|
| サイトマップ | |
||
|
| サイトマップ | |
||
(2022/09/16 の Tecplot 社ブログより)
我々 Tecplot 社は、ポスト処理に関していくつかの選択肢があること、また、お客様にとって時間が重要であることを理解しています。そこで、どのポスト処理ツールがお客様のデータの処理で最高のパフォーマンスを発揮するかを決定するために、いくつかのパフォーマンステストを実施しました。
もちろん、性能はいくつかの要因に左右され、どのようなデータを使用するかが重要な要素となります。本投稿では、CONVERGE データのみを使用した場合のパフォーマンスについて説明します。
CONVERGE ユーザーは、CONVERGE ライセンスの一部として「Tecplot for CONVERGE」 (TfC) を使用することができます。ただし、TfC が提供するもの以上のもの(バッチ処理など)を探しているユーザーにとって、Tecplot 360 または ParaView は最も一般的な選択肢となります。
TfC、360、および ParaView には、それぞれ CONVERGE post*.h5 ファイルを直接読み込めるデータ リーダーが含まれています。つまり、これらのポスト プロセッサでは、post_convert を実行する必要はありません。post_convert を実行せずに直接読み込むことで、時間とディスク容量を節約できます。
多くの CONVERGE ユーザーは計算結果の動画を作成する必要があるため、かなり大規模なマルチサイクル内燃エンジン (ICE) シミュレーションのデータセットを選択しました。このデータセットは 1278 のタイムステップで構成され、ディスク上で合計 169GB になります。
目標は、温度で色分けされたスライスと火炎面(温度 = 1700)の等値面で構成されるプロットを作成するために必要な実行時間と要求される RAM 容量のピーク値を取得することです。この操作を一連のデータのタイムステップごとに繰り返し、合計 1278 枚の画像を作成しました。図 1 に、プロットの例を示します。
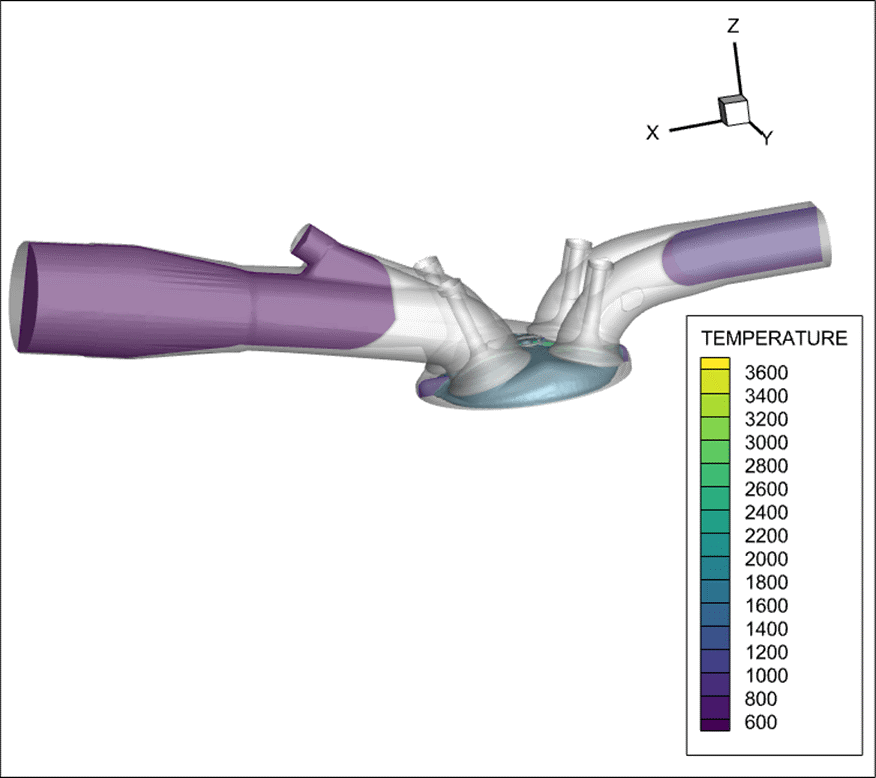
図1: ICE のシミュレーション例 温度と火炎面の等値面
32 の論理コア、128GB RAM、そして NVIDIA Quadro K4000 グラフィックカードを擁するWindows 10 マシンを用いて実験を行いました。ネットワークトラフィックの遅延を防ぐために、データはローカルの HDD に保存されています。
全てのテストはバッチ処理で行い(Tecplot360 では PyTecplot, ParaView 5.10 では pvbatch を使用しました。)、時刻と RAM 情報の取得のために Python memory-profiler ユーティリティーを使用しました。
図2: Tecplot 360 Image Exportsで作成されたICE シミュレーションの動画
(動画の再生速度とファイルサイズを考慮し、動画作成には4画像毎のものを使用しました。)
次の図は処理を直列で実行した実験結果を示しています(一度に1画像を作成)。
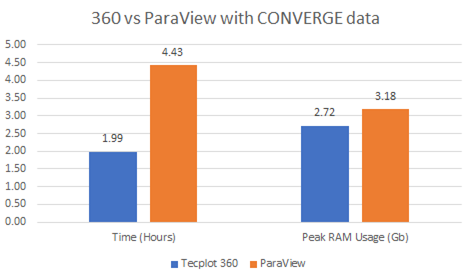
図3:360 vs ParaView 実行時間と要求される RAM 容量のピーク値
PyTecplot スクリプトに関しては我々の GitHub を確認してください。
作成されたプロットについては、Tecplot 360 は、node-located の値から cell-centered の温度データの導出(等値面作成のための必須条件)、スライスの作成、等値面の作成のような多くの操作を実行するのにマルチスレッディングを行っています。
ParaView に関しては、どのフィルターがマルチスレッドであるかのリストを公開していませんが、"一般的なフィルターはすべて [マルチスレッド]"です[1,2]。
ここで直列は、一連の CONVERGE post*.h5 をロードし、アニメーションを走らせ、1 タイムステップずつ画像を作成することを意味します。
HDF5 データセットの性能テストについては、Tecplot 360 の最小メモリモードで処理すると、1.99 時間(1 画像当たり~5.6 秒)と最速で処理できることがわかりました。Tecplot 360 の最小メモリモードでは、ピーク時の RAM 使用量が 2.7GB と最も少なくなっています。なお、Tecplot 360 は、再レンダリングが必要な場合に備えて、読み込んだデータの 30‐70% を RAM に保持することがデフォルトになっています。一度、RAM が 70% の閾値を満たすと、Tecplot 360 は RAM にあるデータを容量が 30% になるまでオフロードします。この動作は、GUI でタイムステップ間を行き来する際に便利です。なお、Tecplot 360 を最小メモリモードに設定すると、以前のタイムステップのデータを RAM に保存することができなくなります。
ParaView を MPI を用いて実行していますか?- 現在推奨されることは、データの分散処理ができる時のみ、ParaView を MPI を用いて実行することです[3]。CONVERGE のデータはシングルブロックであるため、分散処理をすることは理想的ではありません。更に言うと、ParaView の CONVERGE リーダーは並列でデータを読み込みません[4]。それ故に、ParaView は MPI を用いて実行していません。
その他の PyTecplot (バッチモード) の利点は、画像エクスポートスクリプトを複数 PyTecplot 処理で同時に行うよう記述でき、画像の処理にかかる時間を短縮することができることです。複数のタイムステップを同時に処理する PyTecplot スクリプト ParallelImageCreator.py(GitHub にあります - サンプルはドキュメントを参照)を利用して、より多くのコアを動作させることができました。以下のプロットでは、たった2つの同時処理でも処理時間が劇的に短縮されることがわかります。
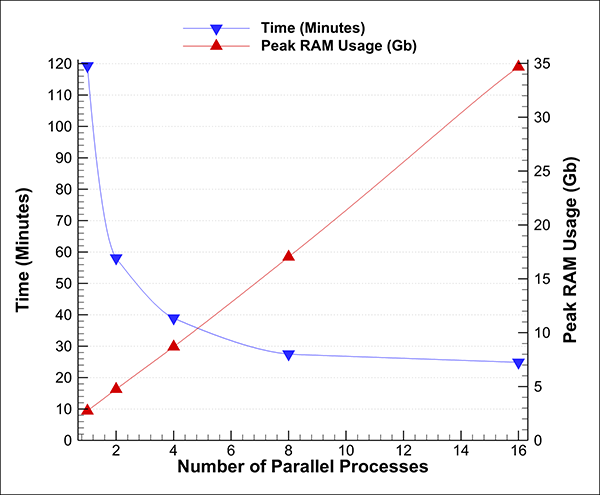
図4:実行に要する総時間、RAM 使用量のピークと並列プロセス数の関係
16 コアで実行されるスクリプトは1画像に要する時間を~1.2秒ほどであり、イメージエクスポートを並列化なしで Tecplot 360 で実行した最も速いケースの 4.8 倍の速さであり、ParaView の 10.7 倍の速さとなります。しかし、これは RAM の観点からは大きな犠牲をはらっています (34.7GB vs 2.74GB、12.6 倍のRAM)。8 プロセッサと 16 プロセッサで並列処理を行った場合を比較した結果、半分の RAM でほぼ同じ速度が得られることが確認されました。並列処理ではハードウェアの競合が発生する可能性があるため(これがパフォーマンスの直線的な向上が見られない理由です。)、使用するデータで実験して、理想的な並列処理量を見つける必要があるかもしれません。
画像を作成しましたら、エクスポートした画像を繋ぎ合わせることができる ImageMagic、FFmpeg (Tecplot360 に付属している実行プログラム) などのツールを利用することをお薦めします。様々な種類の動画ファイル、.mp4, .gif, .avi で作成でき、フレームレートを調整することなども可能です。また、GitHub にあるスクリプトを利用して Python でプロセスを自動化することもできます。
このように、Tecplot 360 のバッチモードでは、1 ライセンスシートであれば高速にアニメーションを作成でき、マルチコアにより、さらに高速に画像を作成できます。方法について相談されたい場合は、私たちにお知らせください。実行されている画像の処理をパワーアップさせます。
参考:
[1] https://discourse.paraview.org/t/paraview-parallel/320/9
[2] https://discourse.paraview.org/t/make-paraview-multicore-gpu/5723/2
[3] https://discourse.paraview.org/t/paraview-parallel/320/13
[4] https://discourse.paraview.org/t/a-problem-of-parallel-processing-in-paraview/5089/7