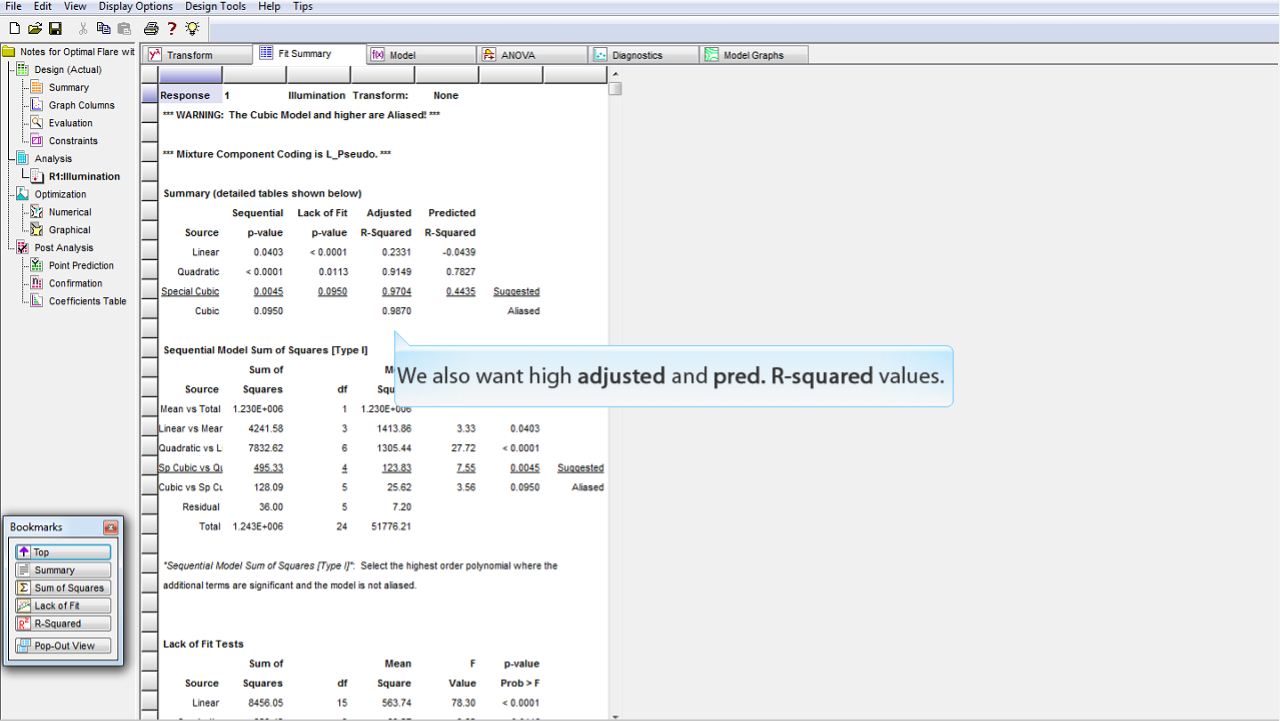
Adjusted
および
Predicted
の
R-squared
の値が高いものも調べます。
これらの値は 0 から 1 の間の範囲をとり、データの変化が各モデルによって説明される度合いをあらわします。
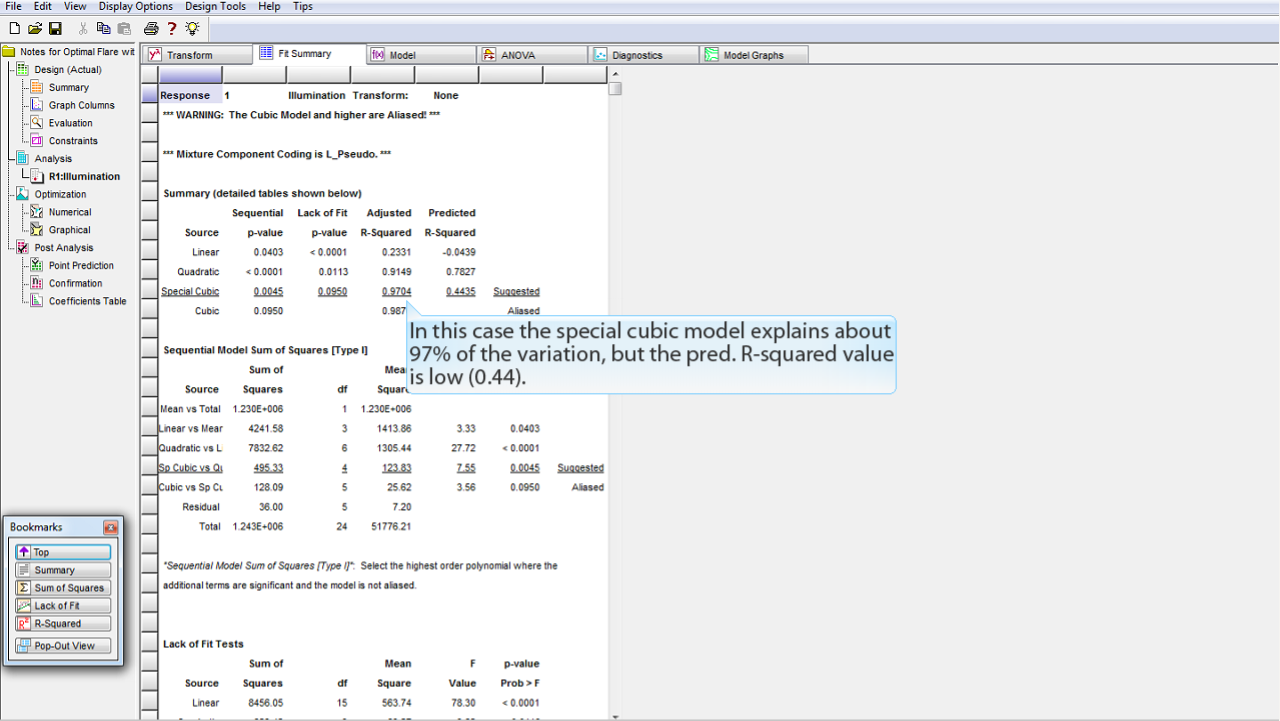
この事例では、特殊3次モデルによって説明されるデータの変動は約97%となっていますが、Pred. R-squared の値 (0.44) は低くなっています。
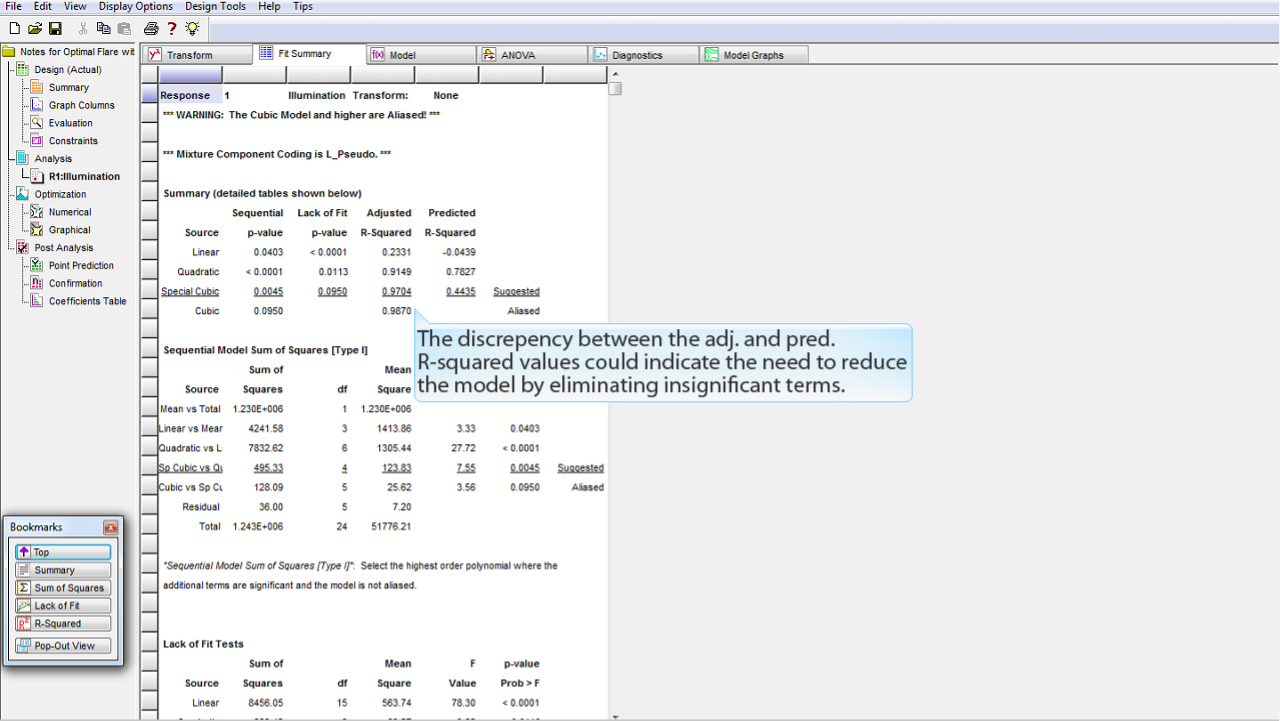
adj. と pred. における R-squared 値の不一致は、モデルから重要でない項を除外することによって消去 (reduce) する必要があることを示しています。
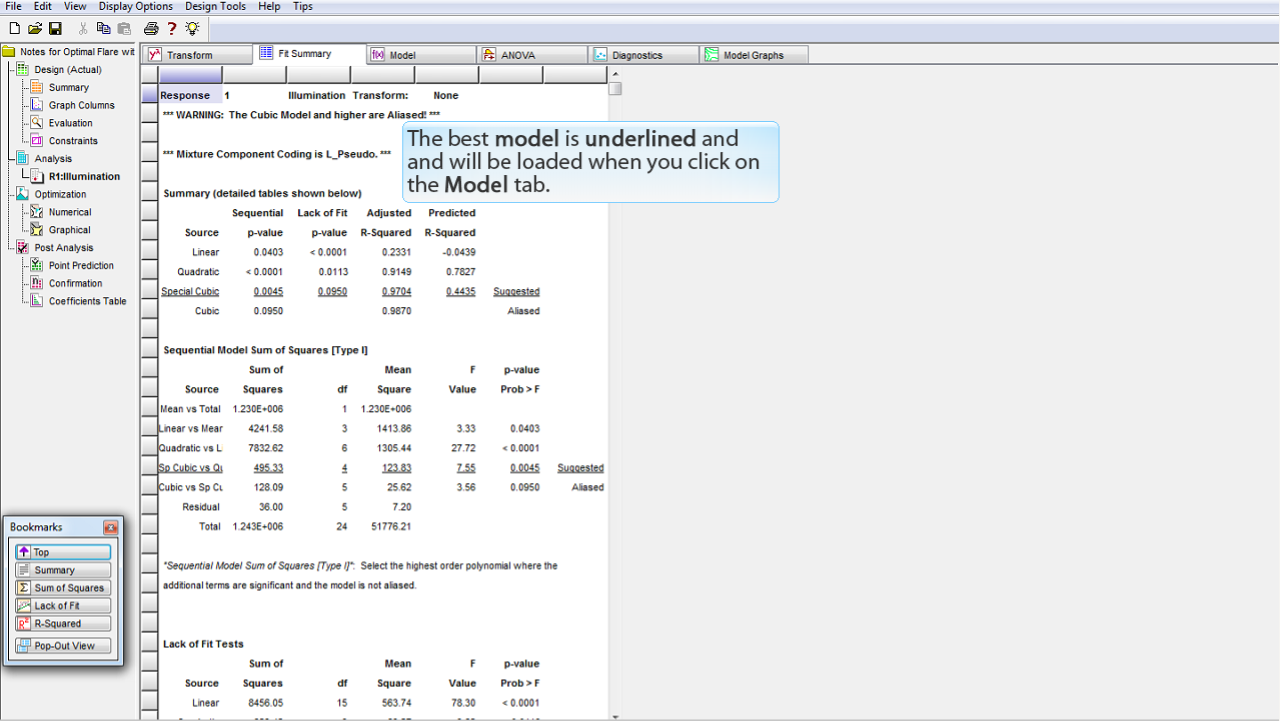
アンダーラインが引かれているのが最適なモデルです。
Model
タブをクリックするとこのモデルが読み込まれることになります。