|
サイトマップ
|
2. 2水準要因のデータの分析
ムービー:
Analyzing the data in a 2-level factorial
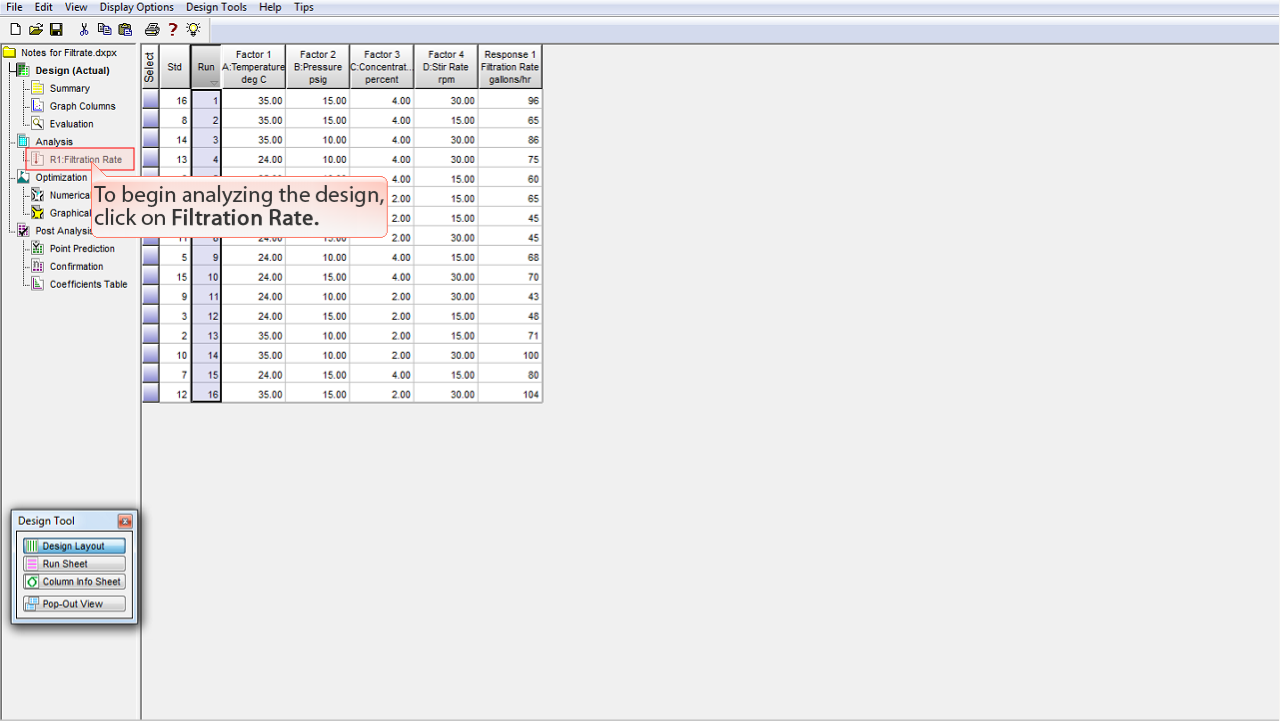
この計画の分析を開始するには、
Filtration Rate
をクリックします。
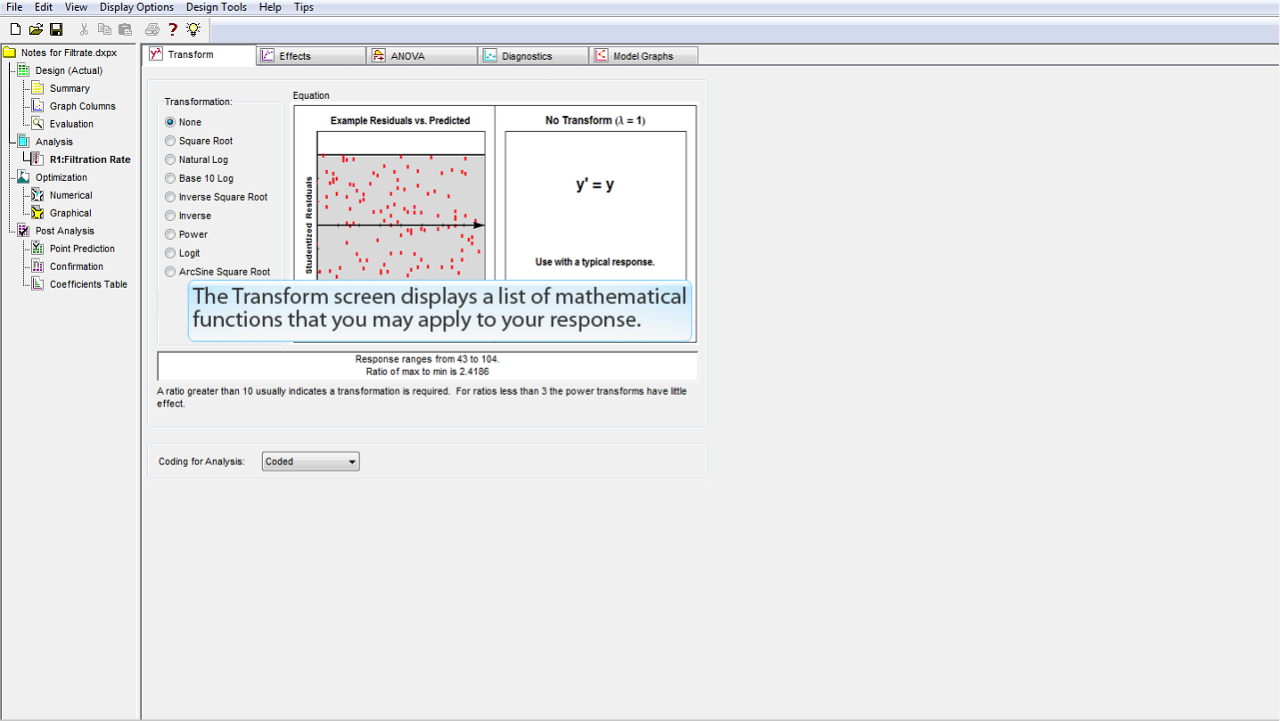
実験で得られた応答に対して適用できる数学的関数のリストが
Transform
画面に表示されています。
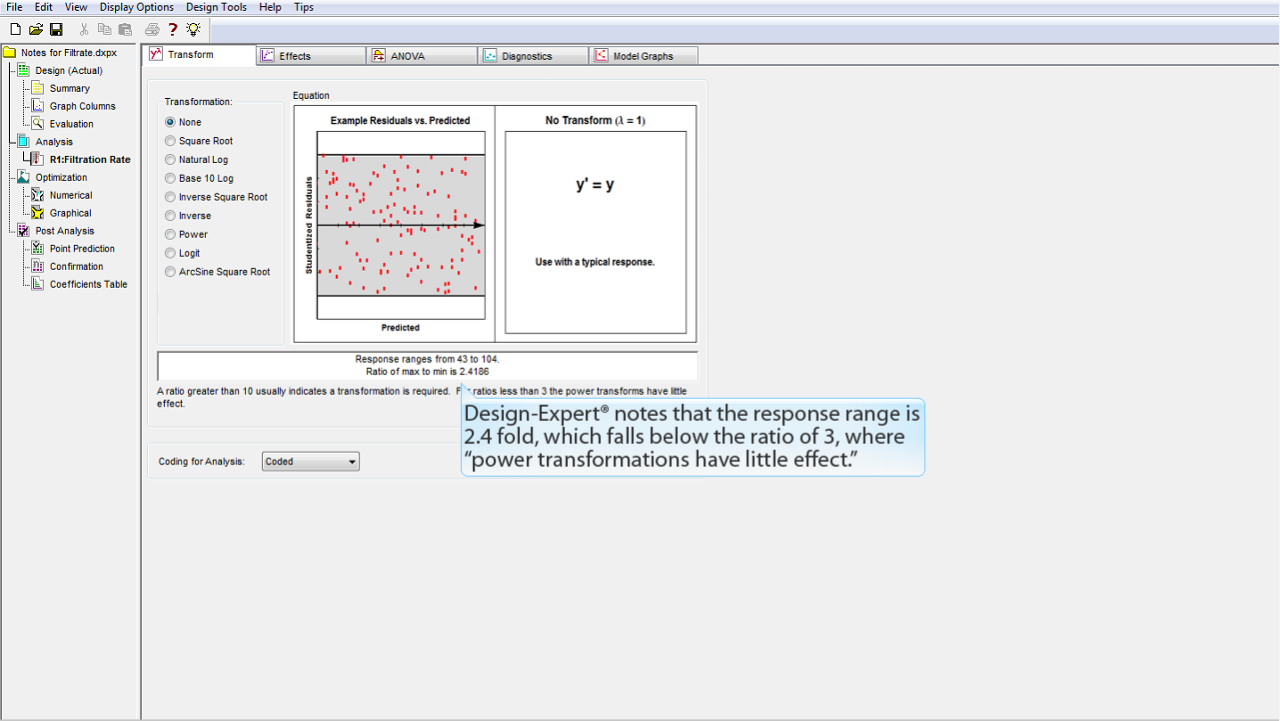
Design-Expert によって、この応答の範囲は 2.4 倍であるとのコメントが表示されています。これは、3 倍の比率を下回っているので、このべき変換による効果はほとんど期待できません。
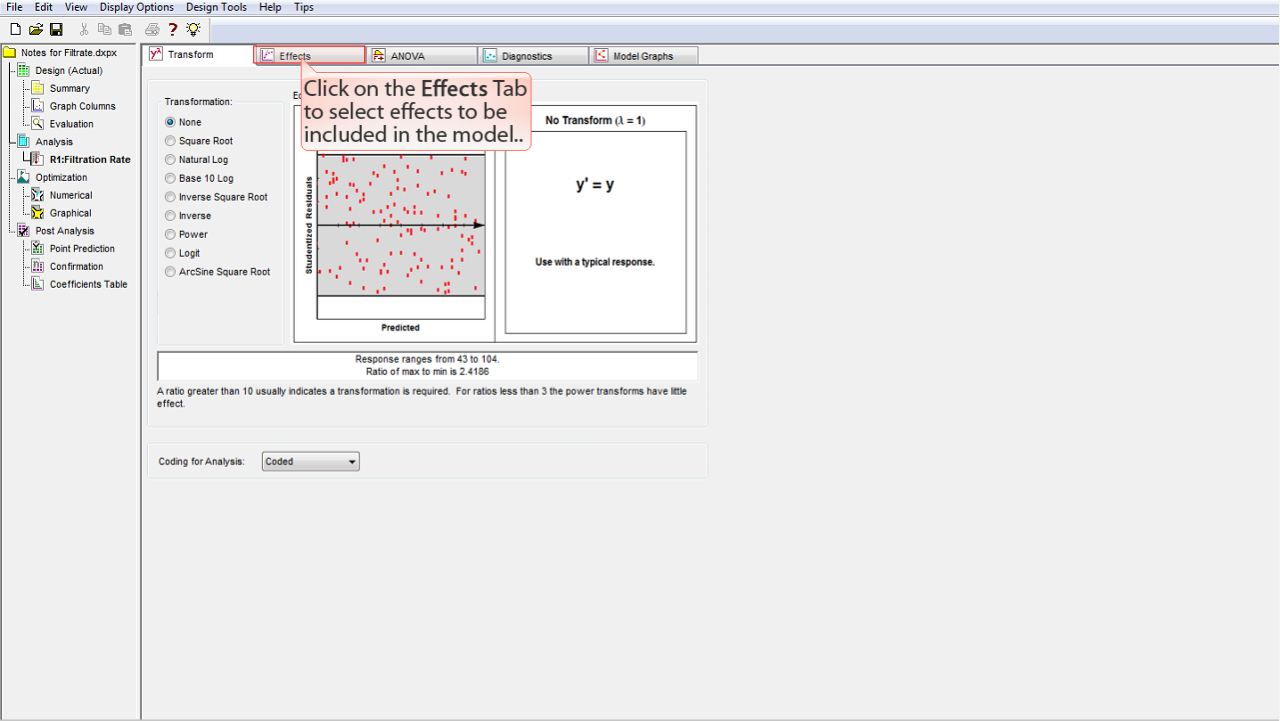
Effects
タブをクリックして、このモデルに含める効果 (effect) を選択します。
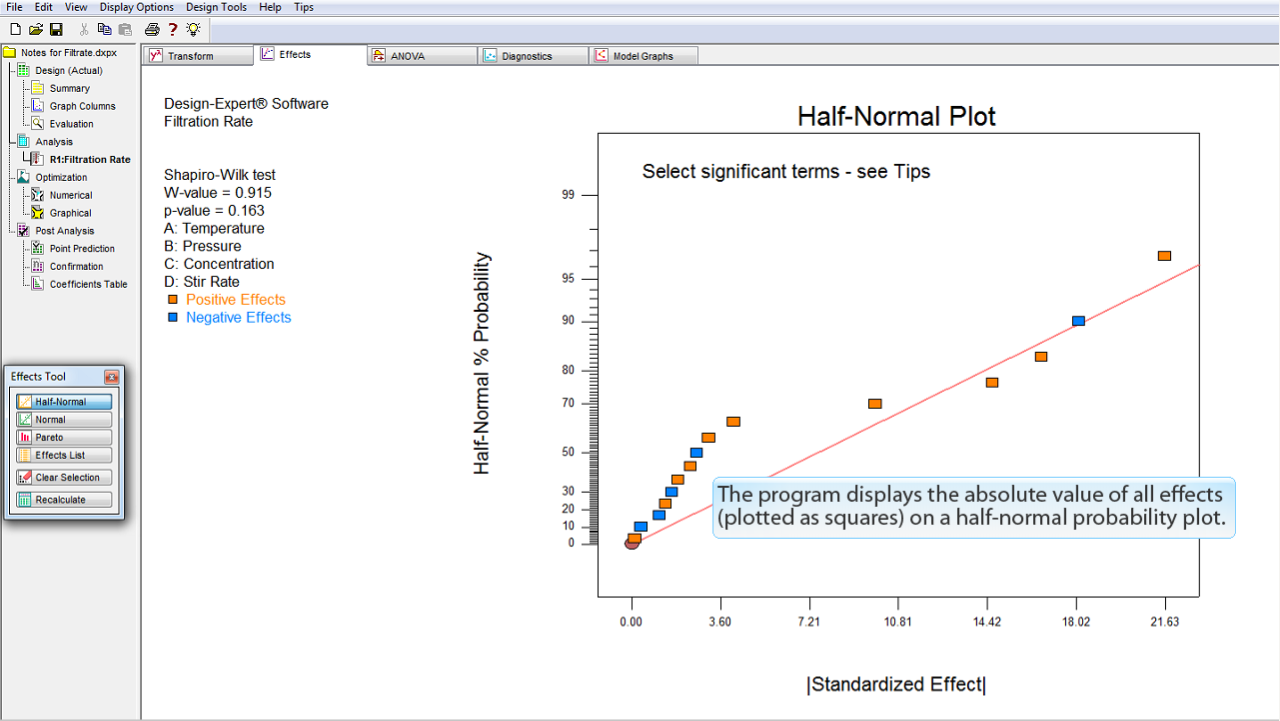
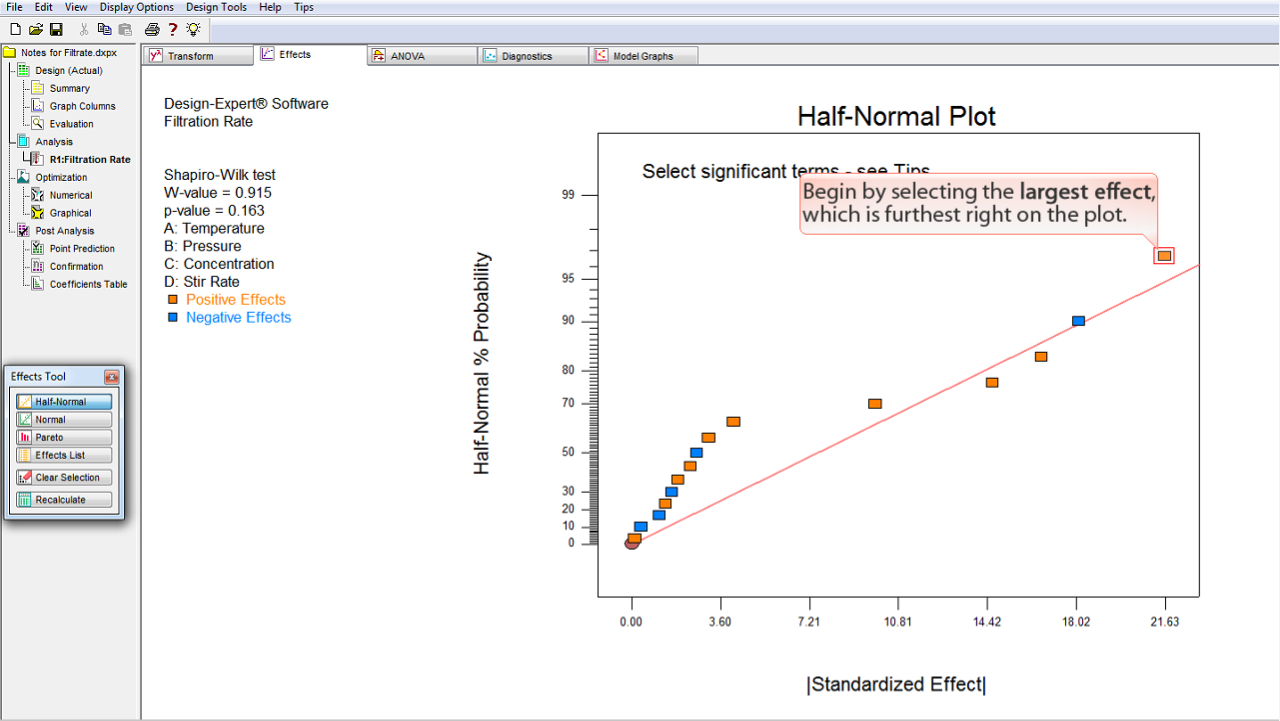
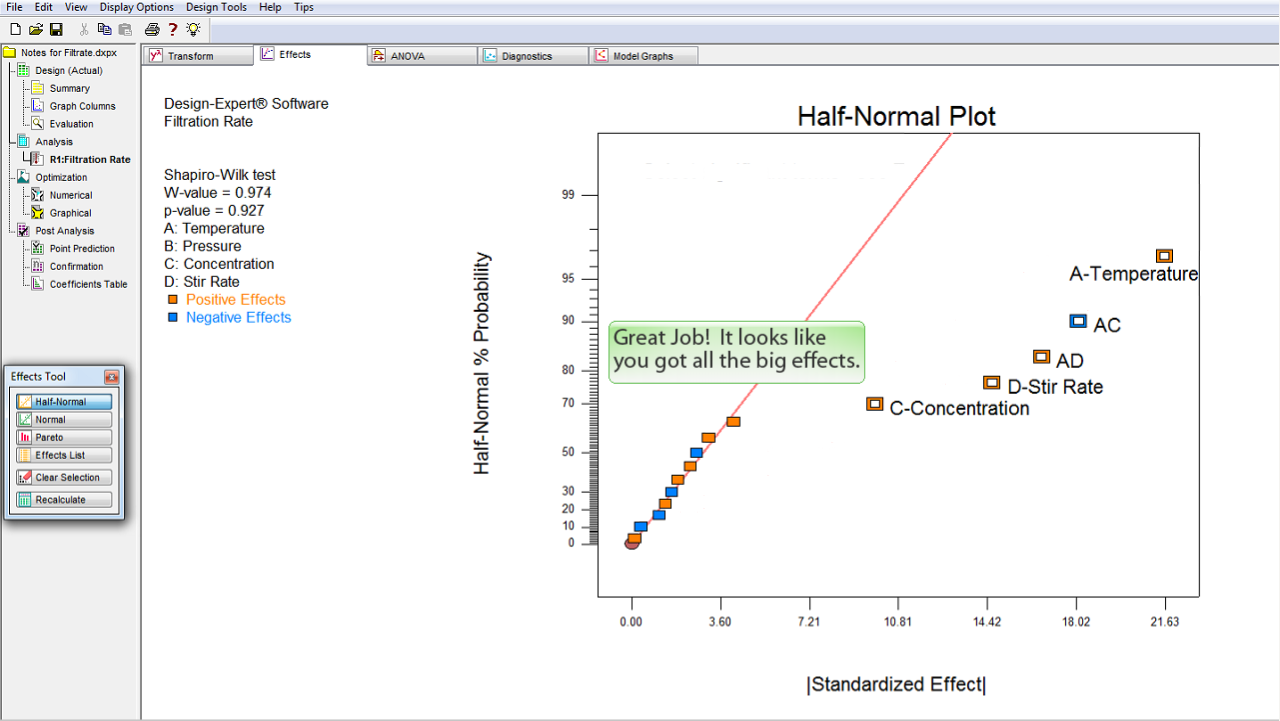
全ての効果の絶対値が半正規確率プロット (Half-Normal probability plot) 上に表示されます (正方形の点)。
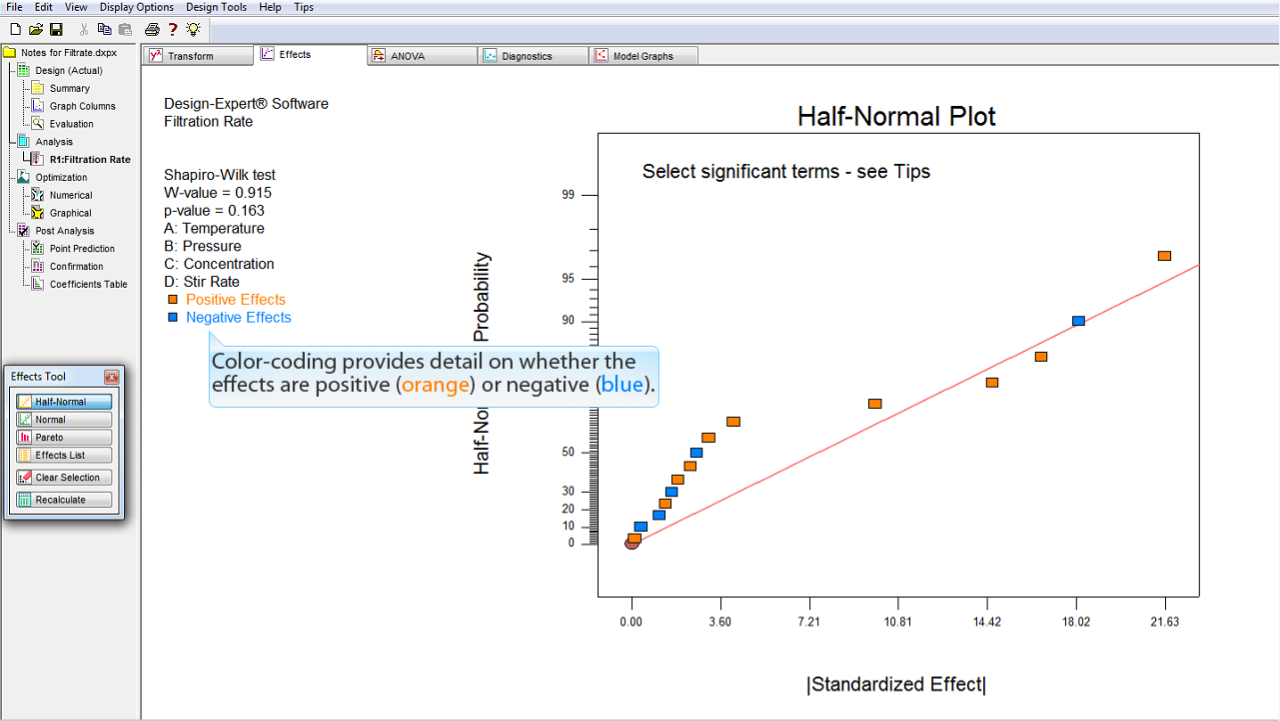
プロットされている効果の確率が正 (
オレンジ
) であるか負 (
ブルー
) であるかは色によって区別することができます。
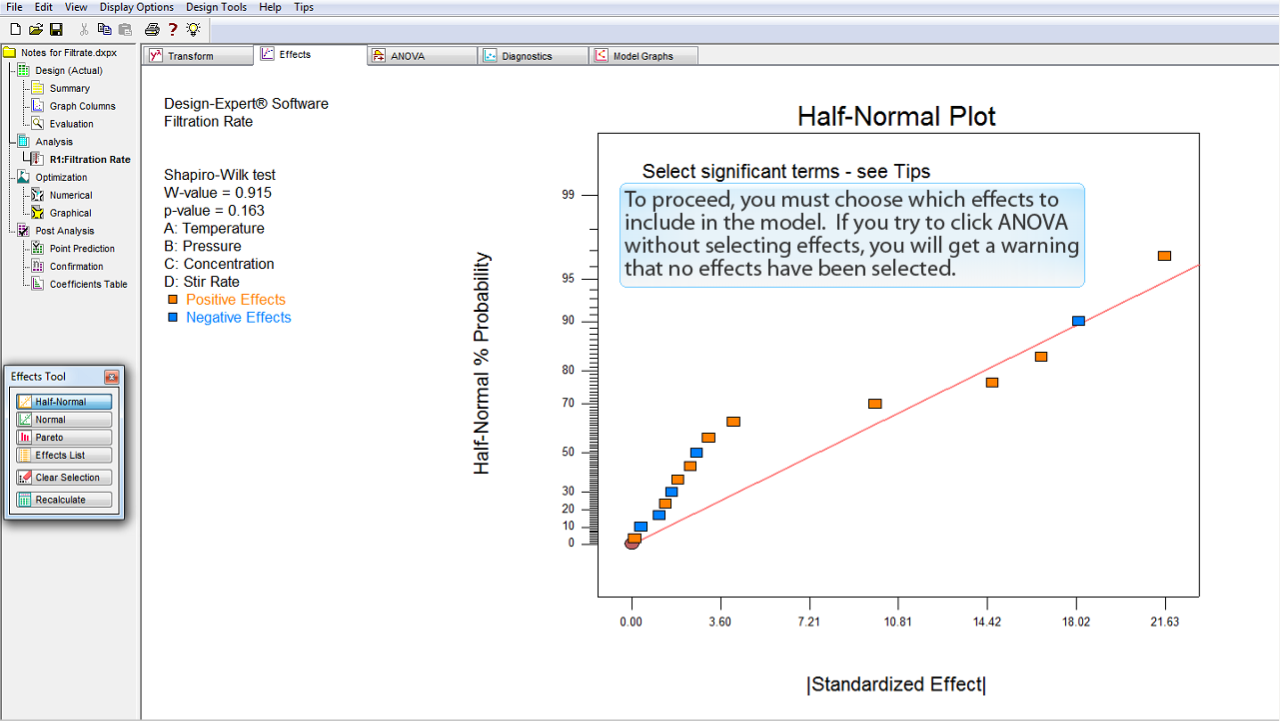
次に進むには、モデルに含める効果をこの中から選択する必要があります。効果を何も選択せずに ANOVA をクリックすると、効果が何も選択されていないと警告文が表示されます。
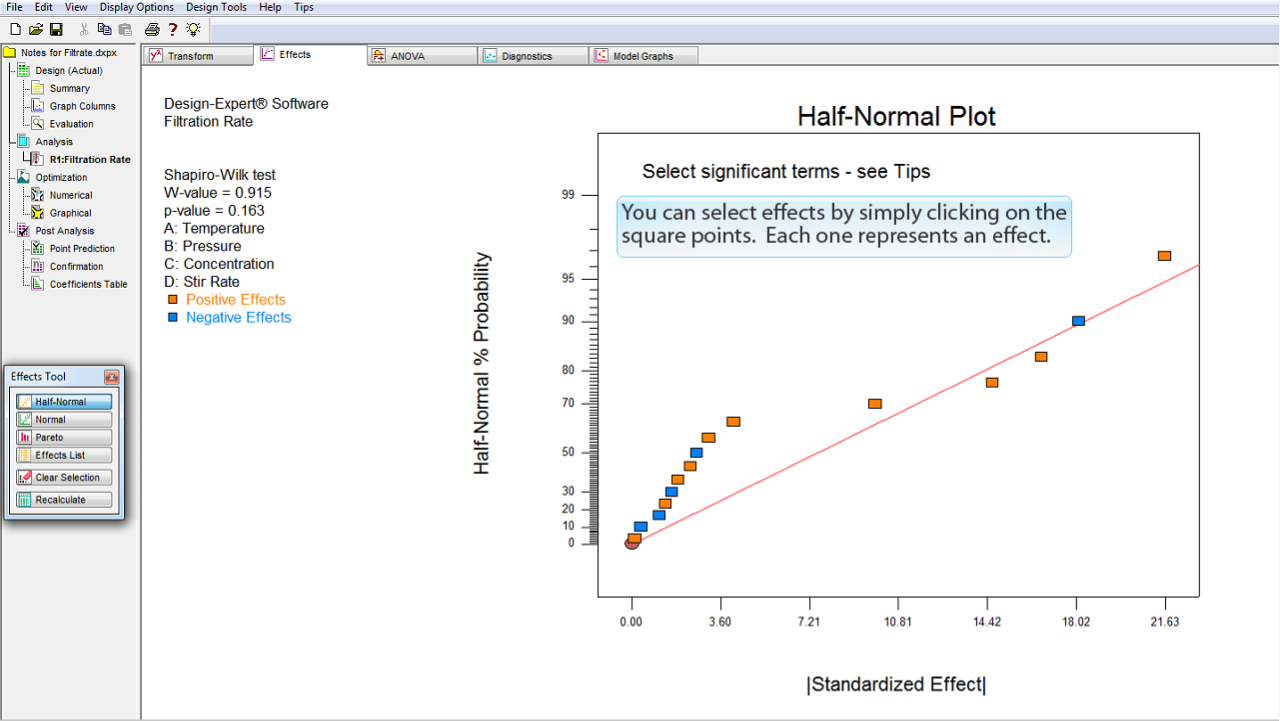
効果を選択するには、正方形の点のいずれかをクリックするだけです。点のそれぞれが各効果をあらわしています。
まずはじめに、プロットの右端にある最大の効果を選択します。
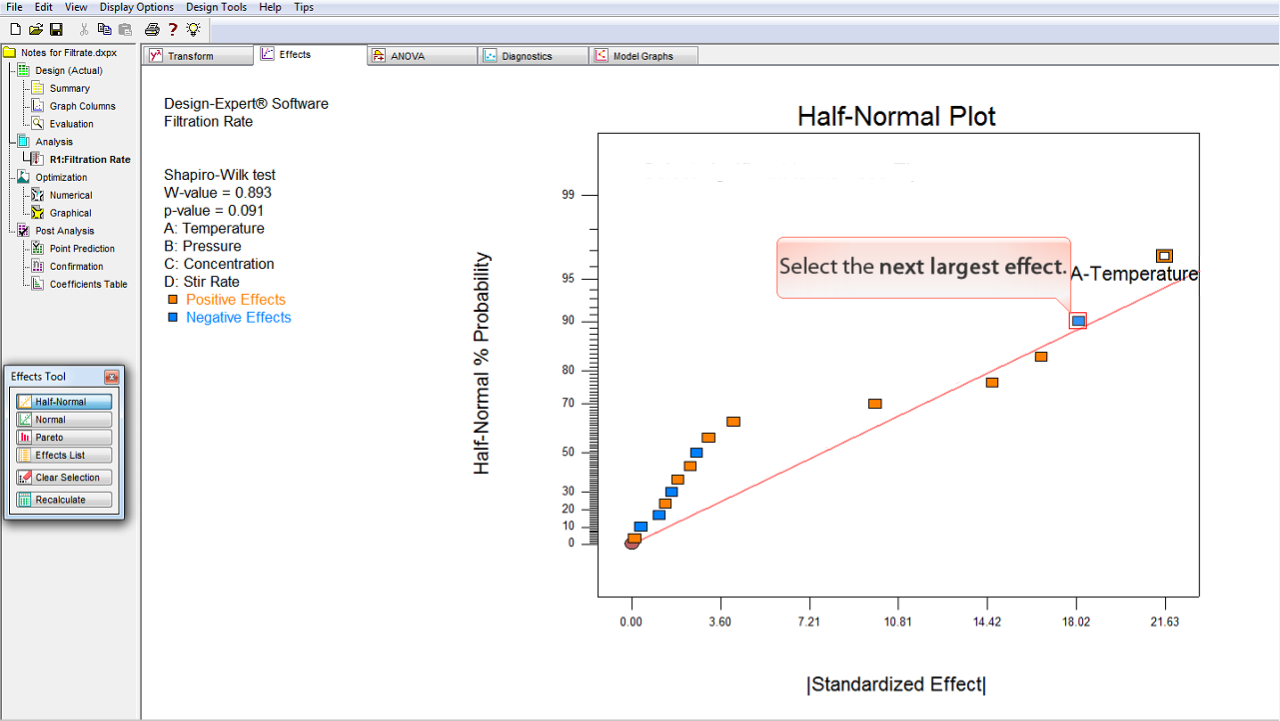
2番目に大きな効果を選択します。
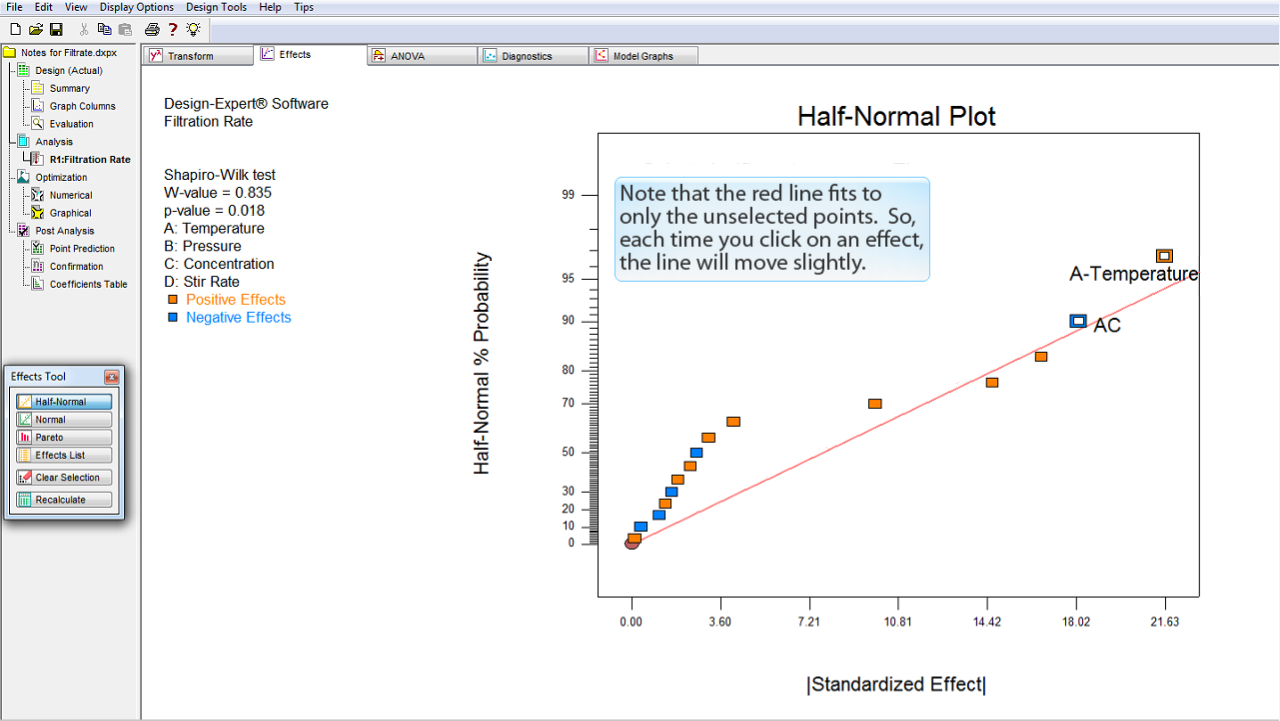
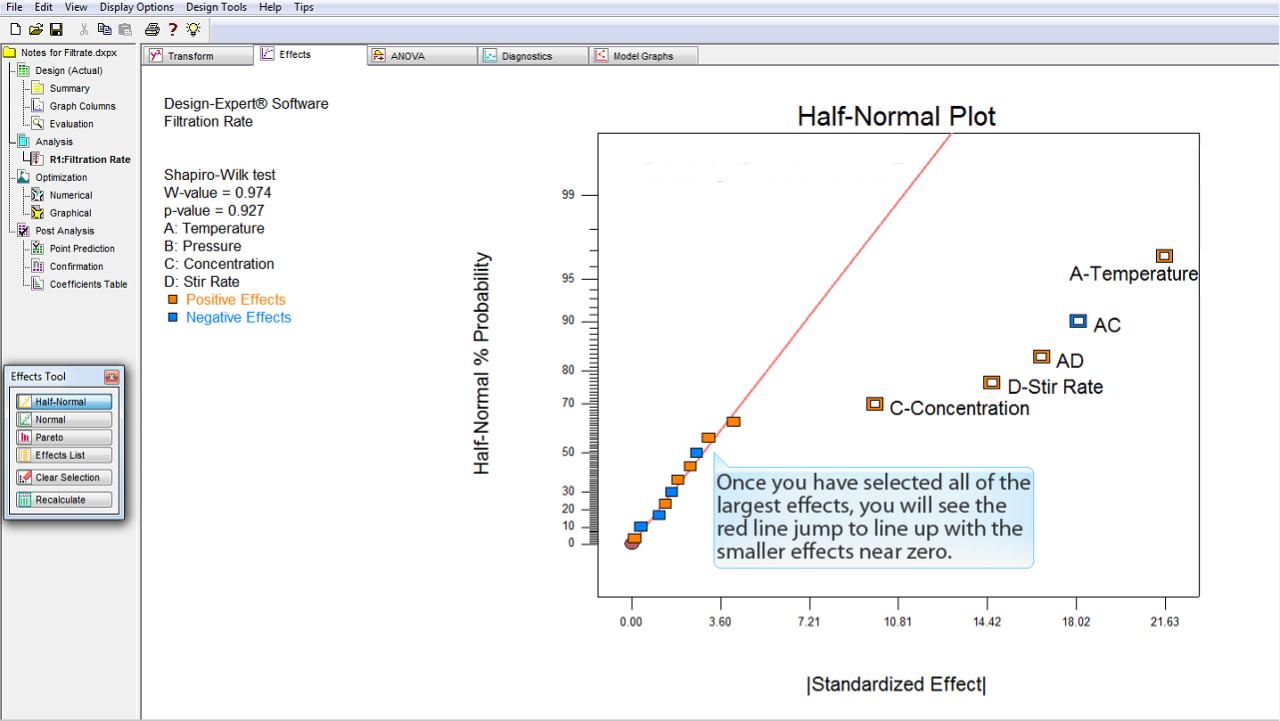
赤の直線のあてはめは、選択されていない点のみに対して行われている点に注意してください。したがって、効果を選択するたびに直線のあてはめが少しずつ移動することになります。
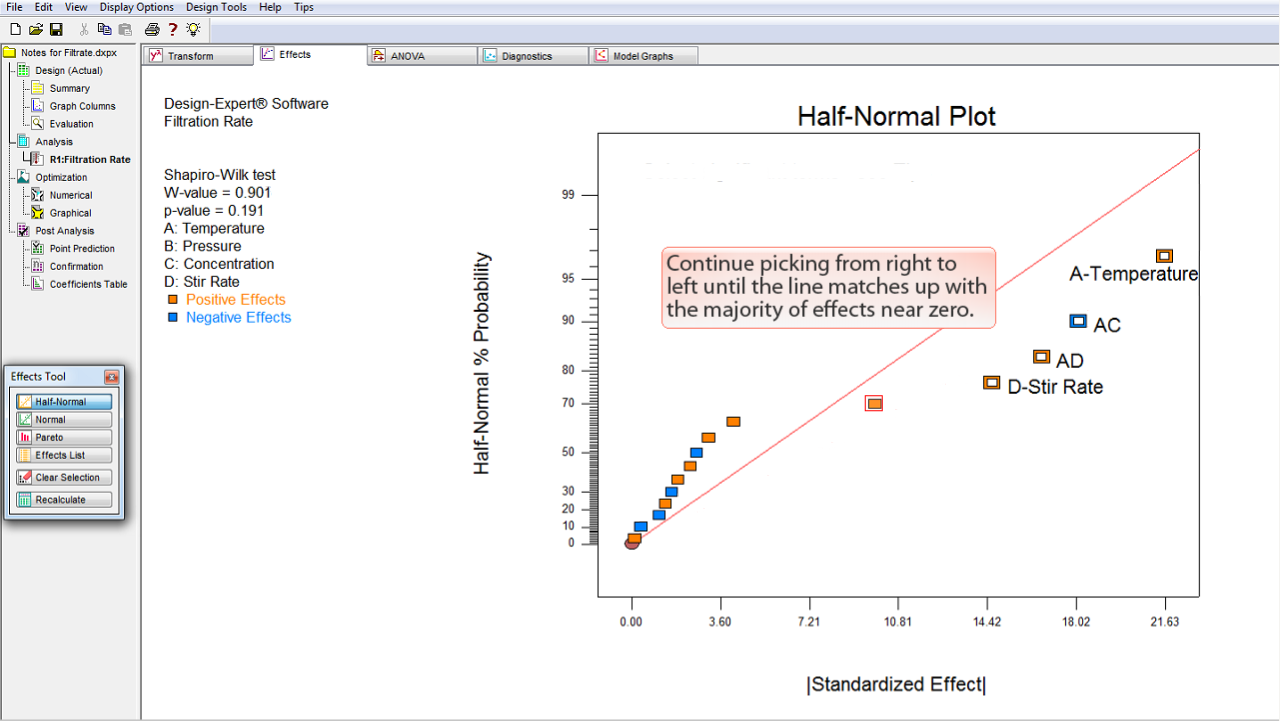
直線がゼロ付近にある大部分の効果と一致するまで、効果の選択を右から左へ進めていきます。
うまくいきました!大きな効果を全て選択できたようです。
最大効果の全てを選択できたら、赤の直線がゼロ付近の小さい効果に揃っているのを確認できるはずです。
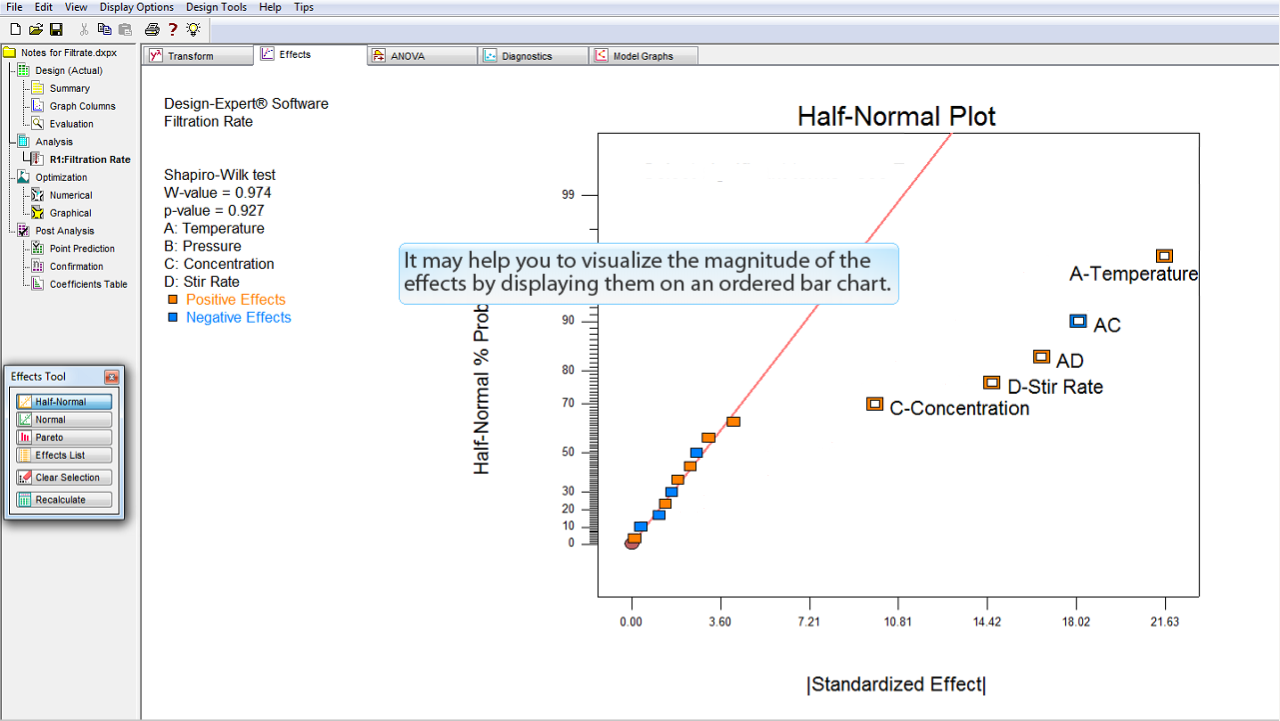
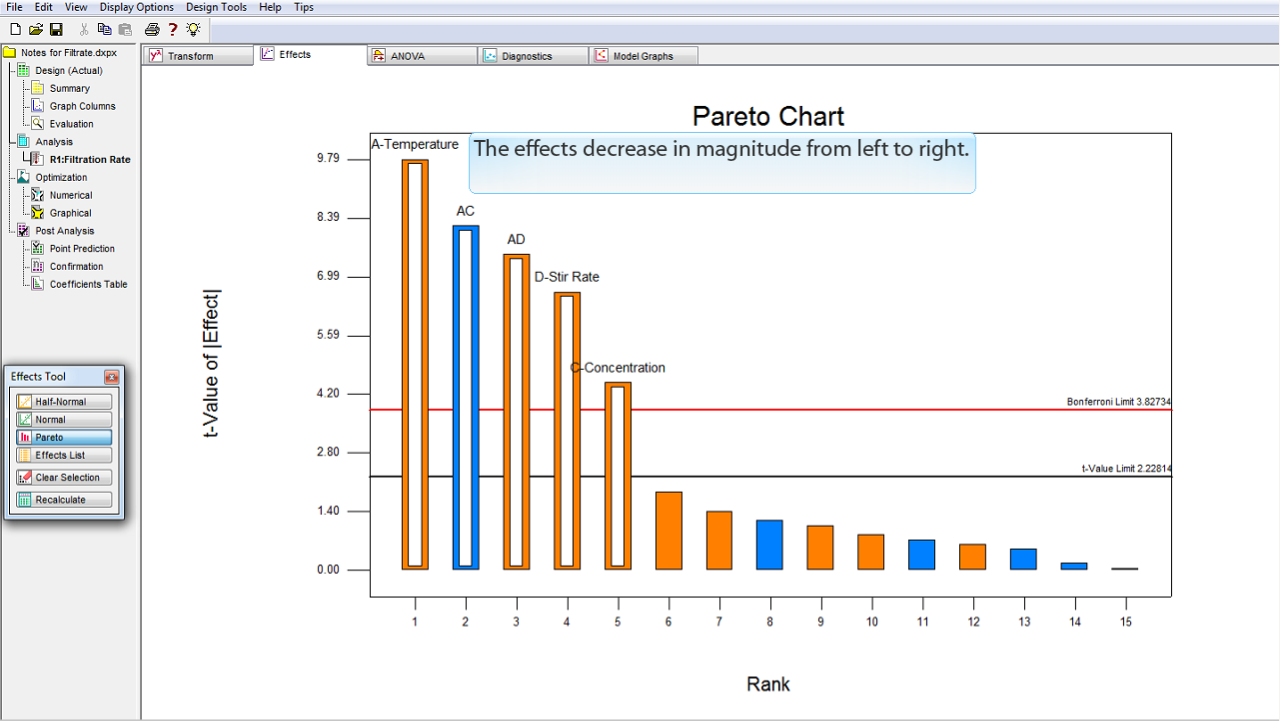
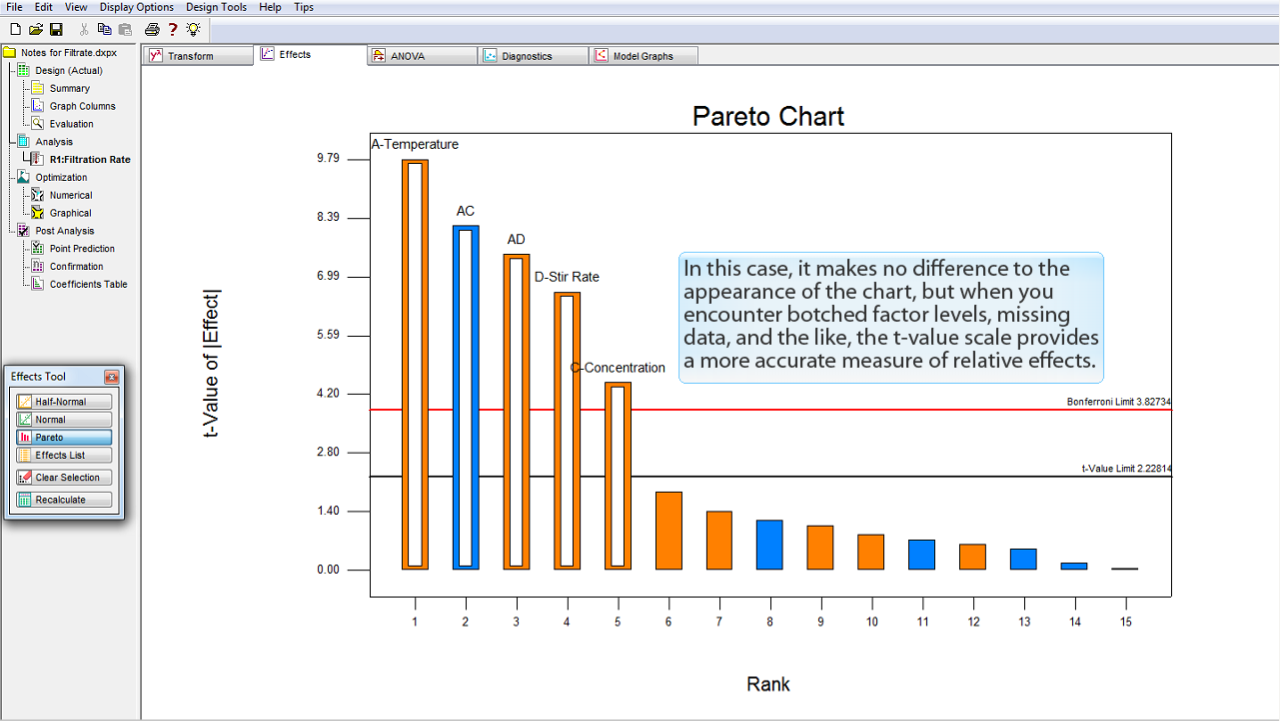
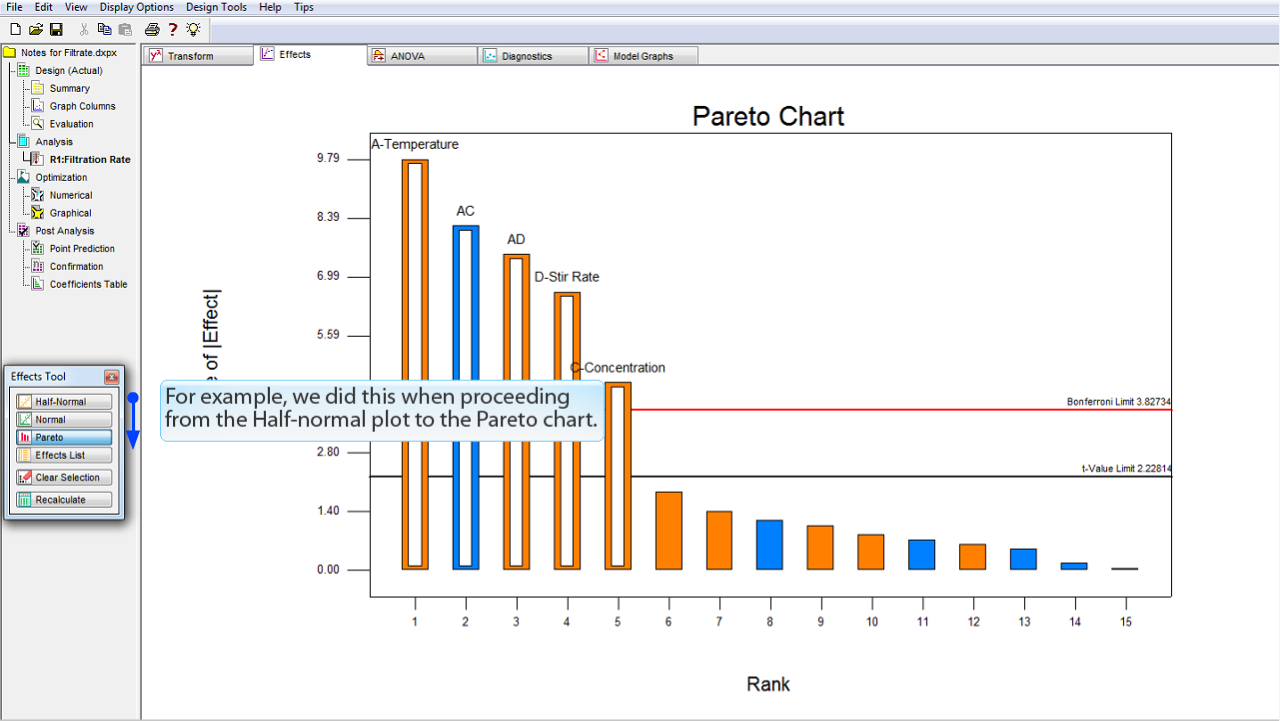
これらの効果は、その大きさを順番に並べたバーチャートに可視化すると役立つ場合があります。
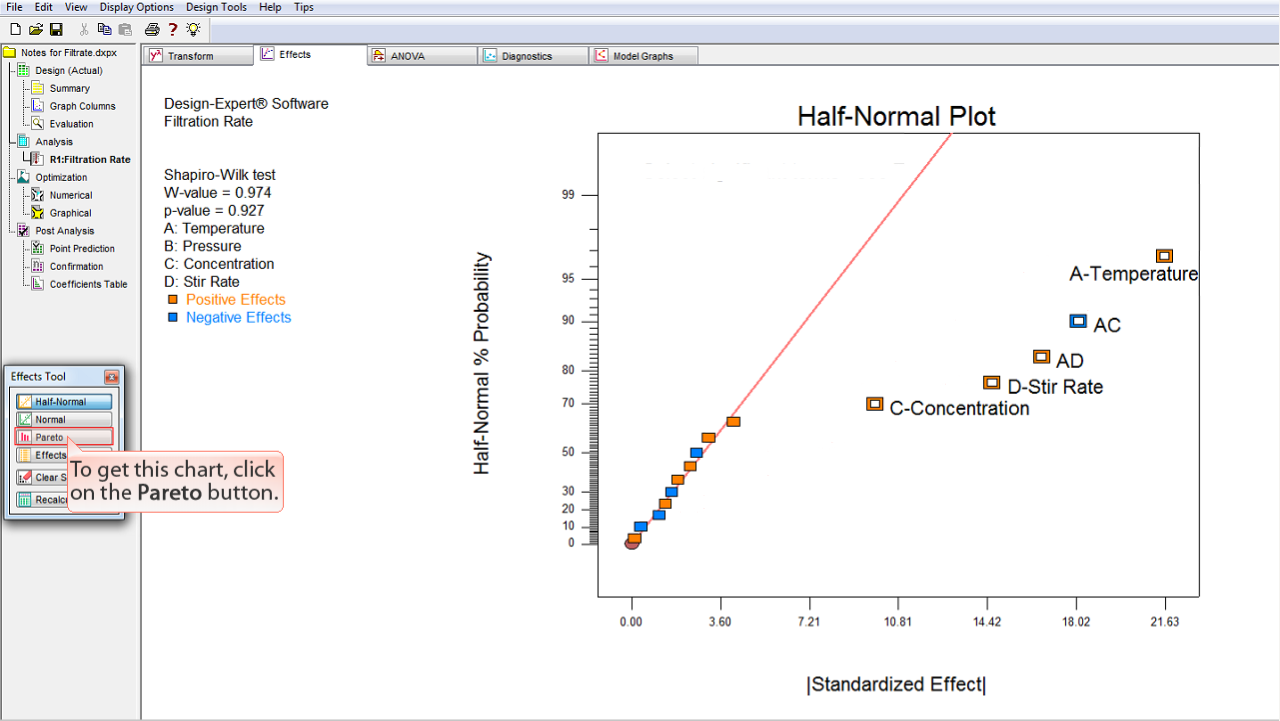
バーチャートを表示するには、
Pareto
ボタンをクリックします。
効果の大きさが、左から右へ向かって減少しています。
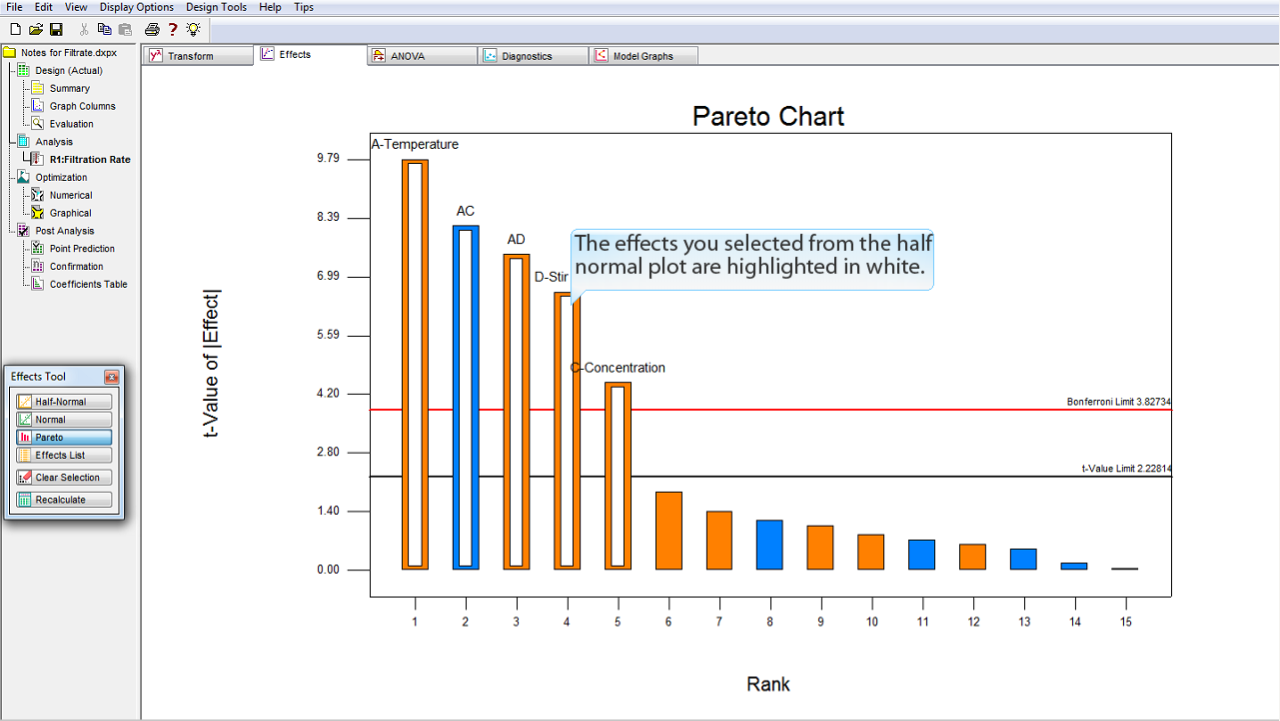
白で強調表示されているのは、半正規プロット (half-normal plot) で選択した効果です。
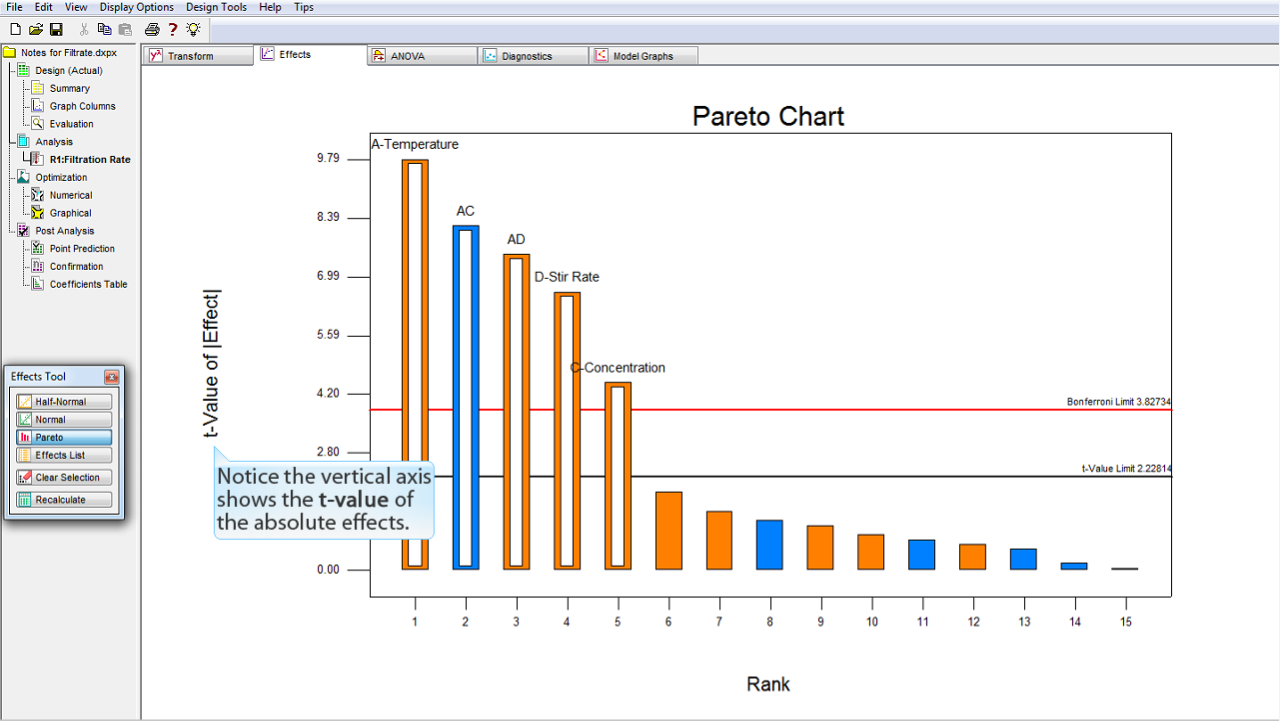
縦軸は効果の絶対値の
t-値 (t-value)
をあらわしている点に注意してください。
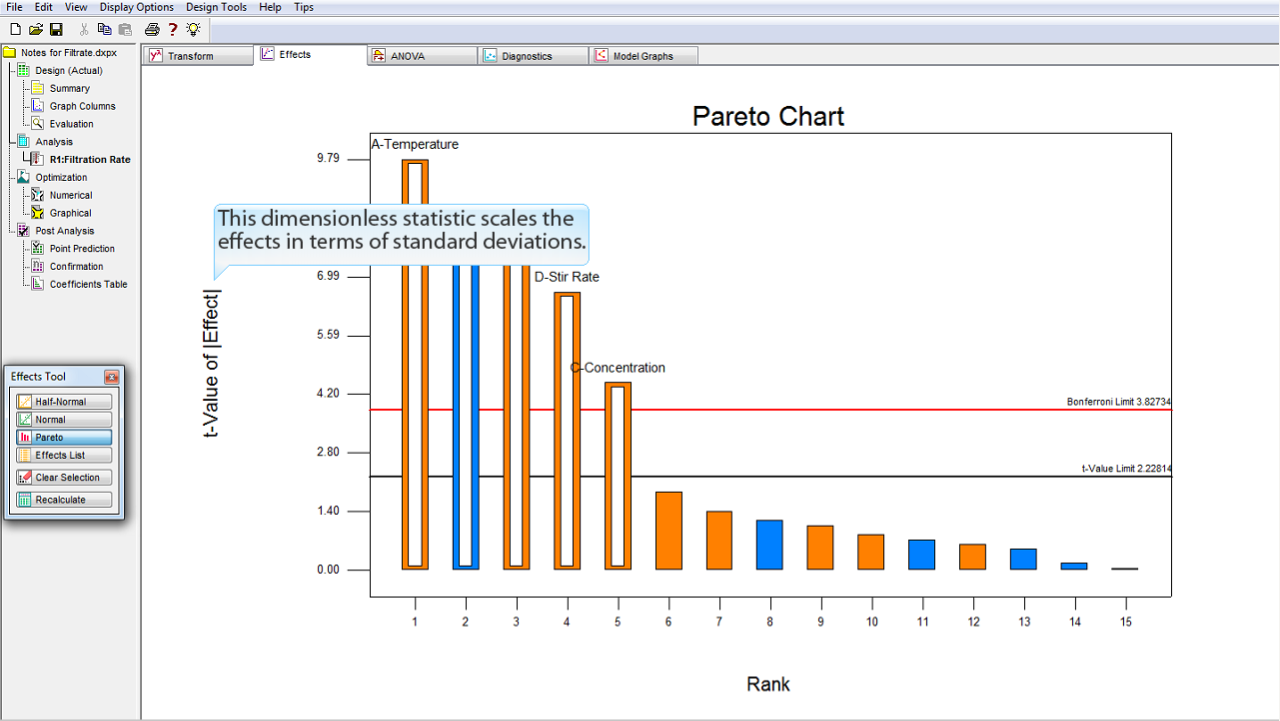
この無次元の統計量は、標準偏差で効果を計るものです。
この事例では、チャートの見た目に違いはありませんが、下手な因子水準や、欠損値などがある場合、相対的な効果の正確な尺度が t-値スケールで表示されます。
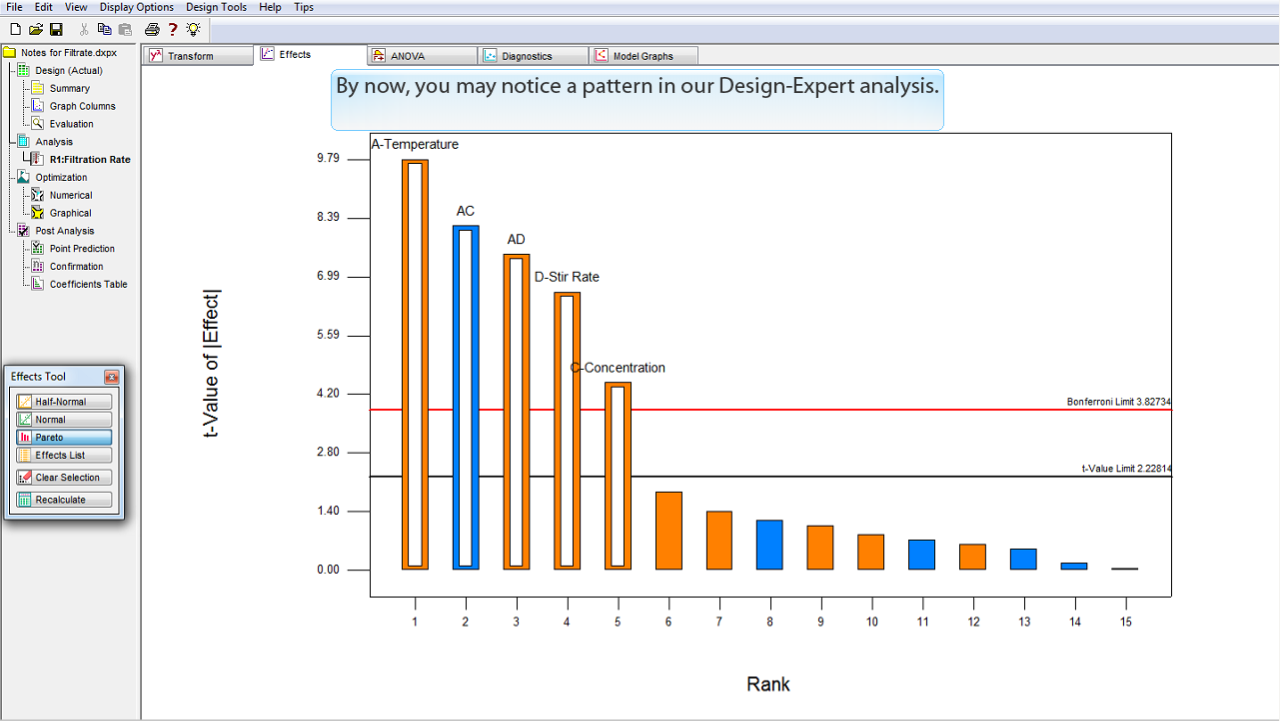
そろそろ Design-Expert の分析パターンにお気づきかも知れません。
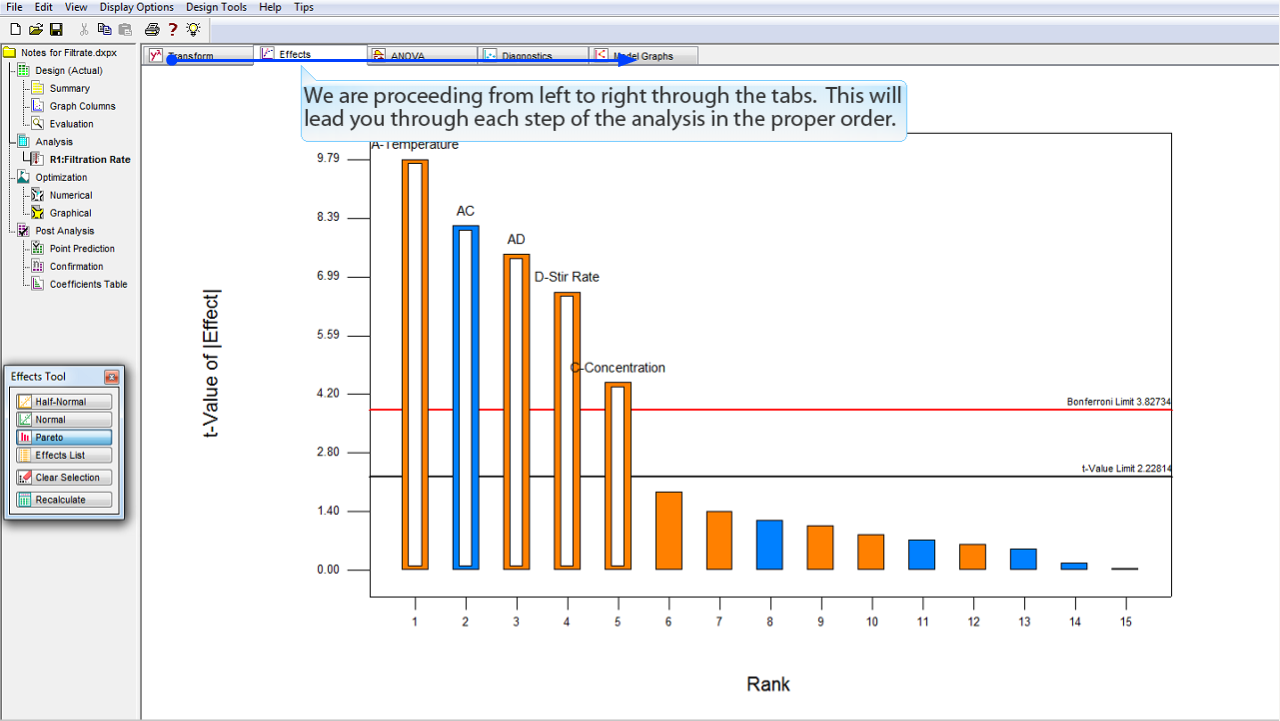
分析は左から右へタブの並んだ順に進んでいます。これに従うことで、分析の各段階を適切な順序で進めることができるわけです。
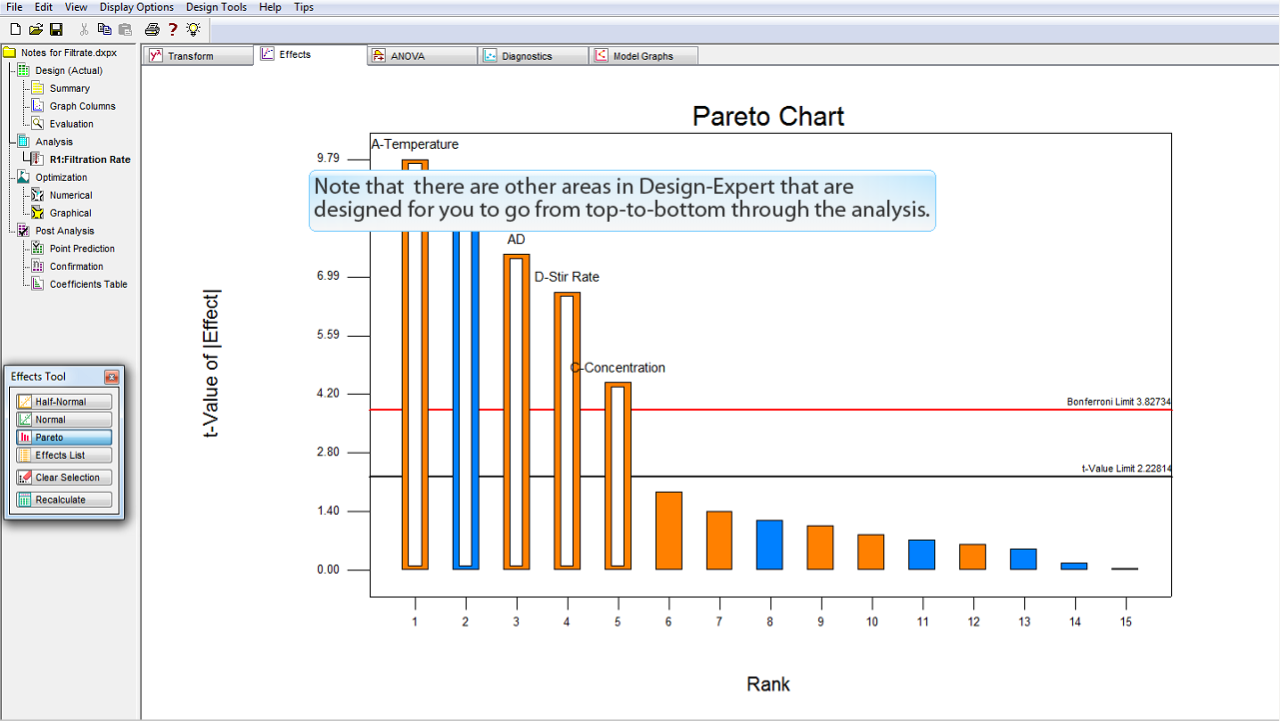
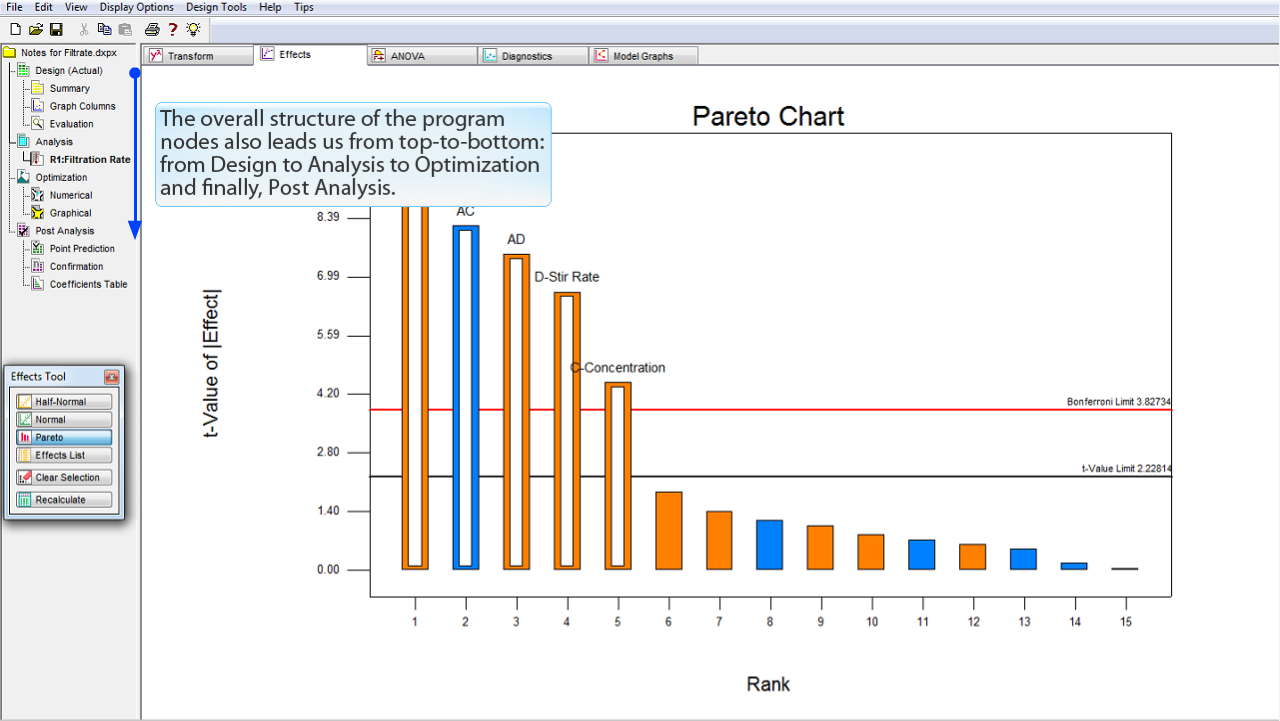
Design-Expert には、分析を通じて上から下へ進むように設計されている別な領域がある点にも注意してください。
例えば、半正規プロットからパレート図へ進んだときがそうです。
プログラムのノード構造全体も上から下へと進みます:実験の計画 (Design) から分析 (Analysis)、そして、最適化 (Optimization) へと進み、最後に、事後分析 (Post Analysis) を行うという具合です。
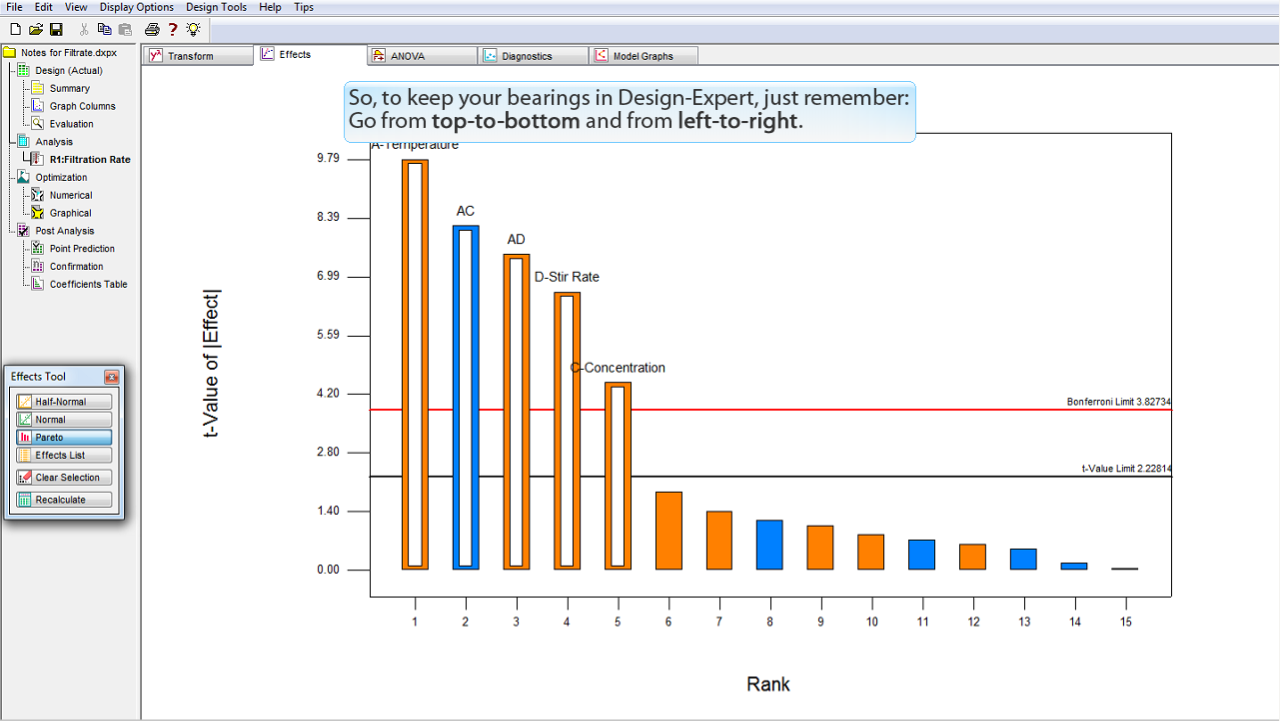
したがって、Design-Expert で現在地を見失わないようにするには次のことを憶えておくだけで十分です:上から下へ、そして、左から右へ進めです。
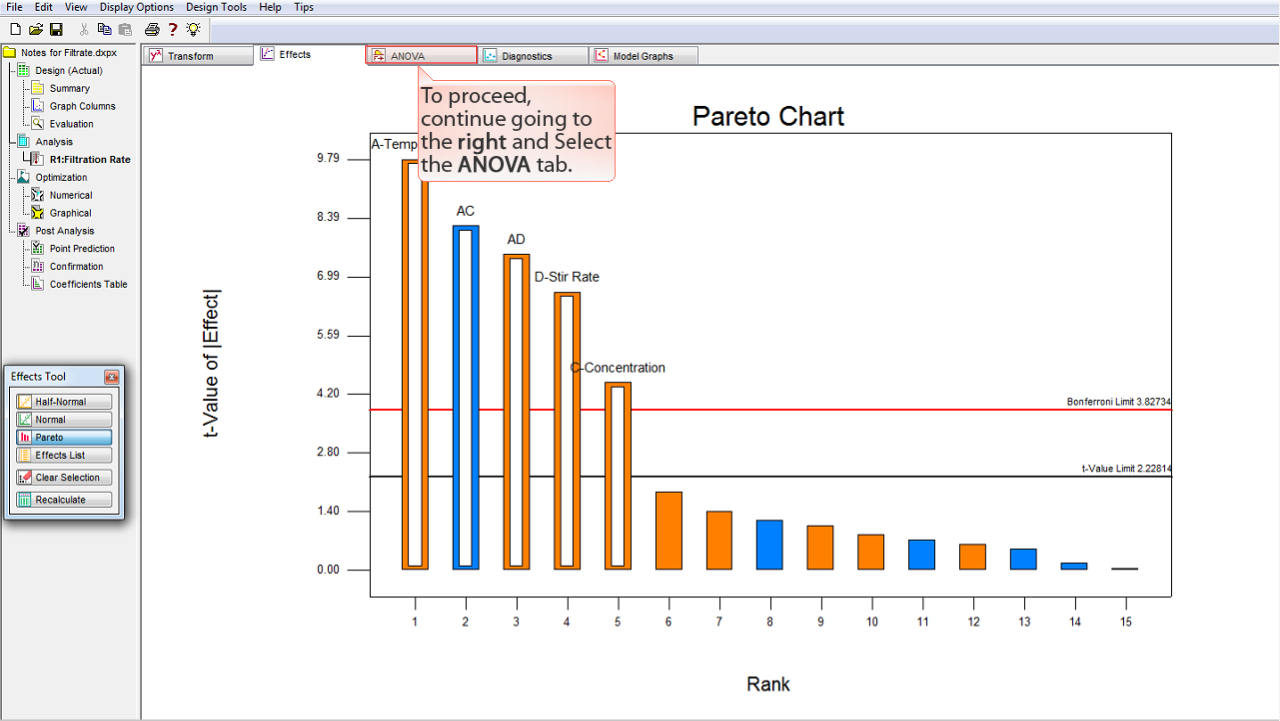
分析を進めましょう。右側に進んで
ANOVA
タブを選択します。
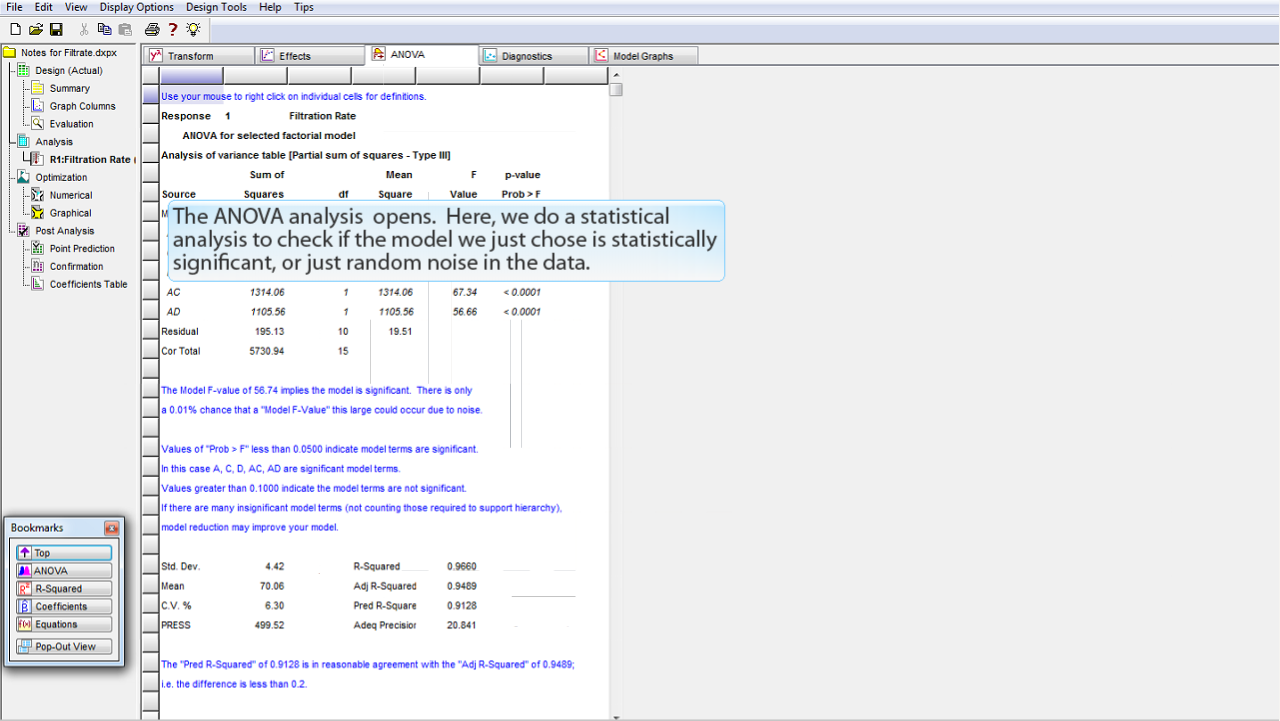
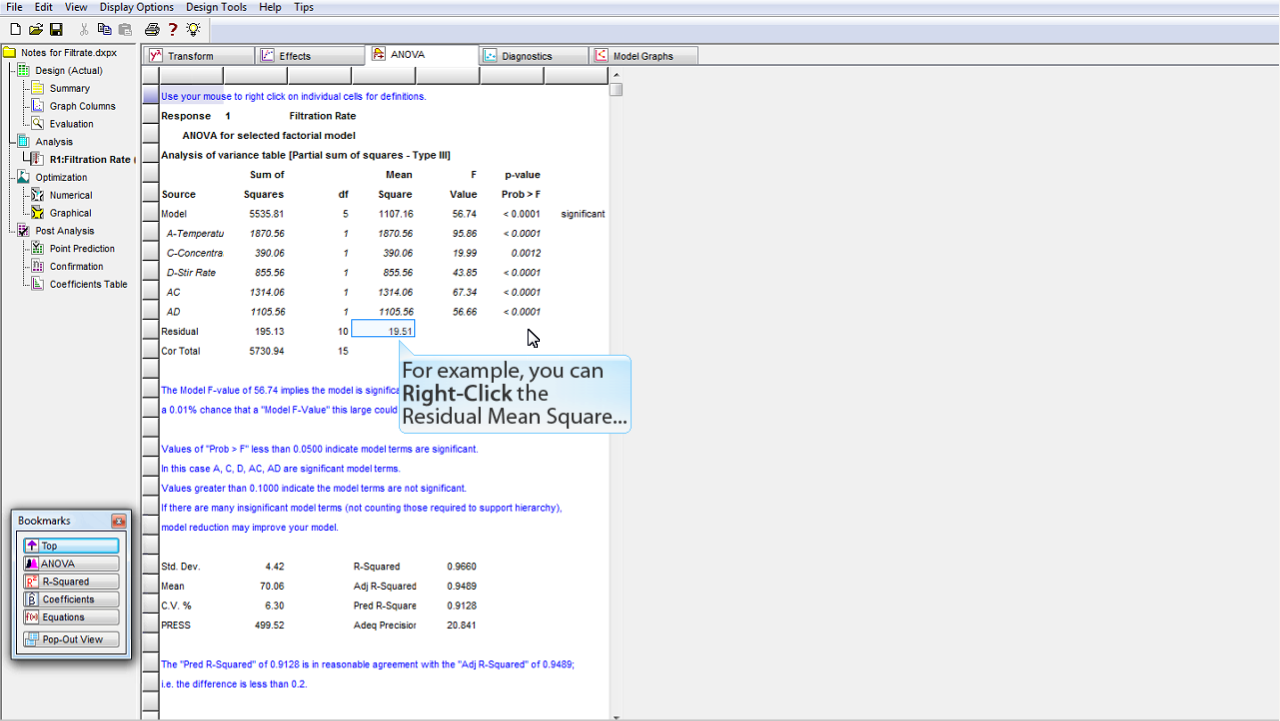
ANOVA 分析の内容が表示されます。ここでは、選択したモデルが統計的に有意なものか、それとも、ランダムなデータのノイズに過ぎないかをチェックするために統計解析を行います。
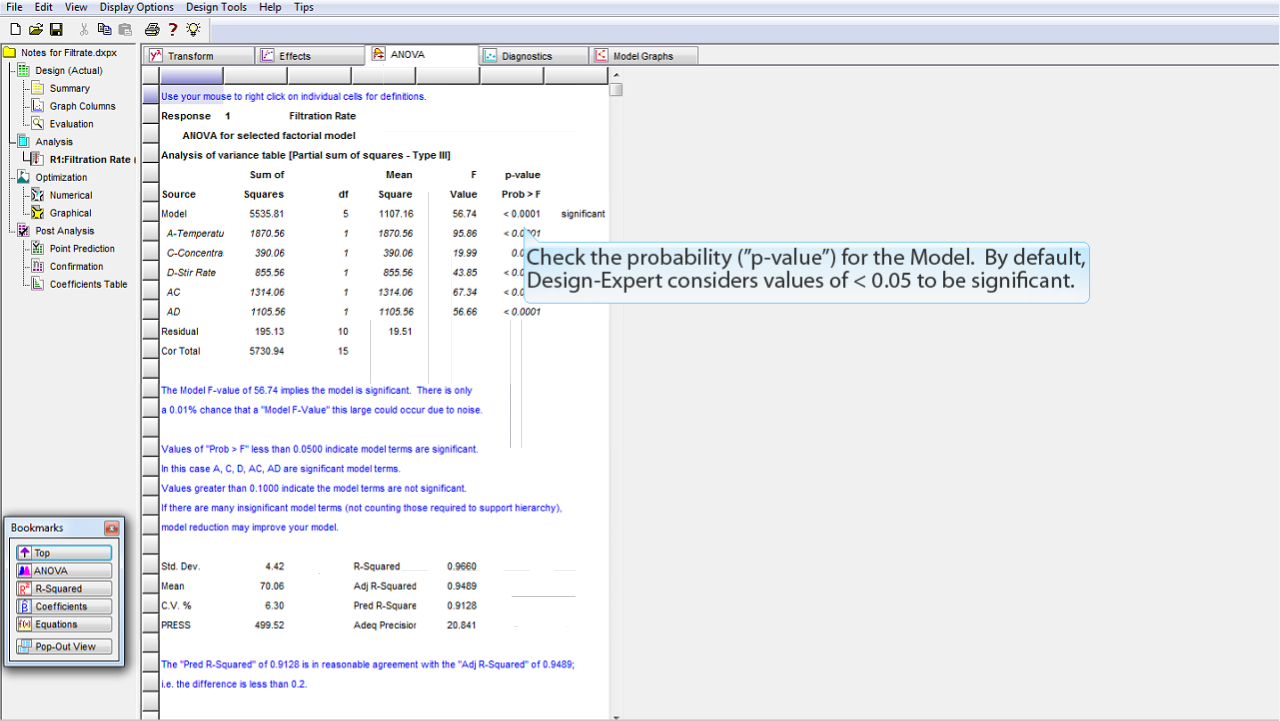
モデル (Model) の p 値 ("p-value": 確率値) をチェックします。Design-Expert のデフォルトは、この値が <0.05 であれば有意であると設定されています。
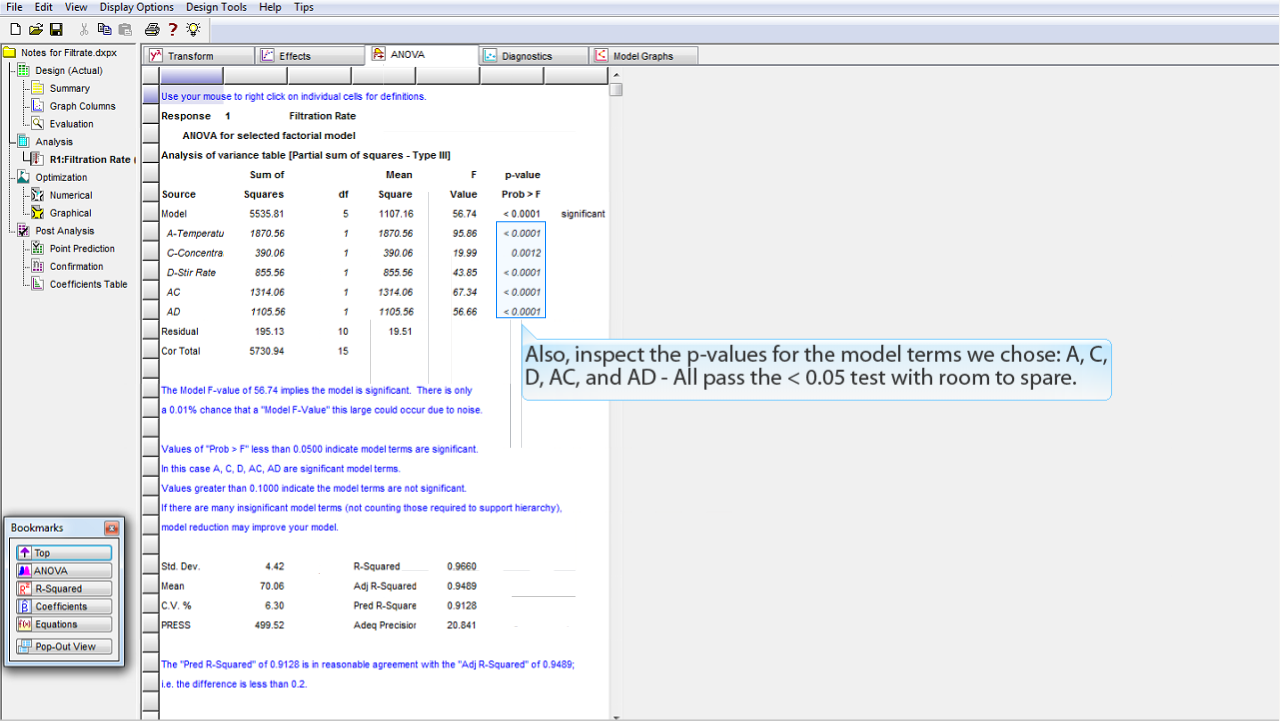
選択したモデル項 (A, C, D, AC, AD) の p 値についても調べてみましょう。いずれも余裕をもって <0.05 をクリアしています。
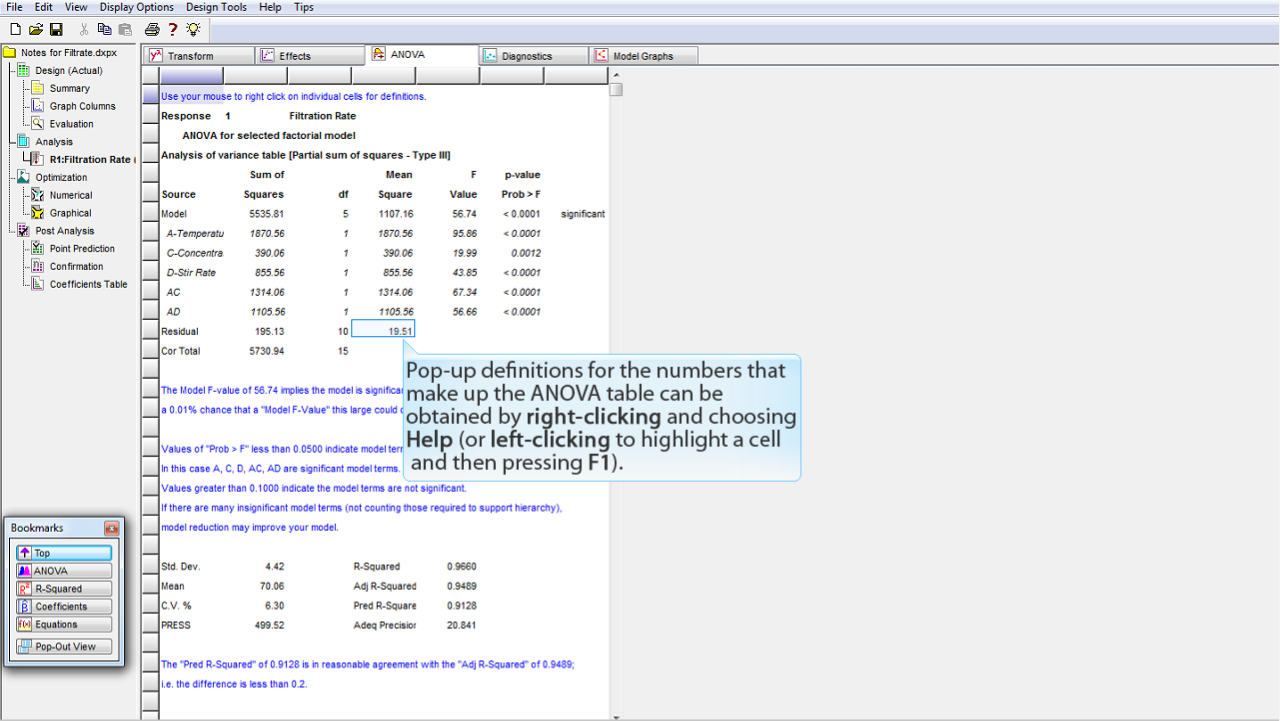
ANOVA テーブルを構成する各数字の定義については、そこを
右クリック
して
Help
を選択することで、ポップアップによる説明をそれぞれ表示させることができます (
左クリック
でセルを選択状態にしたあと
F1
キーを押しても同じです)。
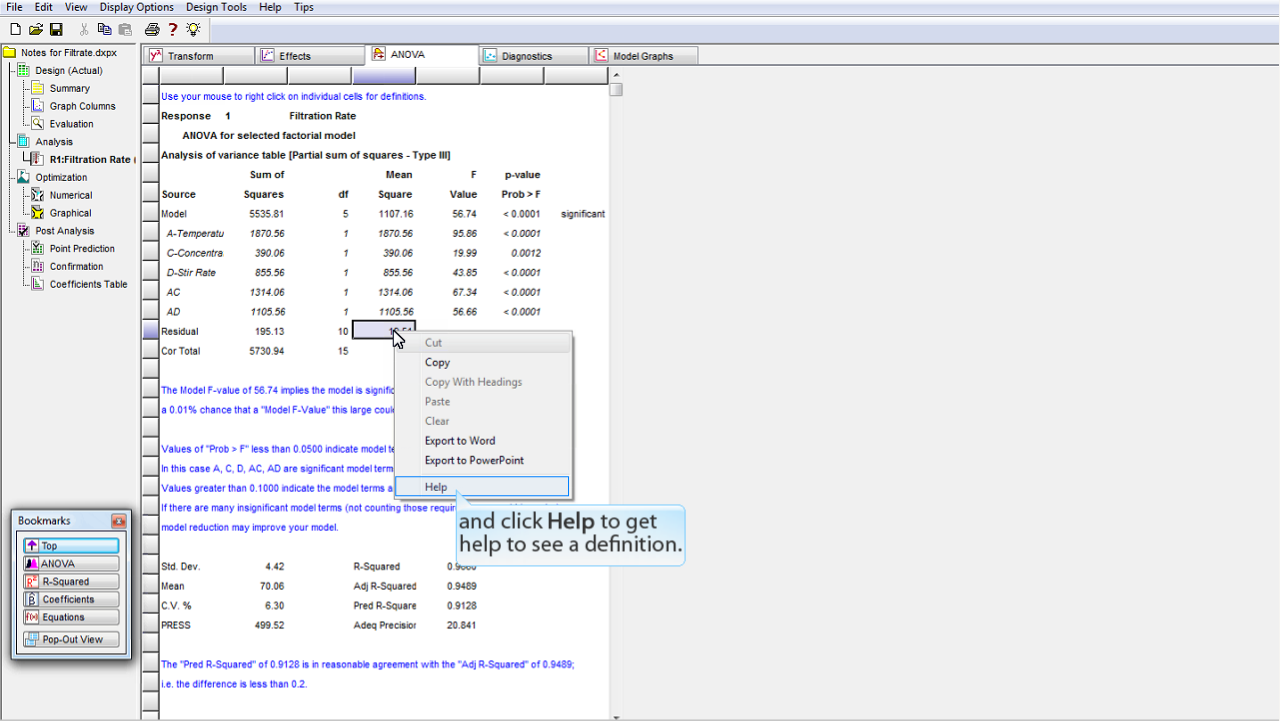
例えば、Residual Mean Square (残差の平均平方) を
右クリック
するとしましょう。
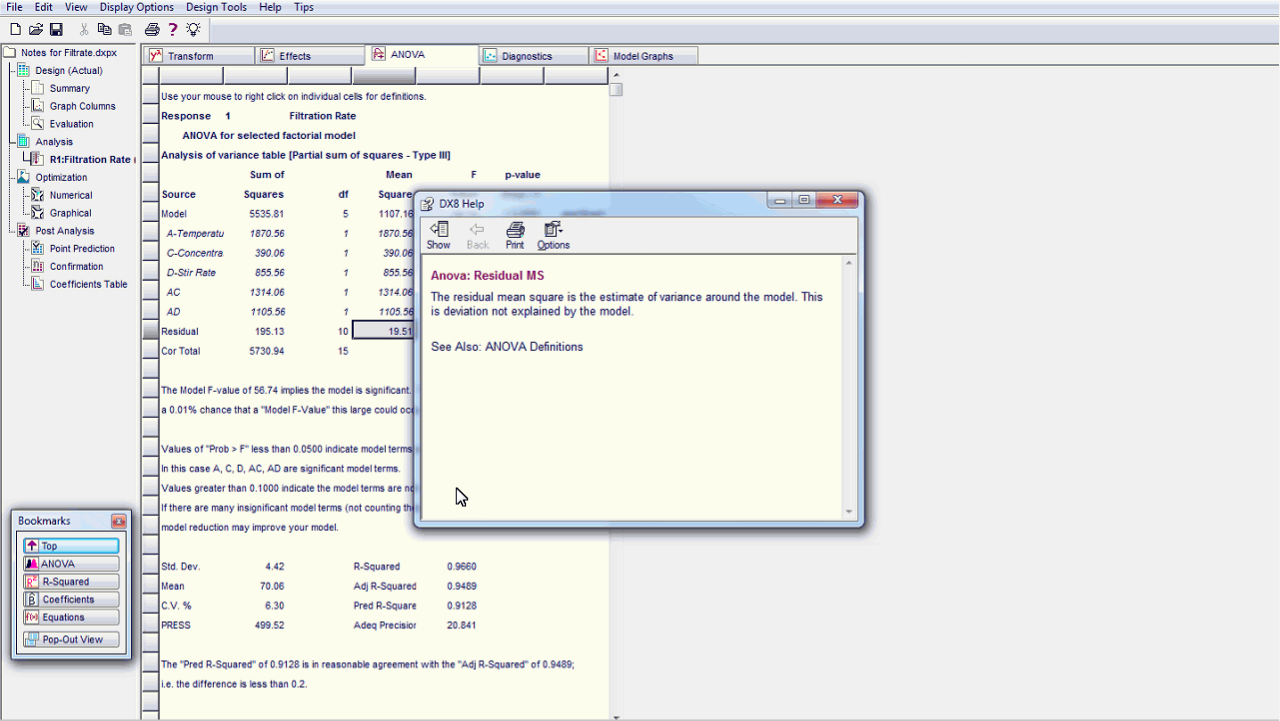
ここで
Help
をクリックすると、定義されたヘルプの内容が表示されます。
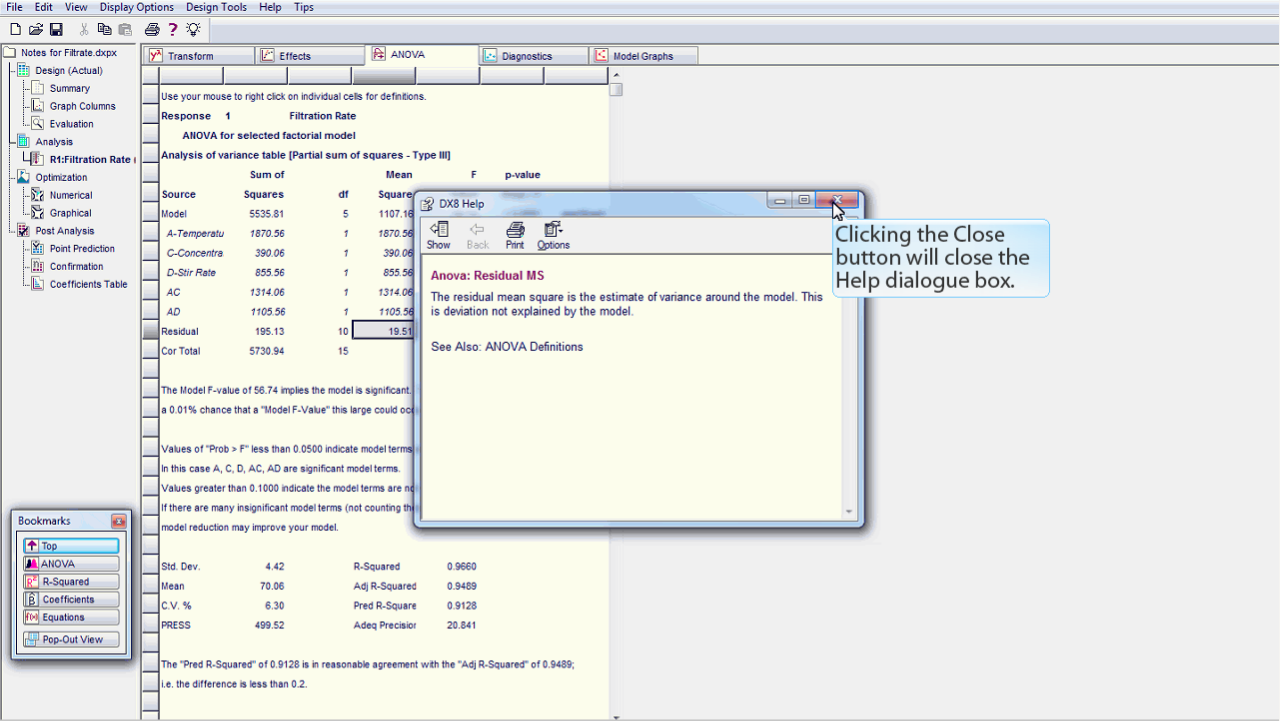
Help ダイアログボックスを閉じるには、閉じるボタンをクリックします。
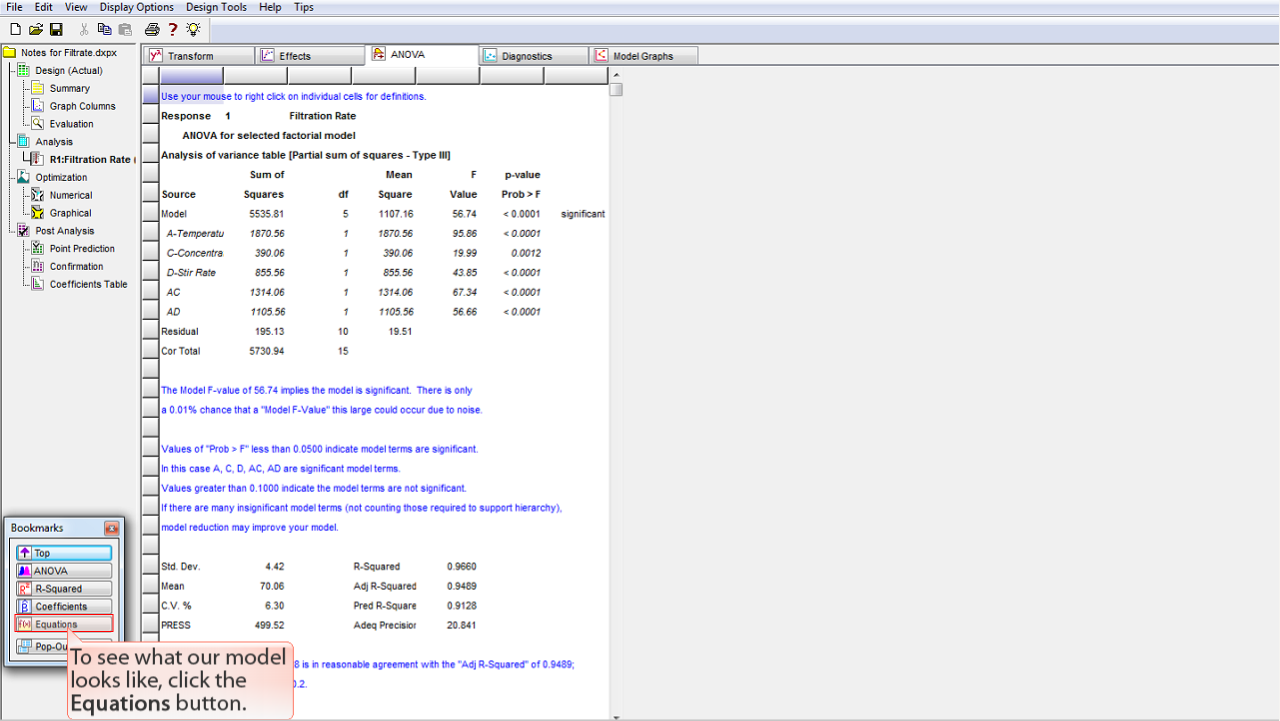
現在のモデルの状態を確認するには、
Equations
ボタンをクリックします。
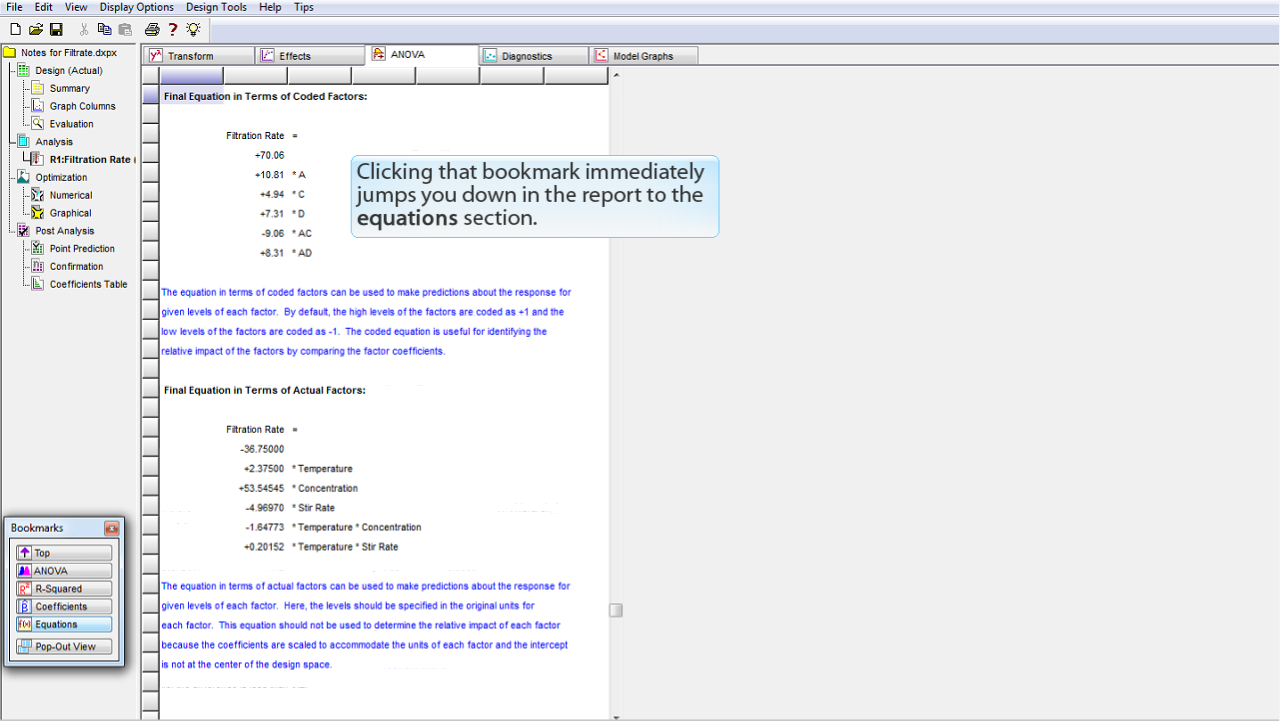
目的のブックマークをクリックすることで、レポート内の Equations セクションに素早く移動することができます。
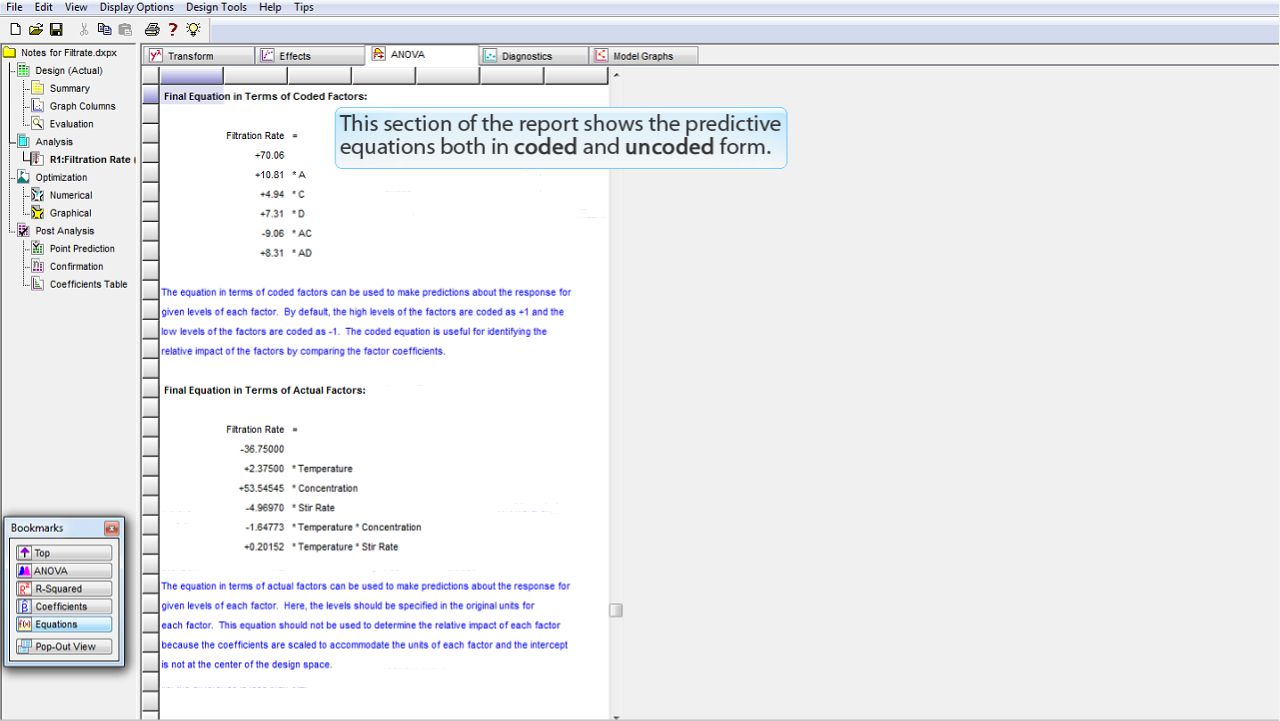
このセクションのレポートには、符号化された (coded) 形式と符号化されていない (Uncoded) 形式の両方で予測方程式が表示されています。
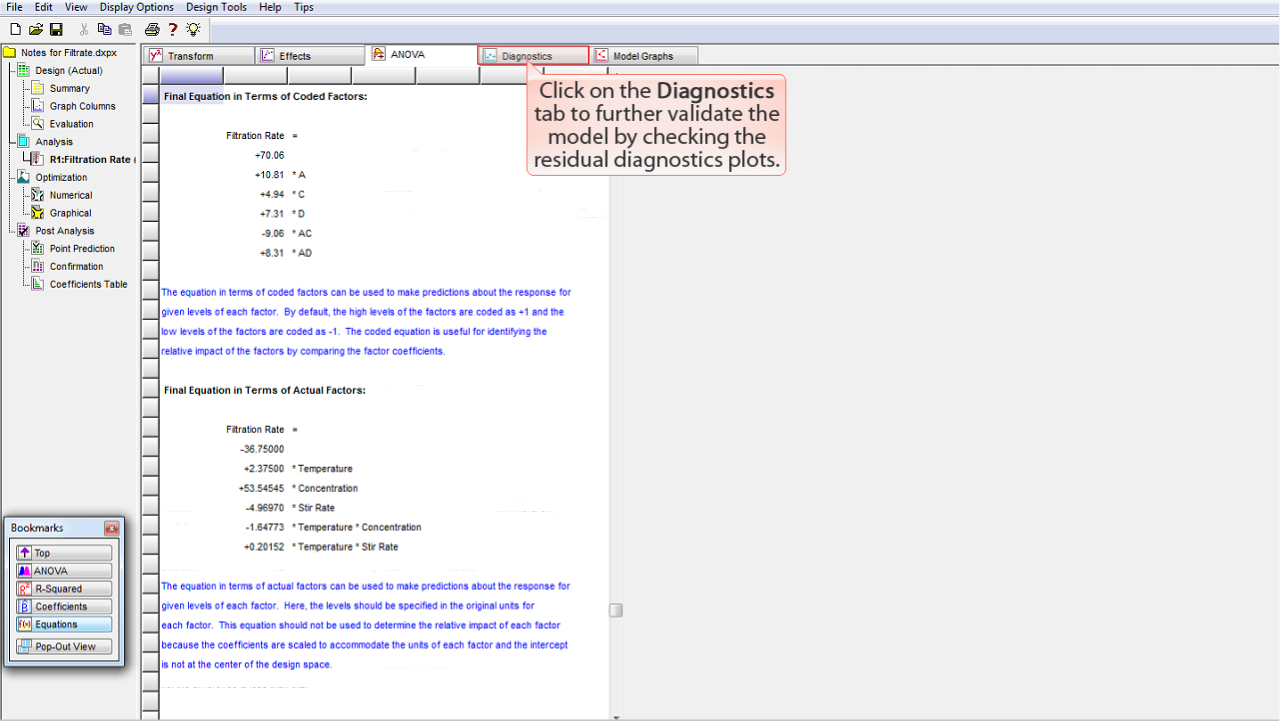
Diagnostics
タブをクリックすると、残差診断プロットをチェックすることで、モデルの検証をさらに進めることができます。
Dianostics Tool
が表示されます。
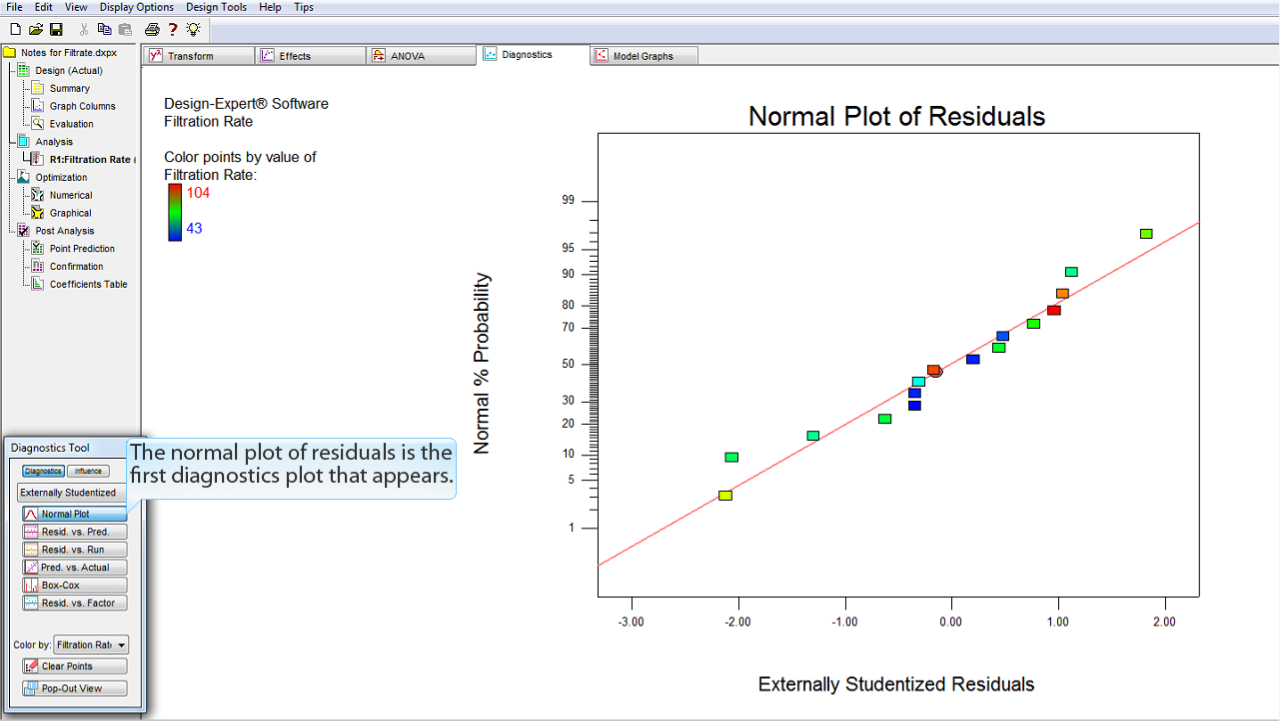
表示される最初の診断プロットは、残差の正規プロットです。
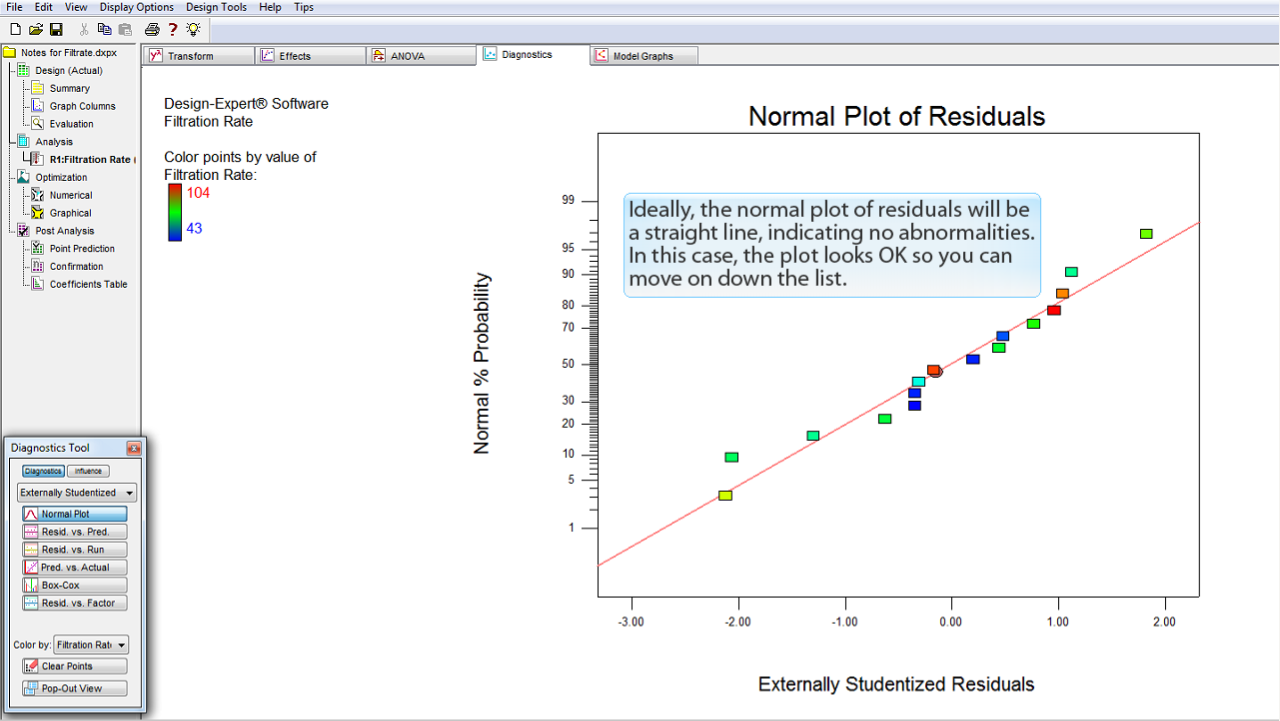
残差の正規プロットは、異常が無いことをあらわす直線になるのが理想的です。この事例では、プロットの状態に問題はありませんので、リストの次の項目に移動することができます。
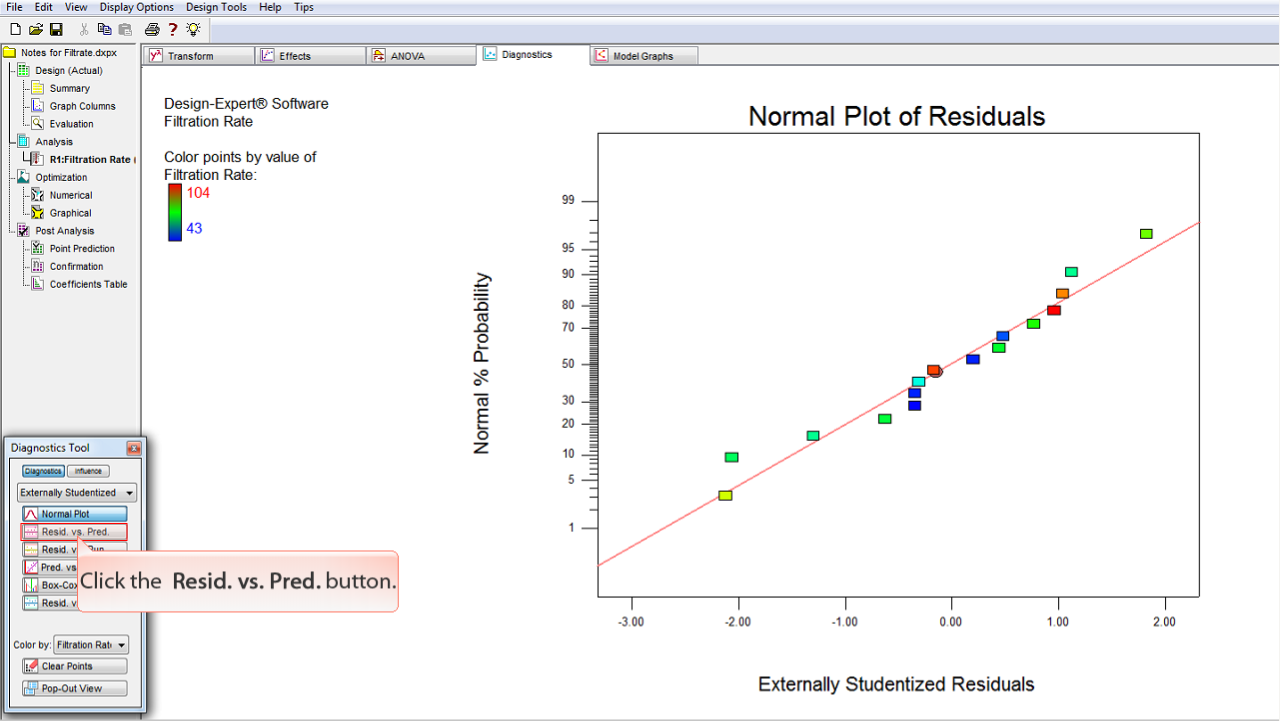
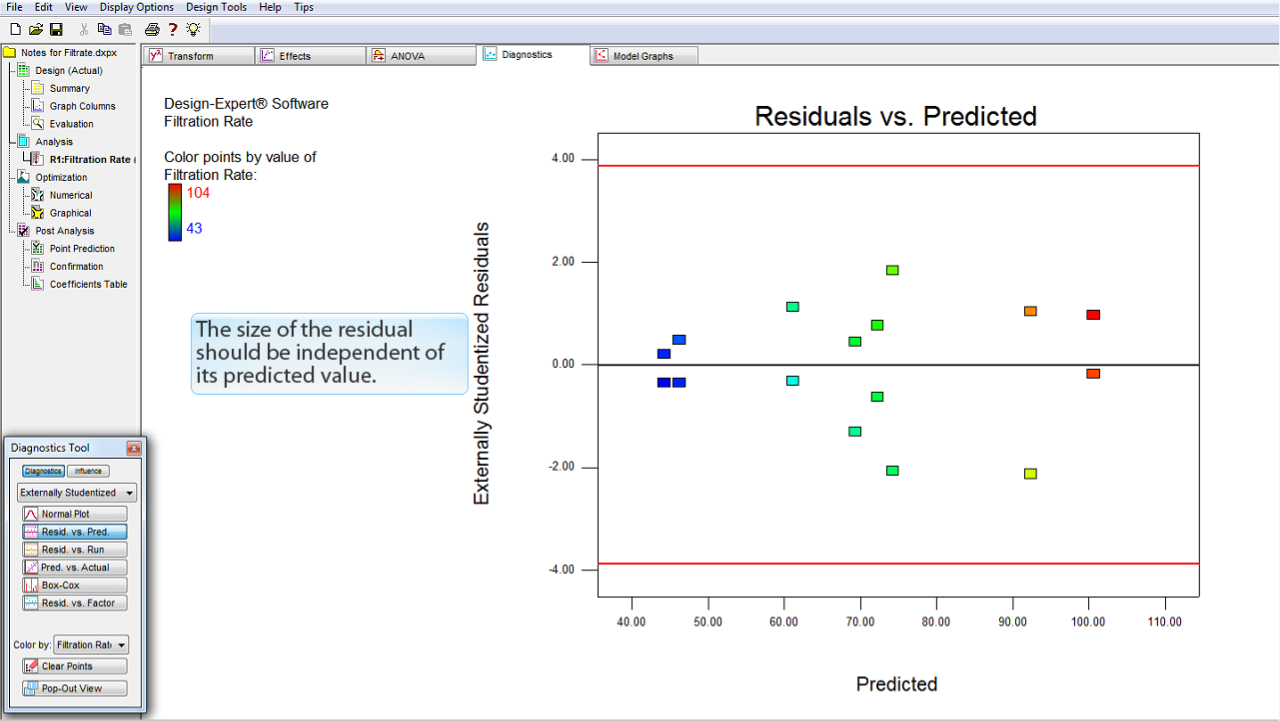
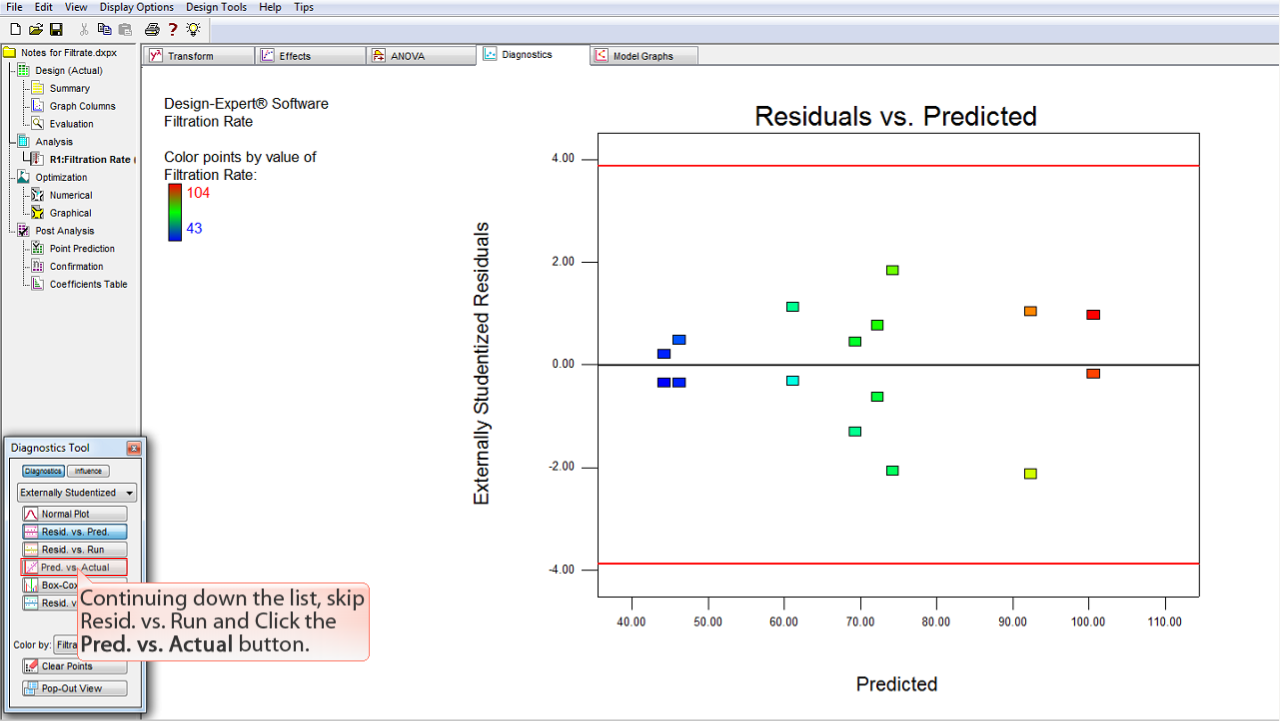
Resid. vs. Pred.
ボタンをクリックします。
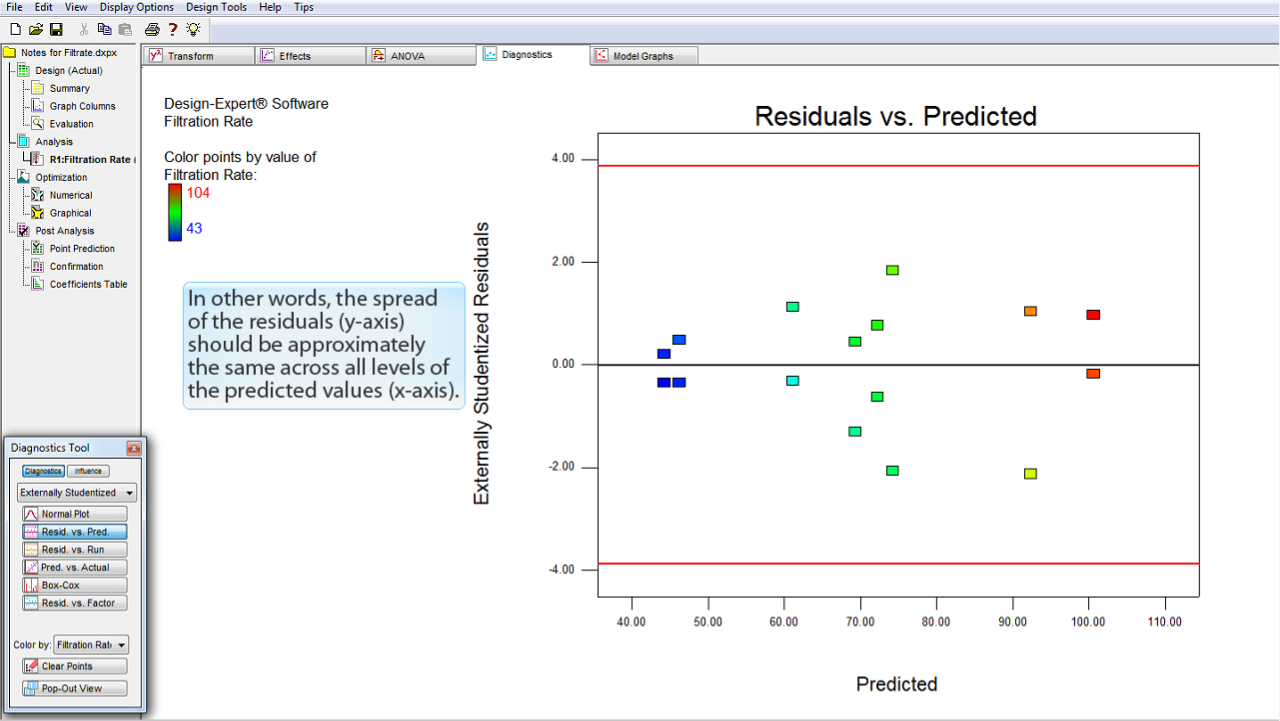
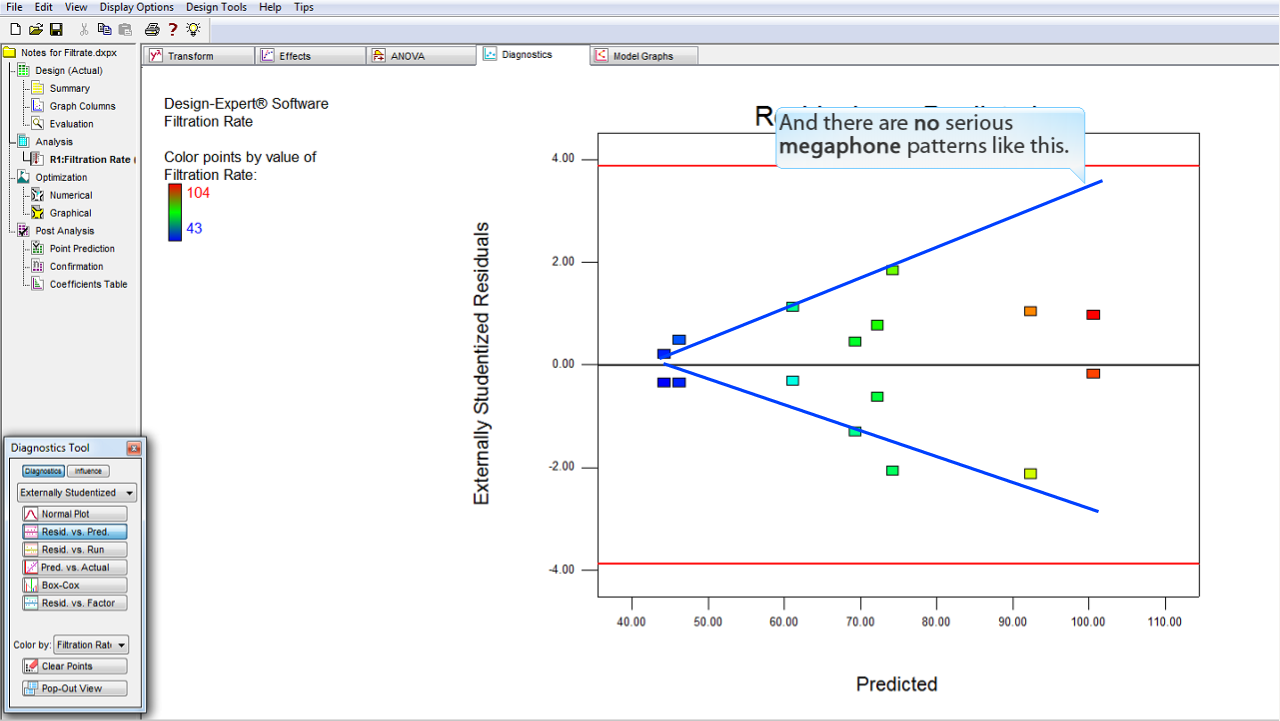
残差 (Residuals) のサイズは、その予測値 (Predicted) に対して独立しているはずです。
別の言葉で言い換えると、残差の広がり (Y 軸) は、予測値の水準の全体を通じてほぼ同じになるはずです。
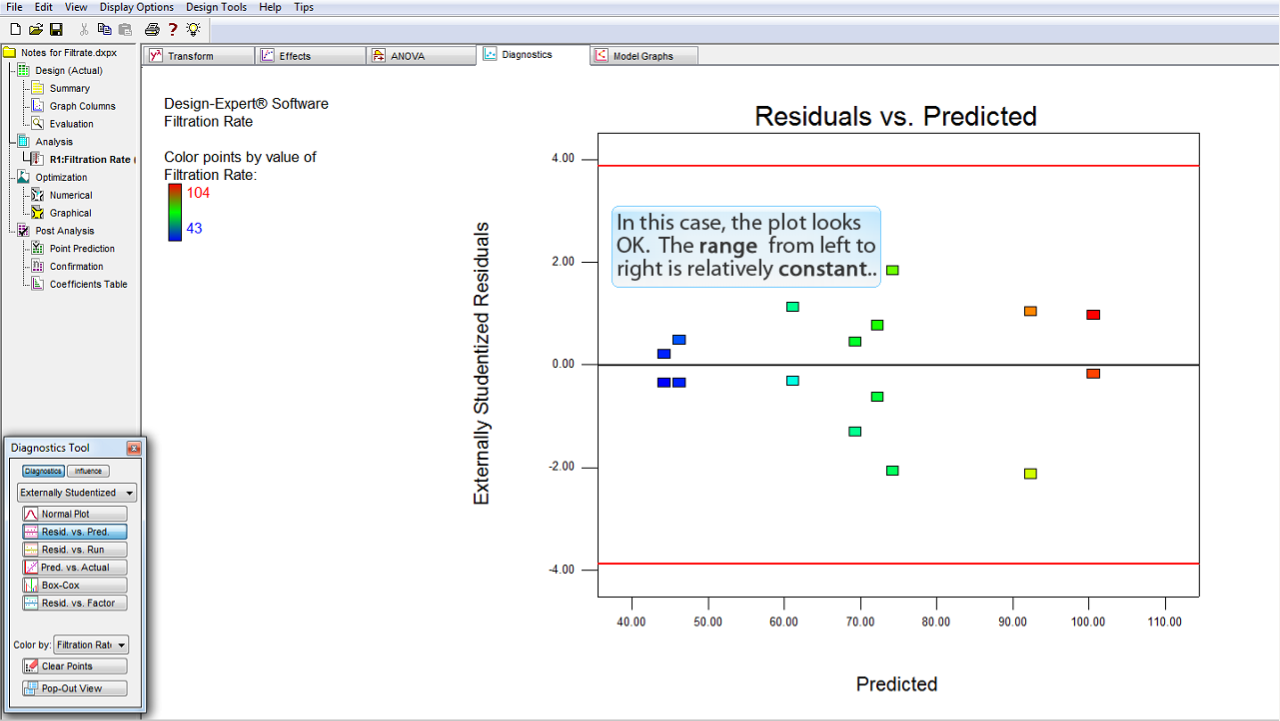
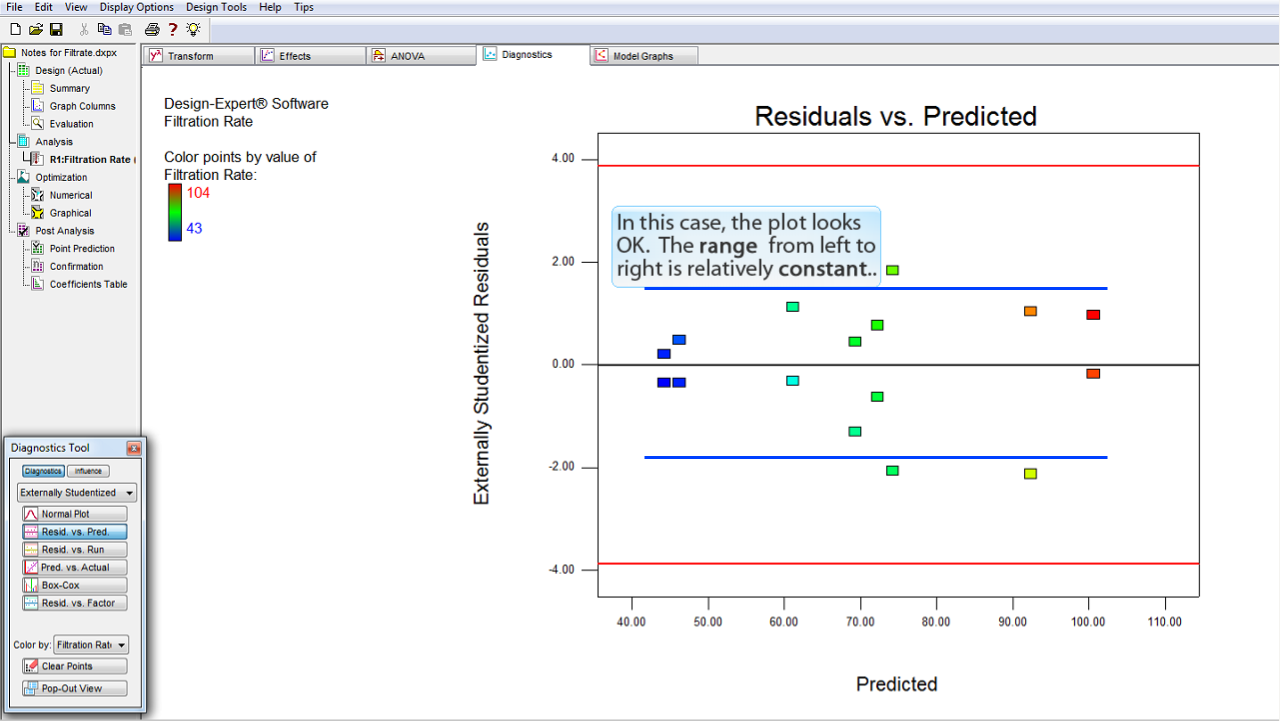
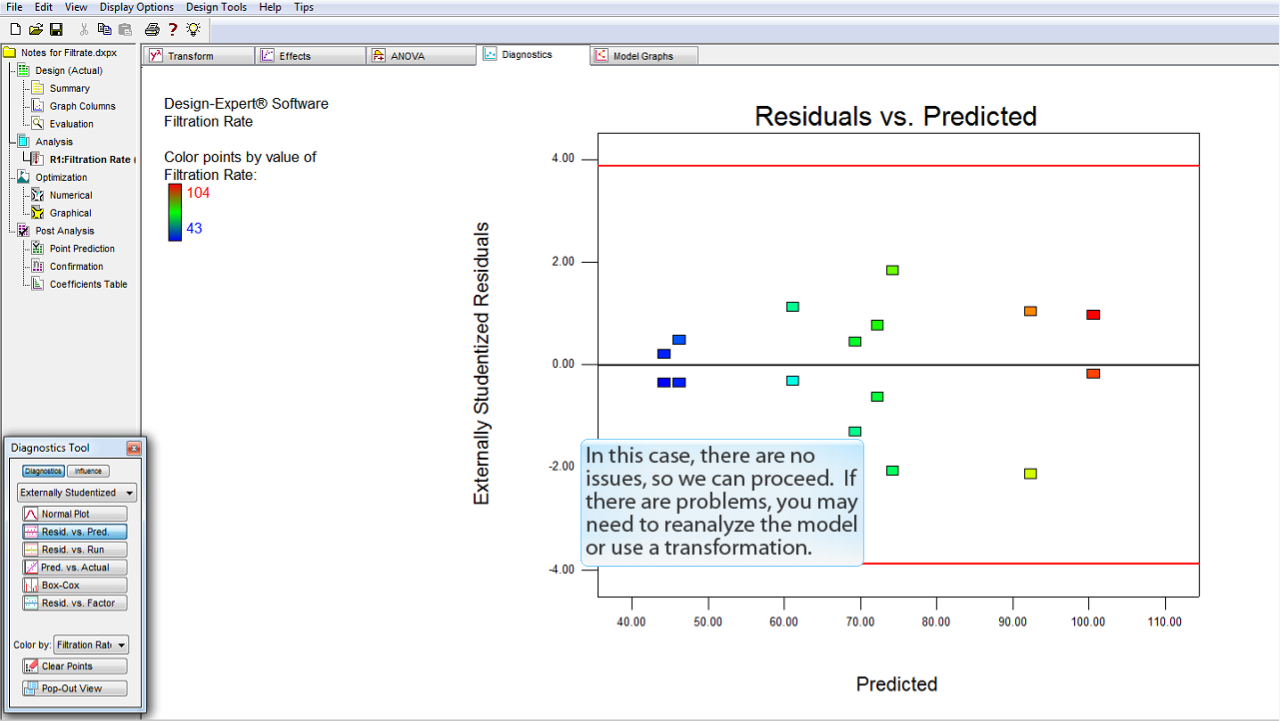
この事例のプロットについては、問題ないと判断できます。プロットの範囲が左から右へかけて比較的一定になっているからです。
以下のような極端なメガホン型のパターンにはなっていません。
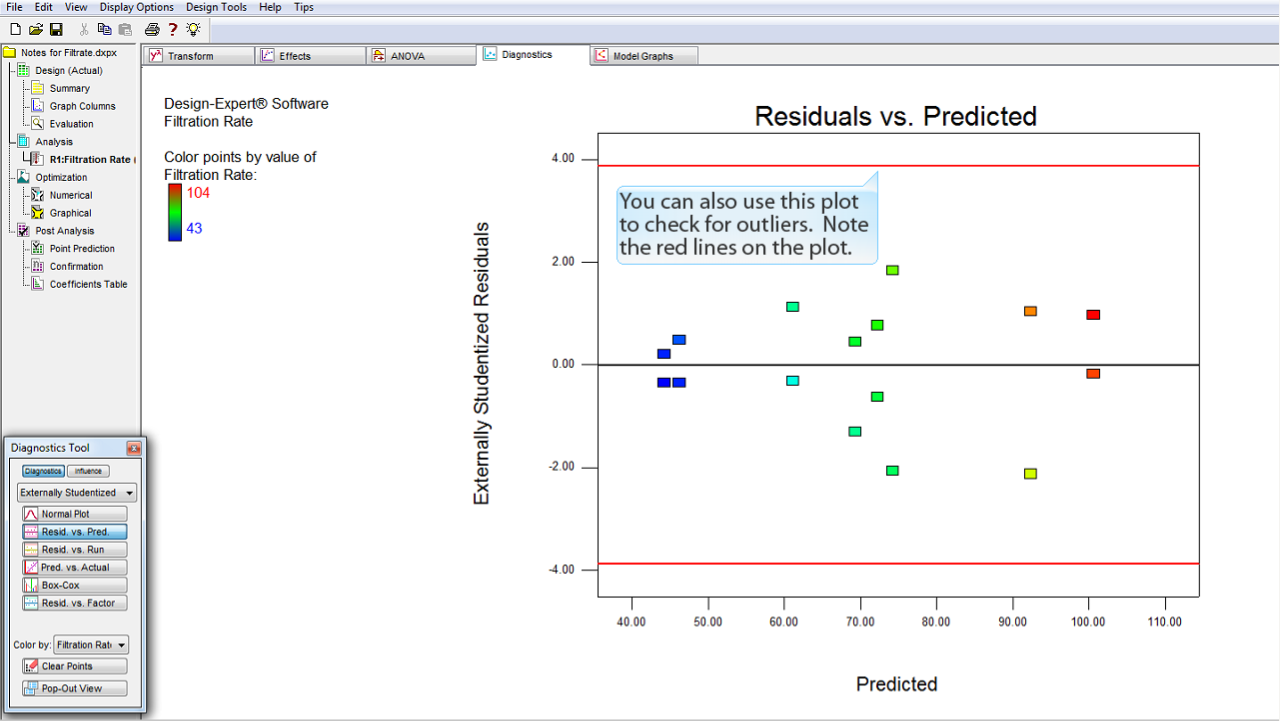
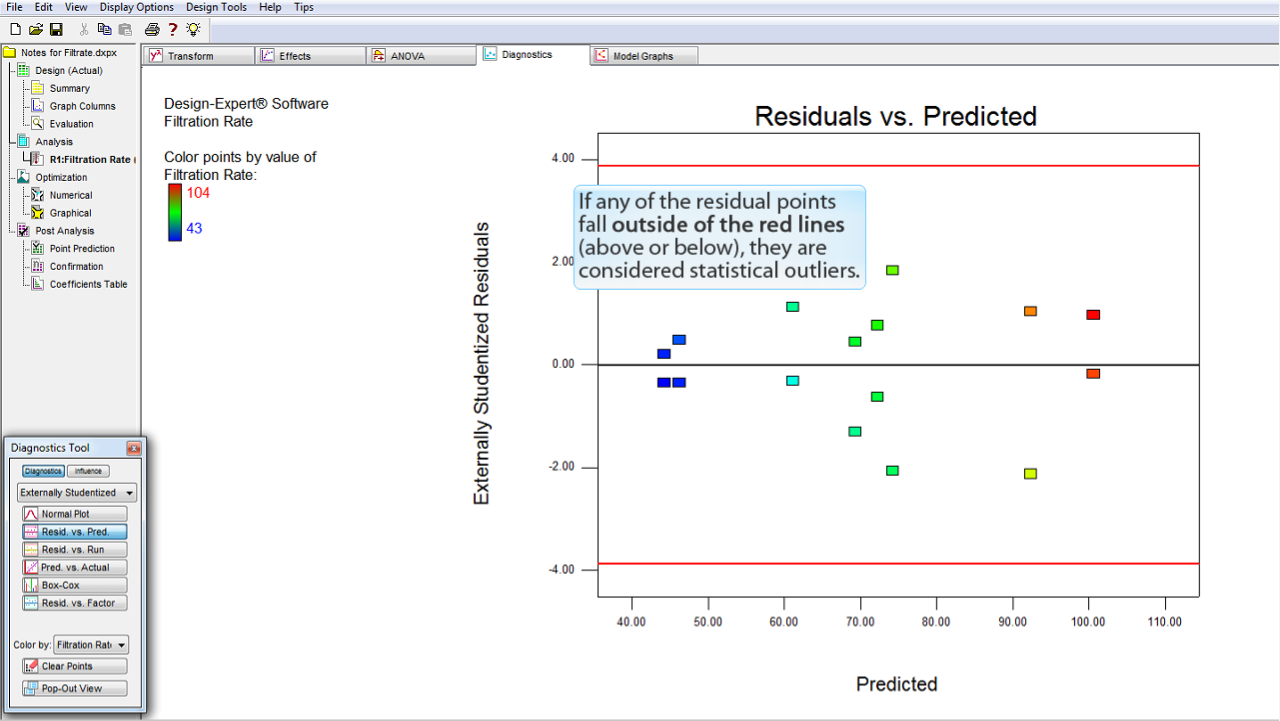
このプロットは、外れ値 (outlier) のチェックに利用することもできます。プロット上の赤のラインに注目してください。
残差の点が赤のラインより外側 (上側または下側) にあれば、それらは統計的な外れ値であると考えられます。
この事例では、問題はありませんので、次に進むことができます。もし何らかの問題があれば、モデルを分析しなおすか、数学的変換 (transformation) を使用する必要があるかも知れません。
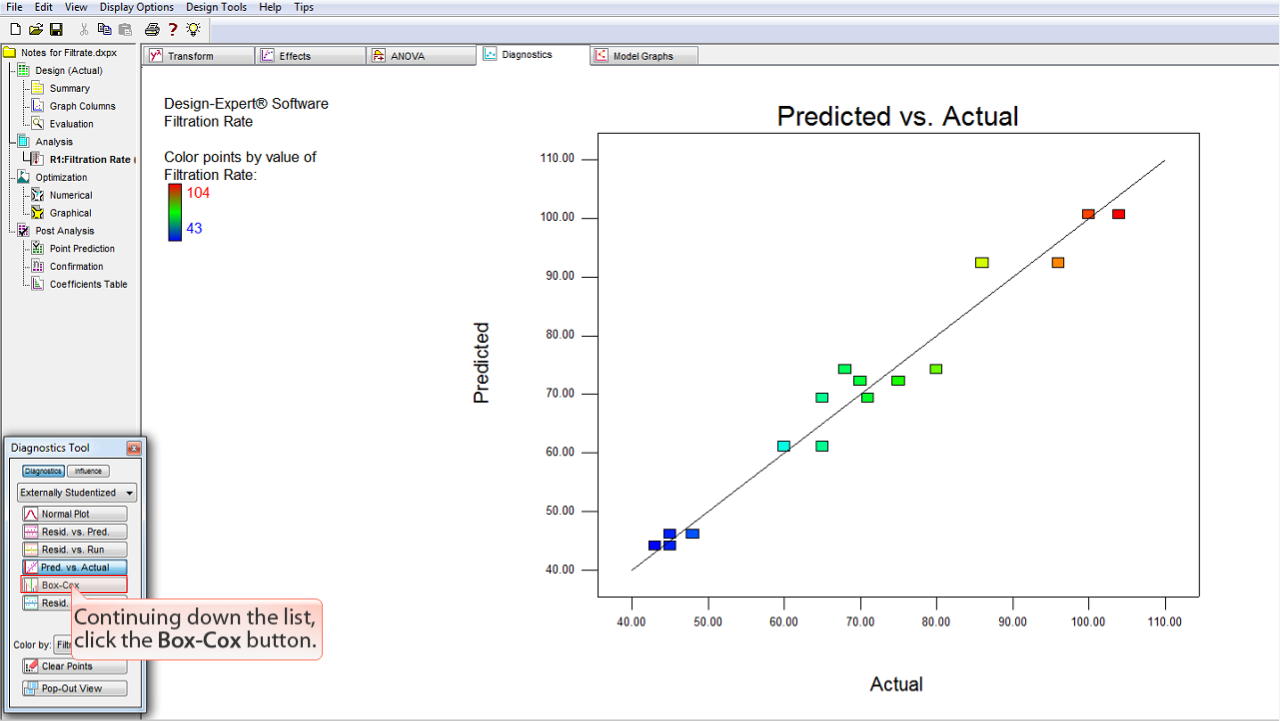
引き続き、リストの下に進んでいきましょう。Resid. vs. Run は飛ばして、
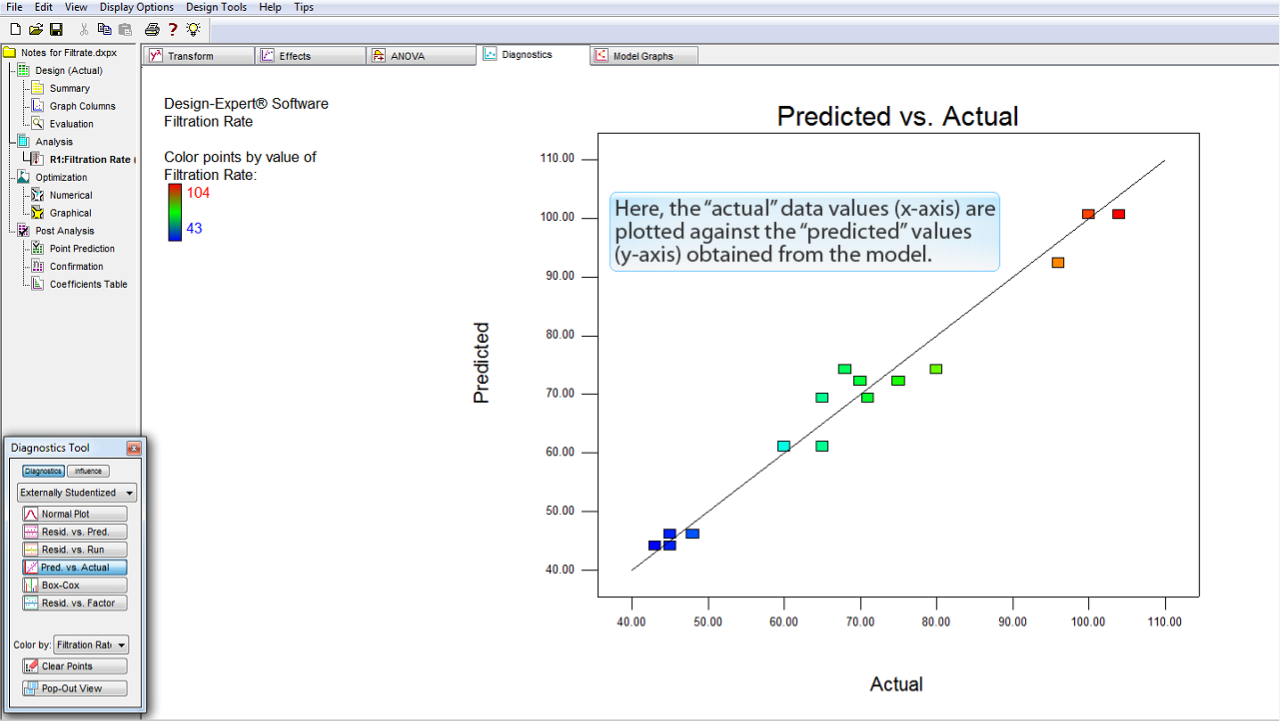
Resd. vs. Actual
ボタンをクリックします。
ここには、モデルから得られる予測値 "predicted" (Y 軸) に対する実際のデータ値 "actual" (X 軸) がプロットされています。
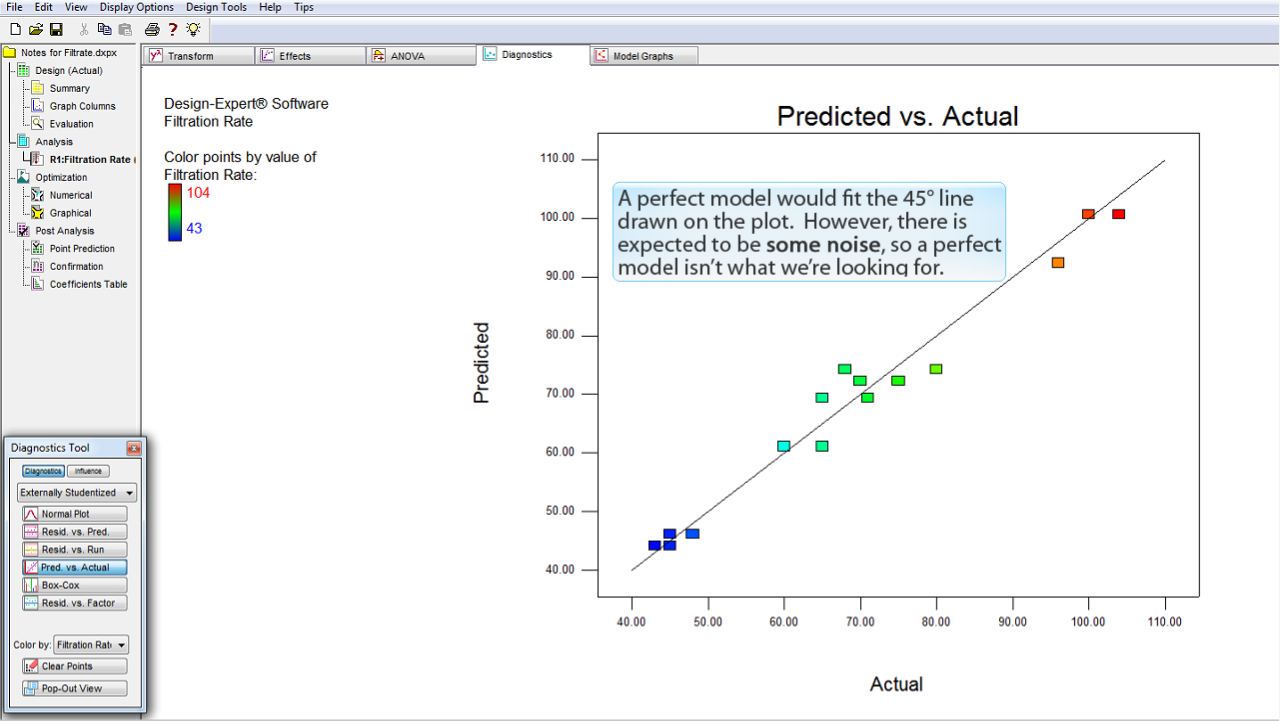
完璧なモデルであれば、プロットにあてはまる直線は45度になります。しかし、多かれ少なかれノイズの存在を見込んでいるため、我々が期待するのは完璧なモデルではありません。
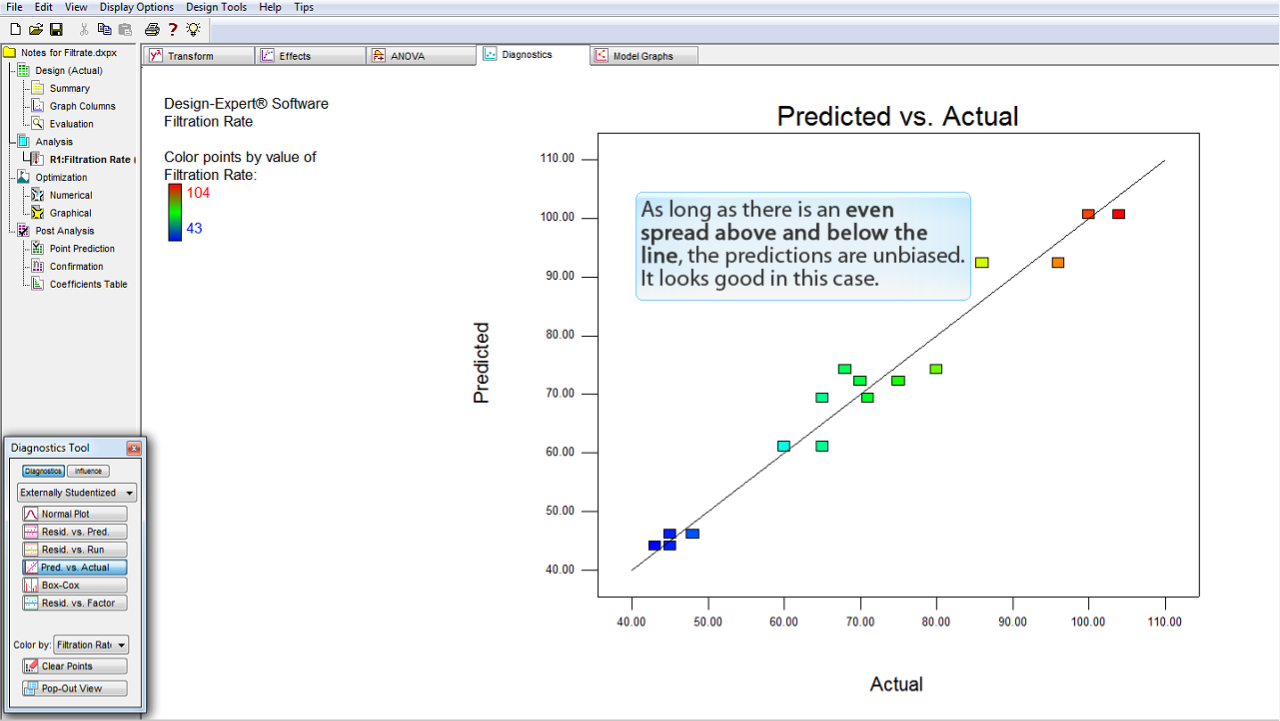
直線の上下に広がりが等しく存在するので、この予測は偏りのないもの (unbiased) です。この事例には問題はないと考えられます。
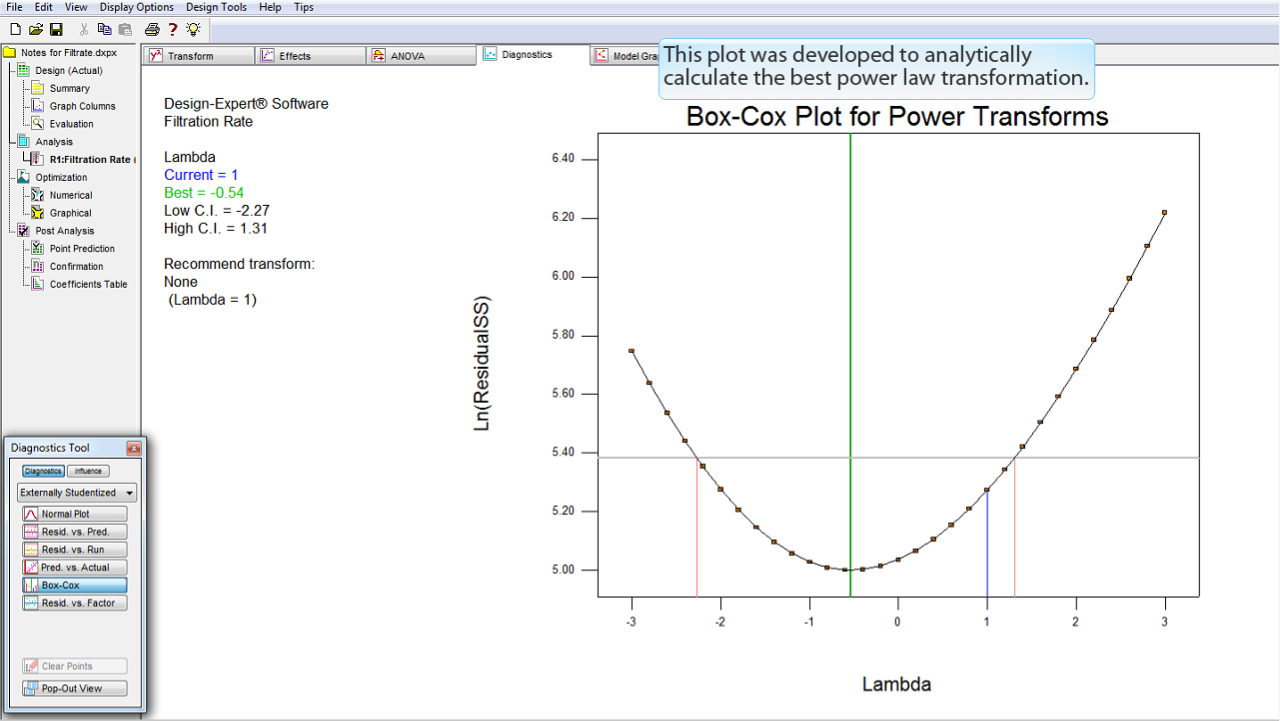
リストを更に下へ進み、
Box-Cox
ボタンをクリックします。
このプロットは、最適なべき乗則変換を解析的に計算するために開発されたものです。
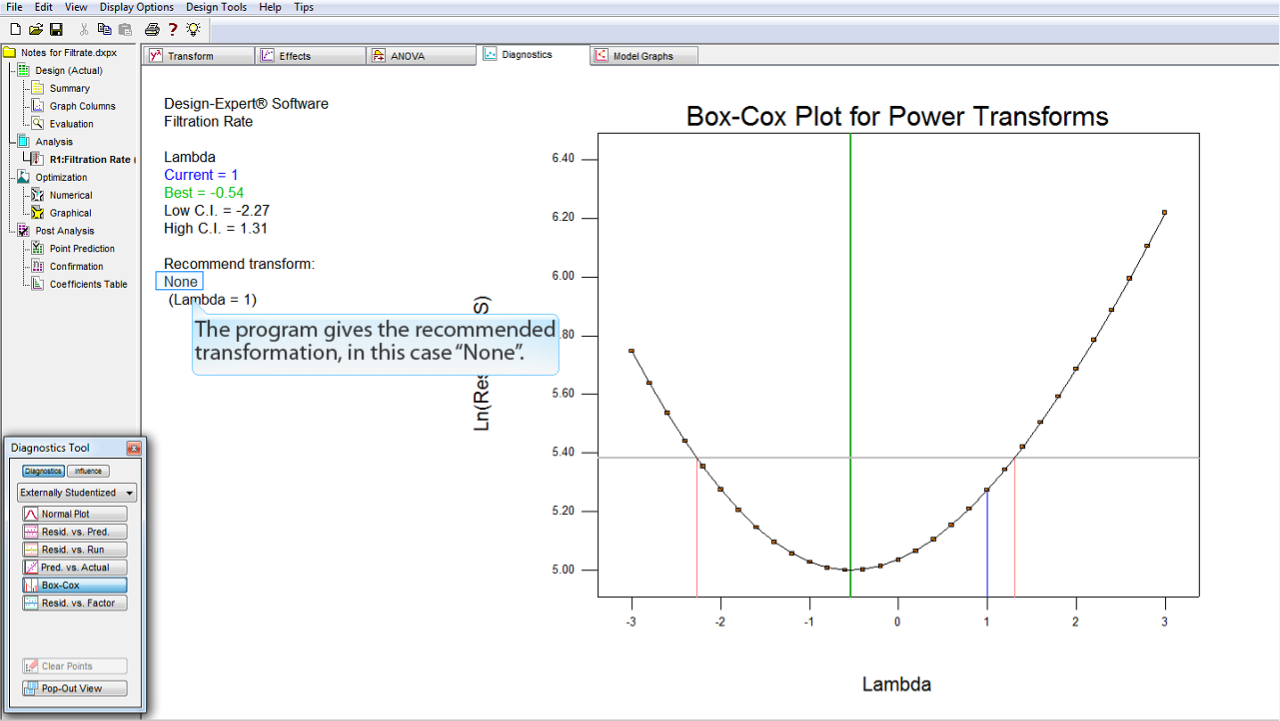
プログラムによって推奨される変換がここに表示されます。この事例では "None" (なし) と表示されます。
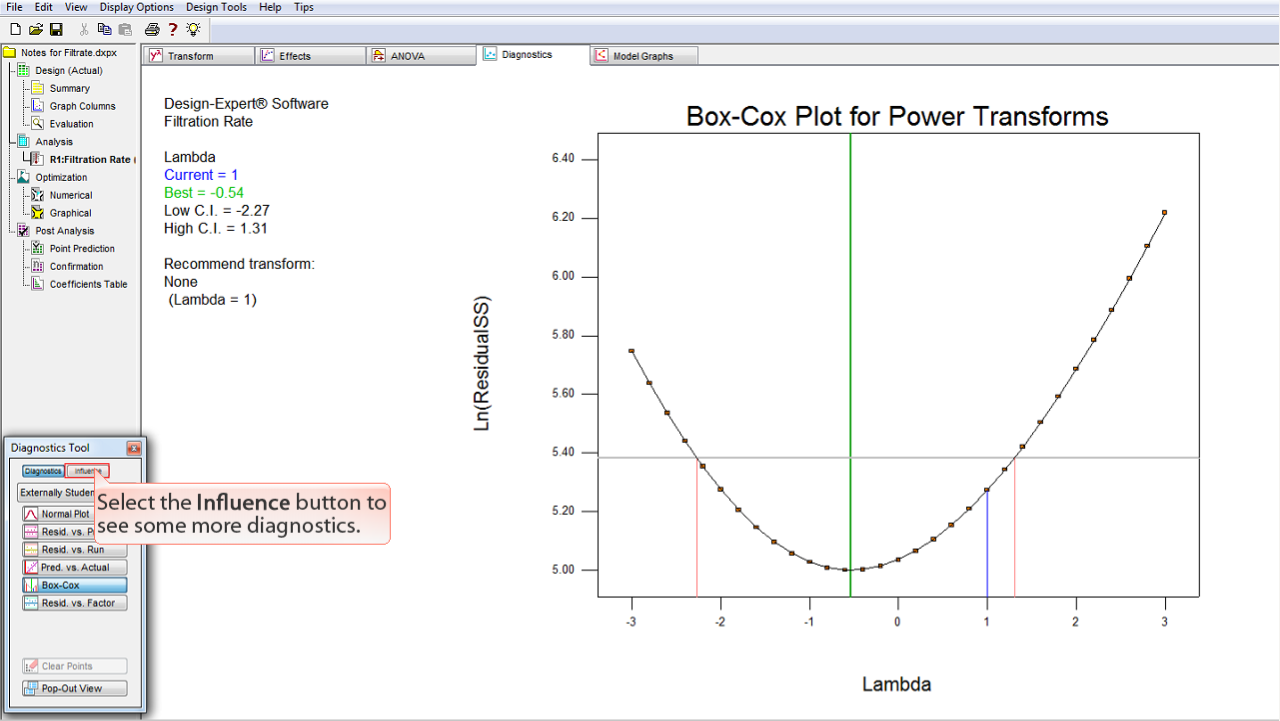
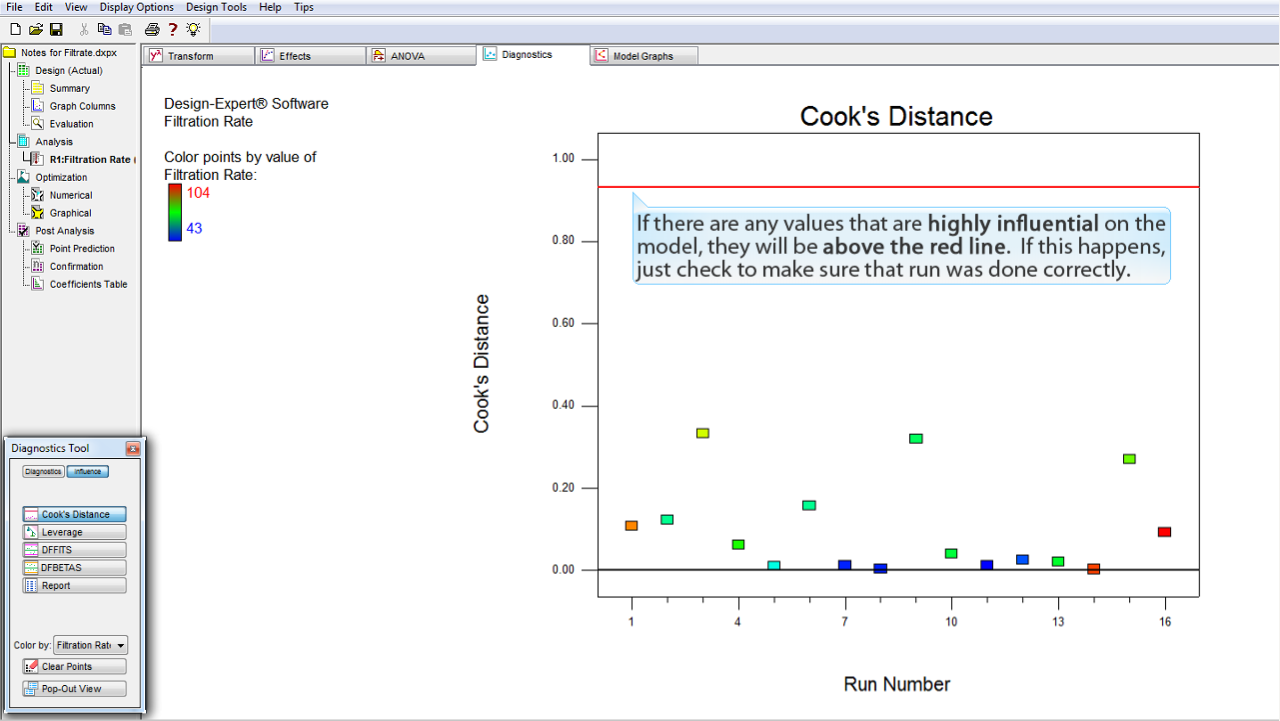
Influence
ボタンを選択して、さらにいくつかの診断を確認してみましょう。
もし、影響力の非常に大きな (
highly influential
) 値がモデルに存在すれば、それらはこの
赤の直線より上
になります。もしそれが存在したら、その実験が正しく行われたかどうかを必ずチェックしてください。
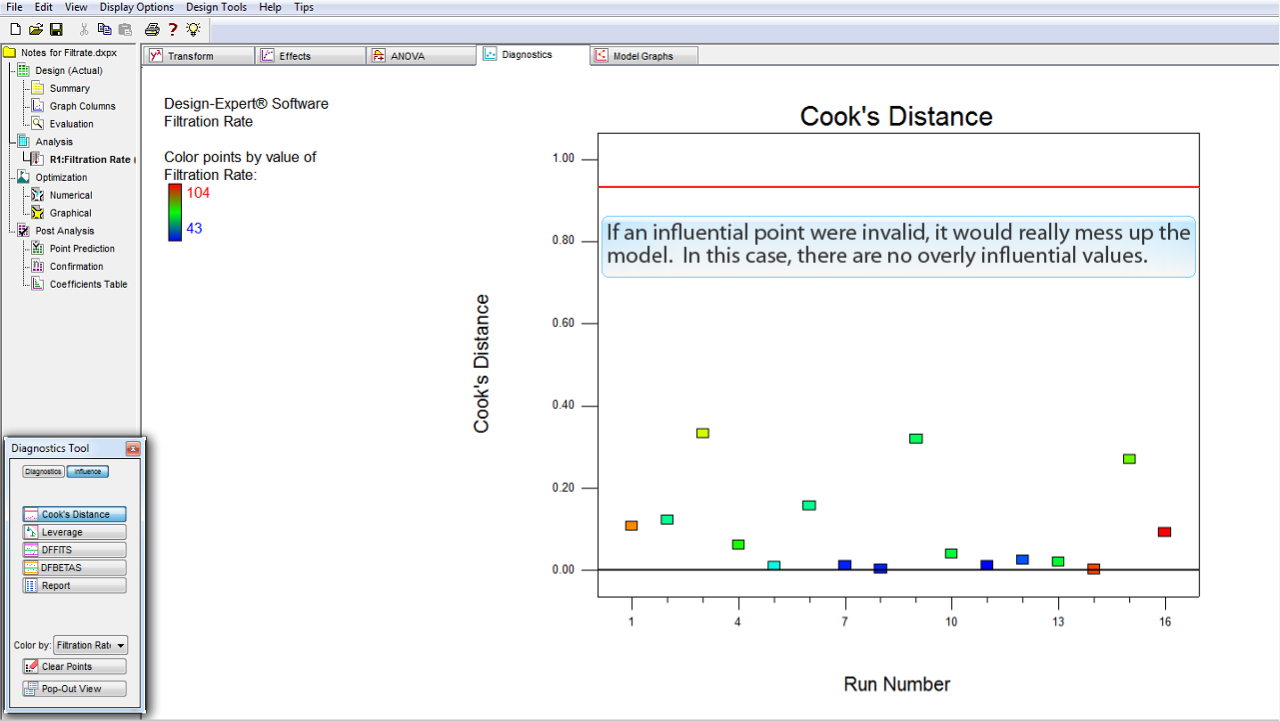
もし、影響力の大きい点が不正なものであれば、それによってモデルが台無しにされてしまう可能性があります。この事例では、影響力の極端に大きな値は存在していません。
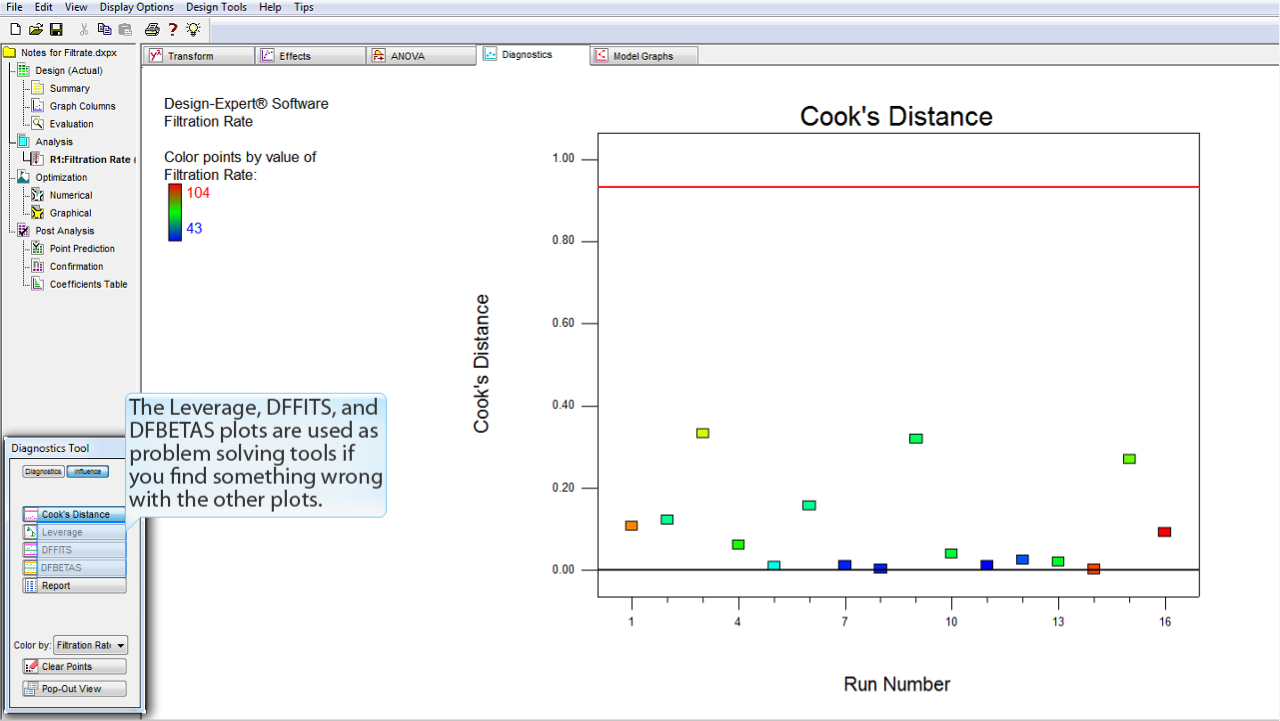
Leverage, DFFITS, DFBETAS の各プロットは、他のプロットに問題が見つかった場合にそれを解決するツールとして使用します。
ここでは何ら問題は見つかっていませんので、いずれもスキップすることにします。
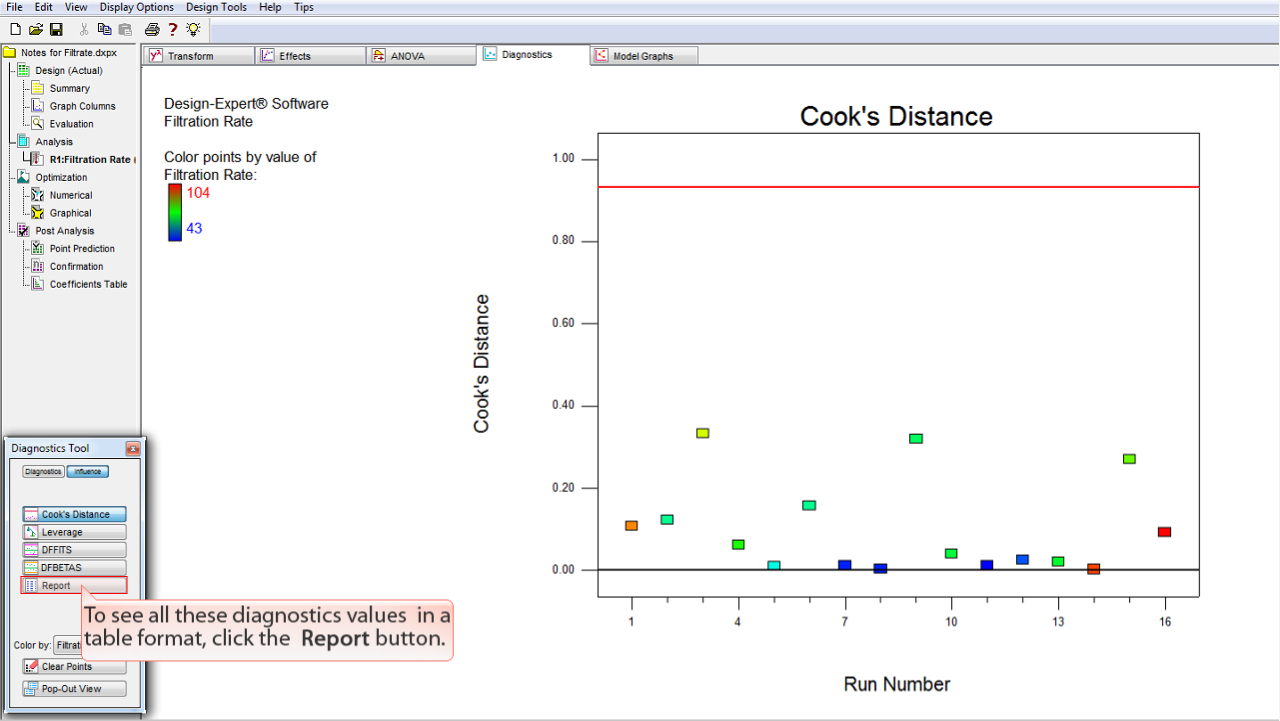
これら全ての診断の値をテーブル形式で調べる場合には、
Report
ボタンをクリックします。
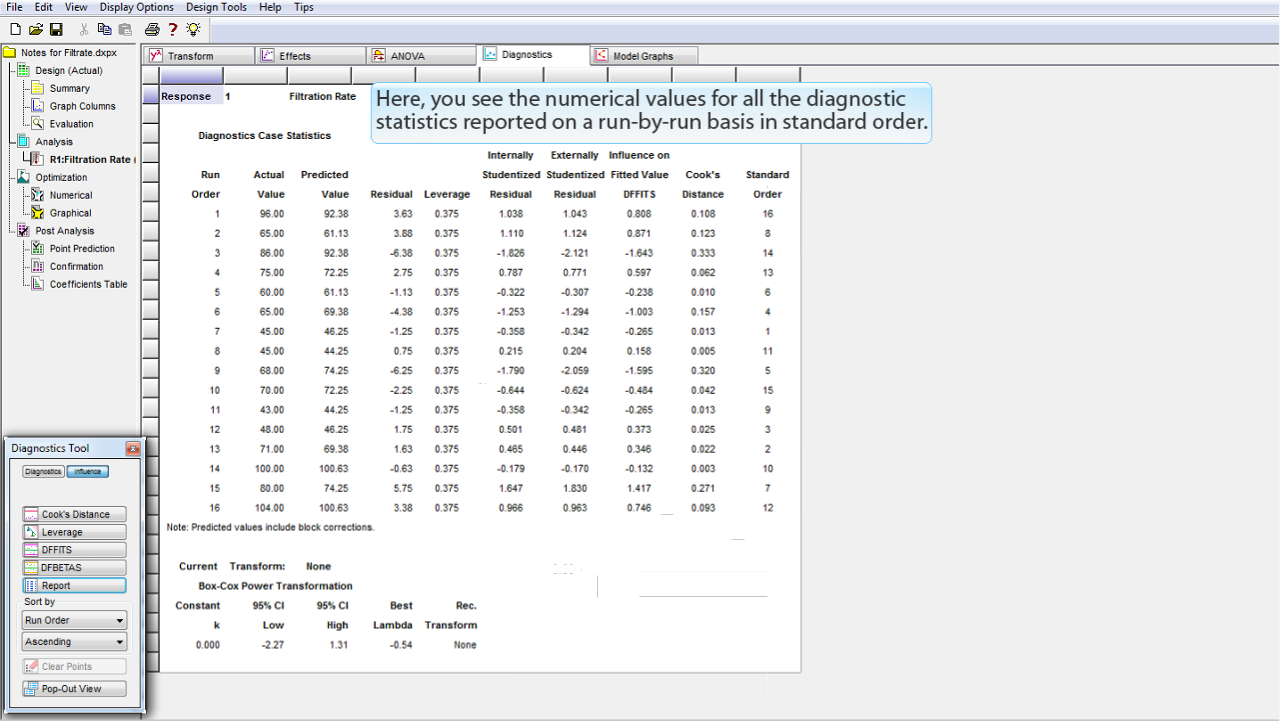
ここでは、レポートされる全ての診断統計の数値を、標準的順序 (standard order) の試行毎に確認することができます。
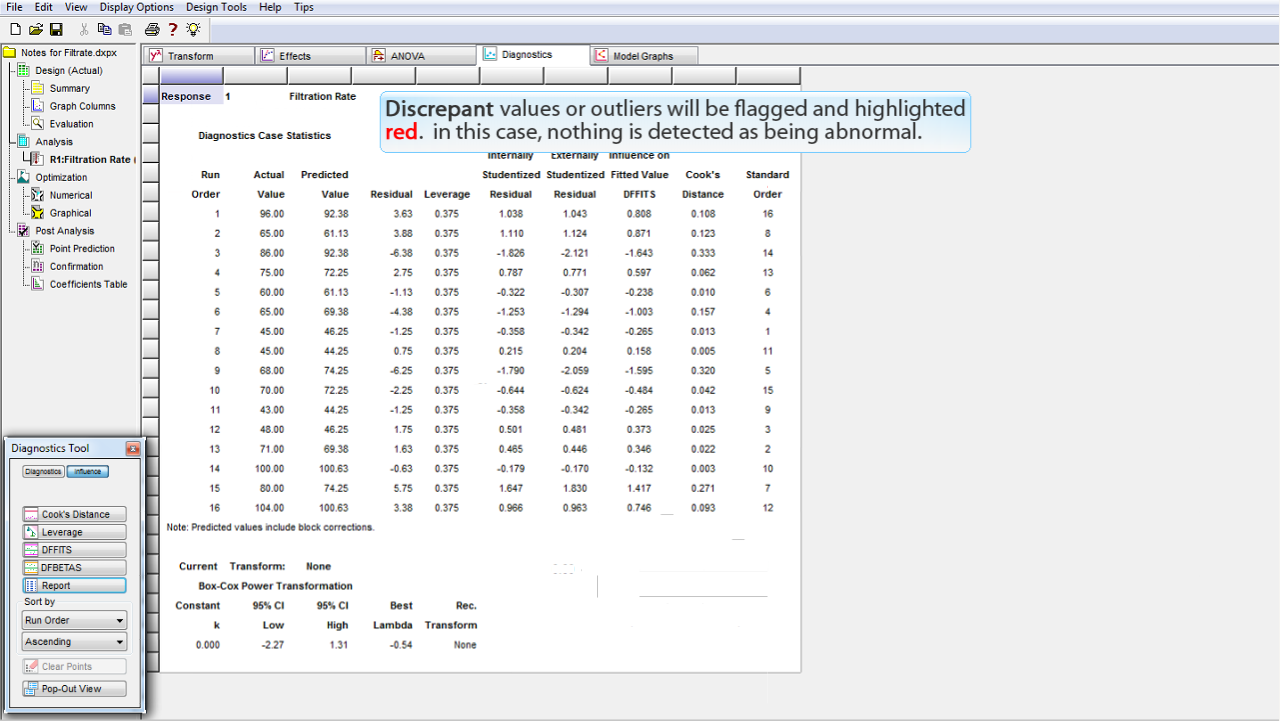
不具合のある値や外れ値には、フラッグが付いて赤字で強調表示されます。この事例には、異常と認められた値はありません。
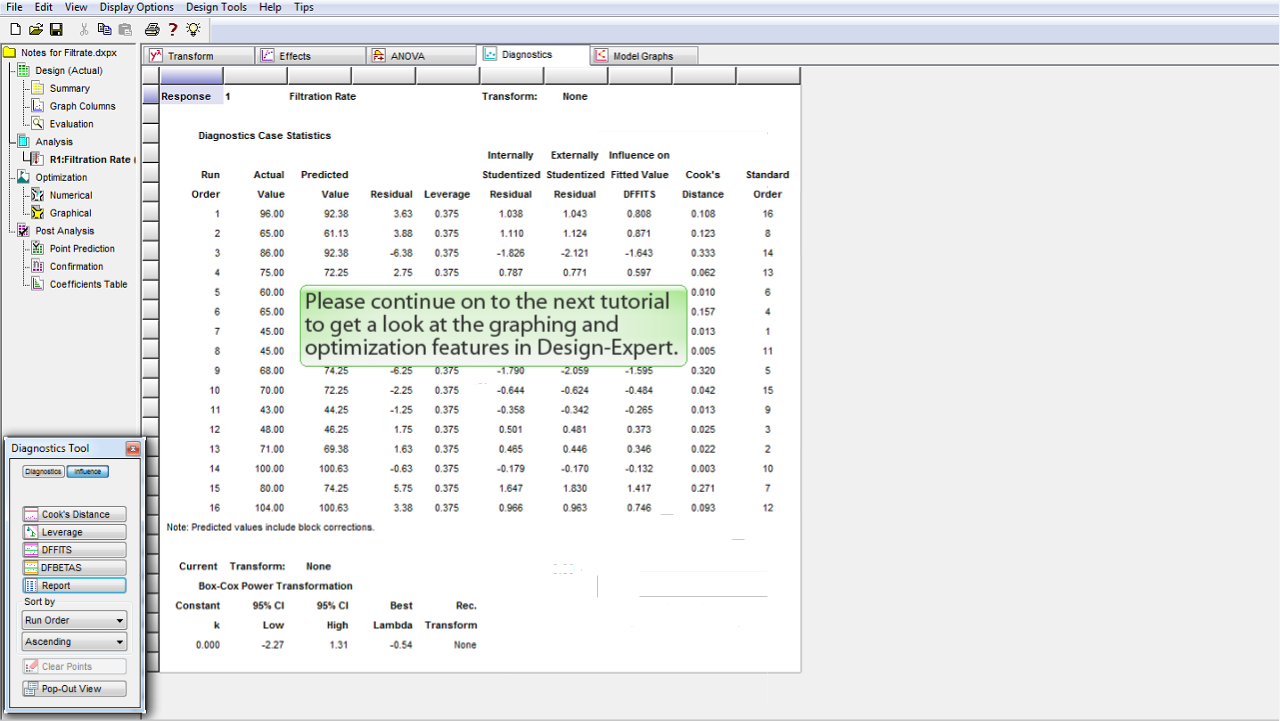
次のチュートリアルにお進みください。Design-Expert のグラフ作成および最適化機能が紹介されています。