|
| サイトマップ | |
||
|
| サイトマップ | |
||
| UNISTAT サポート情報 |
Parallel Line Method (平行線法) で分析できるのは、釣合い型 (Balanced)、対称型 (symmetric) あるいは非釣合い型 (unbalanced) のアッセイです。分析は、投与量変数の自然対数に対する、反応変数の回帰を基にしています。別々の線が各プレパレーション上にフィットしますが、それらは平行でなければなりません。アッセイは次の場合に釣り合います:
最初の2つの条件は満たすが、異なるプレパレーションで異なる投与レベル (継続的な投与レベルの比は同じ) のアッセイは、対称型と呼ばれます。これらの条件の1つ以上を満たさないアッセイは非対称型あるいは非釣合い型と呼ばれます。
有効性検定のために、次の分散分析 (ANOVA) オプションを使用できます:
非釣合いなアッセイは完全無作為配置 (Completely Randomised Design) オプションでのみ分析できます。他のオプションはすべて対称型か釣合い型アッセイが必要です。ほとんどの場合にプログラムは、アッセイが非釣合いか対称か釣合いかを検出し、適切なアルゴリズムを自動的に適用します。
European Pharmacopoeia (1997-2008) の平行線法に準拠して分析されるこのデータセットは、釣合い型になります。
データは通常表の形式で与えられ、そこでは、測定値はプレパレーションにより異なり、投与レベルは別々のコラム (たとえば投与群) で表示されます。 次に例を示します:
標準は常に最初のプレパレーションです。
次の 3-投与 / 2-プレパレーションの例を考えます。ここでは h=2、k=6、n=4、投与レベルが 0.125, 0.25 および 0.5 として与えられるとします。
| Cases | Preparations | |||||
|---|---|---|---|---|---|---|
| Standard | Unknown | |||||
| Dose1 | Dose2 | Dose3 | Dose1 | Dose2 | Dose3 | |
| 1 | 1.3 | 2.1 | 4.1 | 1.5 | 2.0 | 3.9 |
| 2 | 1.7 | 2.3 | 4.2 | 1.1 | 1.9 | 4.6 |
| 3 | 1.1 | 2.7 | 3.9 | 0.9 | 2.1 | 4.0 |
| 4 | 1.5 | 2.2 | 4.3 | 1.0 | 2.2 | 3.7 |
これはバイオアッセイのため十分に定義されたデータセットですが、まず、統計ソフトを使って分析に適したフォーマットに変換する必要があります。これはすべての対応する測定値を単一コラムにスタックすることにより実行できます。この場合、どの測定値がどのプレパレ-ション、どの投与グループ、どの処理事例に属するかを追跡できるように、分類別のデータコラム (因子と呼ぶ) を作成する必要があります。
UNISTAT で分析するには、上の例のデータは次のように UNISTAT スプレッドシートに入力する必要があります:
| Data | Dose | Preparation | Rows | Columns |
|---|---|---|---|---|
| 1.3 | .125 | Standard | 1 | 1 |
| 1.7 | .125 | Standard | 2 | 1 |
| 1.1 | .125 | Standard | 3 | 1 |
| 1.5 | .125 | Standard | 4 | 1 |
| 2.1 | .25 | Standard | 1 | 2 |
| 2.3 | .25 | Standard | 2 | 2 |
| 2.7 | .25 | Standard | 3 | 2 |
| 2.2 | .25 | Standard | 4 | 2 |
| 4.1 | .5 | Standard | 1 | 3 |
| 4.2 | .5 | Standard | 2 | 3 |
| 3.9 | .5 | Standard | 3 | 3 |
| 4.3 | .5 | Standard | 4 | 3 |
| 1.5 | .125 | Unknown | 1 | 4 |
| 1.1 | .125 | Unknown | 2 | 4 |
| 0.9 | .125 | Unknown | 3 | 4 |
| 1.0 | .125 | Unknown | 4 | 4 |
| 2.0 | .25 | Unknown | 1 | 5 |
| 1.9 | .25 | Unknown | 2 | 5 |
| 2.1 | .25 | Unknown | 3 | 5 |
| 2.2 | .25 | Unknown | 4 | 5 |
| 3.9 | .5 | Unknown | 1 | 6 |
| 4.6 | .5 | Unknown | 2 | 6 |
| 4.0 | .5 | Unknown | 3 | 6 |
| 3.7 | .5 | Unknown | 4 | 6 |
Does の列が投与グループの数ではなく、すべてのプレパレーションの実際の投与単位であることに注意してください。この情報は Potency と Treatment Means オプションの Plot に必要です。また Rows の列は Randomised Block without Replication、Latin Squares Design および Crossover Design に必要で、Columns の列は Latin Squares Design および Crossover Design に必要です。スタンドアロンモードでは、Rows と Columns の変数はそれぞれ、UNISTAT スプレッドシート関数の Level (4) と Level (4); B により作成できます。
上記で説明したようにデータが変換されたなら、UNISTAT メニューの Add-ins => Bioassay => Parallel Line Method を選択します。次のような設定ダイアログが現われます。
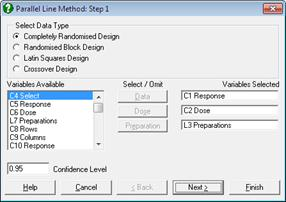
選択するデータ列変数が左のリストに現われます。変数は、データの種類を表わす一文字が接頭辞としてついている列数により指摘されます。たとえば、上の C1, C2 および C4 は数値の列で、一方 L3 は列 3 が長い文字列を含んでいるということです。短い文字列 (8 文字まで) を含む列の接尾辞は (S) です。また、データの種類でおそらくバイオアッセイに使用されないものに日付 (D) と時刻 (T) があります。もしラベルが入力されているなら、それらは列数の次に表示されます。
「Select Data Type (一番上)」は、実行する分散分析の種類を表示します。選択する変数の数が分析の種類により異なることに注意してください。たとえば 2番目のオプション Randomised Block Design を選択すると、4つの変数が必要になります。
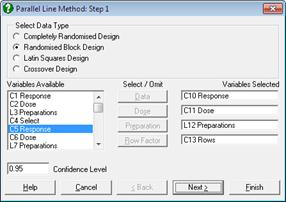
3番目と4番目のオプション Latin Squares Design と Crossover Design は5つの変数を選択する必要があります。
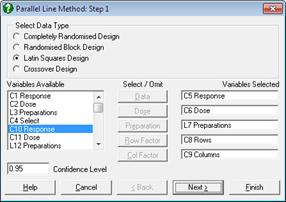
分析の種類を選択したあと、それらの変数を右側のボックスへ送ることにより、タスクを割り当てることができます。これを行うには、左のリストで変数を強調表示し、希望するタスクのボタンをクリックします。同様に、右のリストで変数を強調表示してこのボタンをクリックすると、すでに選択された変数が削除されます。
すべての変数を選択したあと、[Next] ボタンをクリックしてアウトプットオプションダイアログに進みます。
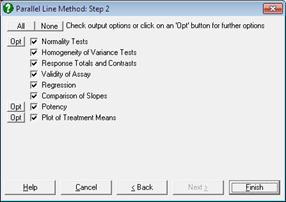
アウトプットオプションには次の8つがあります。希望するアウトプットのオプションをチェックし、[Finish] ボタンをクリックすると、アウトプットが表示されます。
ここで分散分析法を基にした5つの例を再現します。データセットは UNISTAT のスプレッドシートに手動で入力され、必要なデータ操作が様々な UNISTAT のスプレッドシート関数により施されました。最終的なデータセットは European Pharmacopoeia (1997) からの例を含む BIOPHARMA と Finney (1978) からの例を含む BIOFINNEY という2つのファイルに保存されました。
| ※ バイオアッセイの分析にはオプションモジュール Analysis of Bioassays が必要です。 |