|
| サイトマップ | |
||
|
| サイトマップ | |
||
グローバルフィッティング (複数応答の非線形回帰) とは、単一または複数のデータセットに対して単一または複数の当てはめモデルを同時に当てはめる処理です。これは通常の非線形最小2乗回帰を一般化したものですが、SigmaPlot でこの一般問題をいかにして取り扱うかは後ほど具体的に説明することにします。そこではトランスフォーム言語の特別な構成要素と非線形回帰ウィザード (Nonlinear Regression Wizard) を使用します。
グローバルフィット問題を準備するために、ここでは、単一または複数の独立変数とそれに対応する単一の従属変数の値で構成されるデータが複数セットあると仮定します。従属変数の値は、調査で得られた観測値です。これらは一般に測定誤差 (measurement error) による影響を受けます。当てはめモデルはデータセット毎に選びますが、このとき当てはめモデルの一部または全ての間で共有 (share) する回帰パラメーターを少なくとも1つ選択します。パラメーターを共有しなれば、グローバルフィッティングではなく、当てはめモデルを個々のデータセットごとに(ローカルに)使用する通常の非線形回帰になります。
グローバルフィッティングで使用する最適化問題は、通常の最小2乗回帰と同様、平方和 (SS) が最小になるようなパラメータ値を求めることです。ただし、この事例では、観測値とそれに対応する当てはめモデルの値との差に関する平方和をデータセットごとに作成した後、データセット全体に関する平方和を追加します。
平方和を考えるこの方法は、複数のデータセットを全て1つにつなぎ合わせたあと、データポイントの各値が、それの属する各データセットに関する当てはめモデルの値となるようなグローバルフィットモデルを使用するのと同じことです。その後、全てのデータセットの全てのデータについて1つの平方和を考慮します。
このグローバルフィットモデルを使うことで (数学的詳細は下記参照) 、この問題を通常の非線形回帰問題として解釈し、すべての回帰問題と同様に best-fit パラメータ、予測値と残差、診断、各種統計量を求め、分析を行うことができます。また、データセット毎に算出した局所的な結果も求めることができます。例えば、平方和や決定係数 R2 などの goodness of fit (当てはまりの良さ) をローカル (データセット毎) に測定し、データセット毎に当てはまり具合を判断することができます。
SigmaPlot には Global Fit Wizard が用意されています。以下のような制約はありますがグローバルフィット問題を解くのに役立てることができます。
このウィザードを使って、当てはめに使用するモデルと使用するデータのフォーマット、使用するデータ、共有パラメーターをそれぞれ選択し、その結果を計算することができます。レポートに表示される結果のほとんどはグローバルです。すなわち、全データセットを同時に当てはめることで上で説明した当てはめ問題を計算した結果です。また、データセット毎に算出したローカルな結果もあります。計算に関する詳しい情報については、以下のセクションをご覧ください。
Global Fit Wizard を使って解くグローバルフィット型の問題の例として、この問題をパラメータ数が4つ、独立変数が1つからなる方程式群に基づくものと仮定します:
もし、モデル化するデータセットが3つあるとすれば、該当するグローバルカーブフィット問題には1データセット当たり4つのパラメータがあることから、最大で 12 個のパラメータがあることになります。パラメータが全てのデータセットで共有されるとすれば、このグローバルカーブフィット問題のパラメータは最小の4つになります。
データセット1、2、3がパラメータ c を共有し、その他のパラメータ y0, a ,b は、データセット毎にそれぞれ独立して変化させることにしましょう。このケースの場合、グローバルフィットモデルの独立したパラメータは 10 個となり、次式であらわされます:
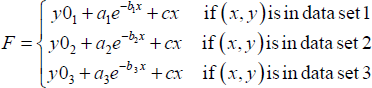 |
これが、SigmaPlot で定式化されるグローバルフィットモデルです。これらのパラメータの真の値 (各観測値 y とモデル F の対応する値とが等しくなるようなパラメータの値) を求めることが最終目的です。これらのパラメータの (一致) 推定量は、通常の非線形回帰問題で使用するのと同じアルゴリズムに従う最小2乗最適化 (least-squares optimization) で求めます。同様に、グローバルフィットのレポート結果は、通常の非線形回帰で使用するアルゴリズムと同じ手続きに従って求めます。
SigmaPlot のグローバルフィットレポートでは、各データセットに関する出力結果の表示に際して、各パラメータの表記に上記に示すようなインデックス値は使用されません。レポートでは、オリジナルのパラメータ名が使用されます。インデックス値による混乱を避け、グローバルフィットの問題設定を分かりやすくするためです。
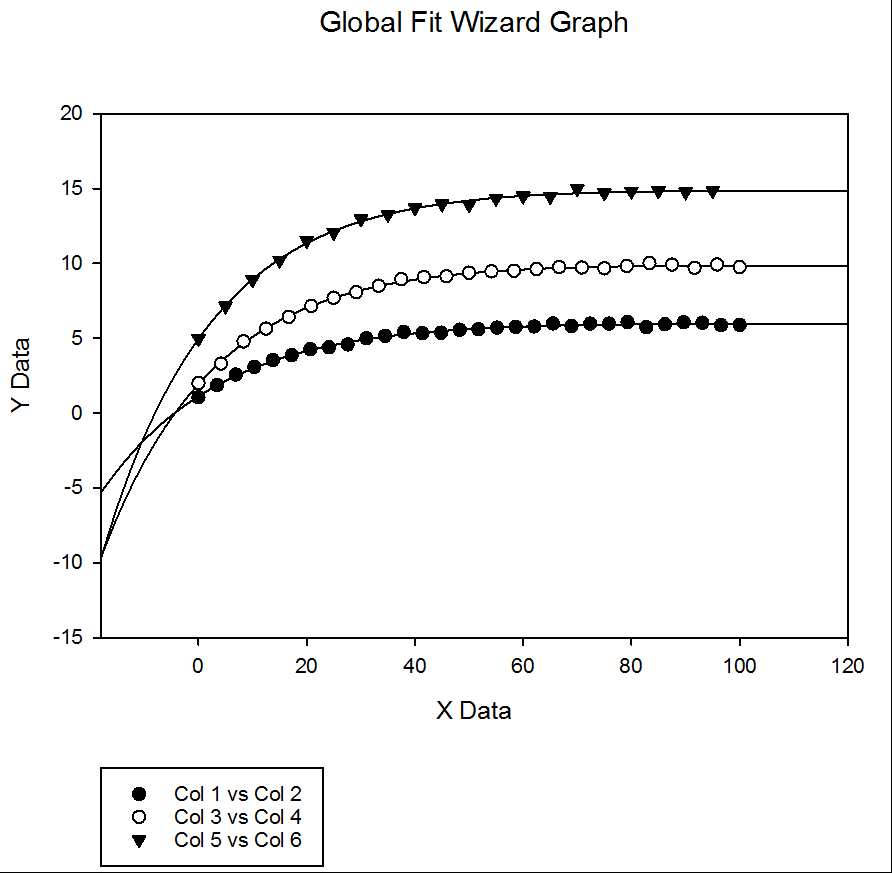
この例を Global Fit Wizard で実行する際は、まずはじめに Equation Name (方程式名) を選択します。このケースの場合は、Exponential Decay (指数的減衰) の Exponential Linear Combination を選択します。次に、Shared Parameters (共有パラメータ) を選択します。この場合は c です。最後に、使用するデータのフォーマットを選択したあとそのデータを選択します。データフォーマットには XY Pairs を選択し、具体的なデータセットを選択します。この問題では、データセット1が列1と列2に、データセット2が列3と列4に、データセット3が列5と列6にあります。グローバル回帰を実行すると、レポートの生成に続いて、以下に示すようにデータセット毎にカーブフィットのグラフが得られます。
 |
以降の説明は、いずれのデータセットも分散は未知ですが一様に分布した標本から抽出されたことから、重み付けのない回帰問題であると仮定します。
独立変数と従属変数の値の対で構成されるデータセットが M 個あるとします。独立変数 x の各値が ![]() であらわされる配列であると仮定して、これらのデータセットを一つにつなげます。これに対応する観測値の配列を
であらわされる配列であると仮定して、これらのデータセットを一つにつなげます。これに対応する観測値の配列を ![]() とします。なお、この問題の独立変数が複数あれば、各 xn と x はベクトルになります。
とします。なお、この問題の独立変数が複数あれば、各 xn と x はベクトルになります。
各データセットにアクセスするは、インデックス集合 {1, 2, ..., N} を M 個の部分に分割します。ここで、n0=0 および nM=N としたとき、1 ≤ k ≤ M について Dk = {n: nk-1 < n ≤ nk} と定義します。
1 ≤ k ≤ M をとるそれぞれの k について、データ x = xn をモデル化する関数 fk(x, Ak) を用意するとします。ここで n は Dk (n ∈ Dk) とします。回帰パラメータの集合は、モデル毎に Ak であらわします。この Ak の集合を横断する共有パラメーターは、少なくとも2つあります。
全ての Ak 集合に含まれるパラメーター集合の全体を {a1, a2, ..., ap} とします。このときグローバルフィットモデル F は以下のように定義されます:
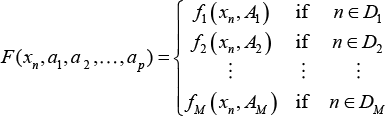 |
このグローバルフィット問題は、平方和を最小化するパラメーター値 a1*, a2*, ..., ap* を求めることです:
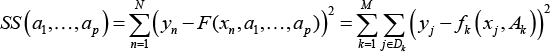 |
SigmaPlot のレポートに表示されるようなグローバルフィットの結果は、上記でも説明したように、全ての非線形回帰問題で求めるのと同じ方法で、この式から求められます。
また、SigmaPlot のレポートには、データセットそれぞれのについて計算された2つのローカルな結果も含まれます。ひとつは、Residual Sum of Squares (残差平方和) で、もうひとつは、当てはまりのよさ (goodness of fit) の尺度で決定係数 R2 として知られているものです。上の表記法を使用して、これらの量を単純な式であらわすことができます。まずはじめに、グローバルな残差平方和 SS resは次式で与えられます:
データセット k に関するローカルな残差平方和 SS res,k は次式で与えられます:
ここで、 Ak* は、{a1*, a2*, ..., ap*} の中の最良の当てはめ値に対応する Ak のパラメーター値です。
グローバルな R2 値を計算するには、次式で与えられるデータセット全体の総平方和 SS totalが必要です:
ここで、![]() は、観測値
は、観測値 ![]() の算術平均です。ここから次式が得られます。
の算術平均です。ここから次式が得られます。
データセット k についてローカルな R2 の値を求めるには、次式で与えられるこのデータセットに関する総平方和 SS total, k が必要です:
ここで、![]() は、データセット k にある観測値の算術平均です。ここから R2 のローカルな値は次式で得られます:
は、データセット k にある観測値の算術平均です。ここから R2 のローカルな値は次式で得られます:
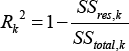 |
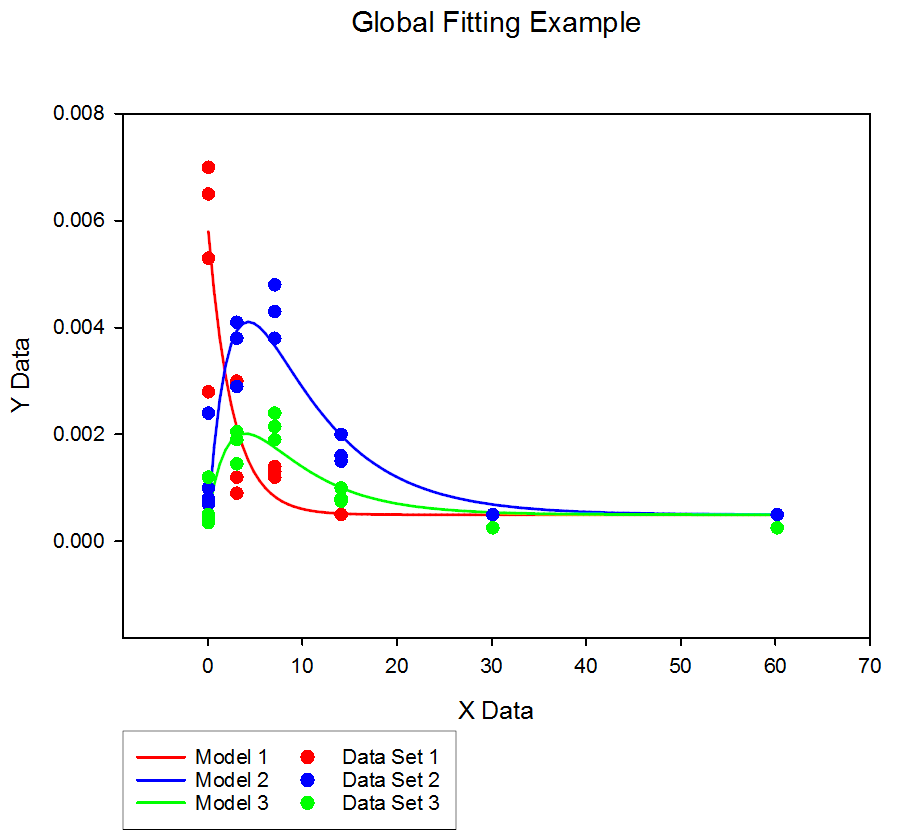
Nonlinear Regression Wizard を使用すれば Global Fit Wizard より一般的なグローバルフィット問題を解くことができます。以下に示すのは、Regression Wizard で作成した方程式ファイルの一例で、データセット3つで構成されるグローバルフィット問題を複数の当てはめモデルを使用して解くものです。各データセットの独立変数はいずれも同じであるため、データフォーマットは、X Many Y となります。各データは、ワークシートの最初の4列にそれぞれ配置されていると仮定します。このファイルは、データが X Many Y フォーマットになっているグローバルフィット問題を解くためのテンプレートとして使用することができます。
[Variables]
x={col(1),col(1),col(1)}
y={col(2),col(3),col(4)}
''Total of 3 data sets, using the X Many Y format
[Parameters]
''Initial parameter values
y0 = .000416667
L1 = 1.67391
L2 = 1.5
L3 = 1.5
a1 = .007
a2 = .00265
a3 = .001325
[Equation]
N=size(col(1))
X1 = x[data(1,N)]
X2 = x[data(N+1, 2*N)]
X3 = x[data(2*N+1,3*N)]
''Shared parameters are y0 and L1
f1=y0 + a1*exp(-L1*x1)
f2=y0 + a2*(exp(-L2*x2) - exp(-L1*x2))
f3=y0 + a3*(exp(-L3*x3) - exp(-L1*x3))
f= {f1, f2, f3}
fit f to y
[Constraints]
[Options]
tolerance=1e-10
stepsize=1
iterations=100
このファイルの Equation セクションに注目してください。データは Variables セクションでつなぎ合わされていますが、その後、3つの当てはめモデルをあらわすために個別のデータセットに再び分割されています (2番目と3番目のデータセットの当てはめモデルは実際には同じものです)。なお、3つの当てはめモデルがどのようにパラメーターを共有 (global) または非共有 (local) しているかに注意してください。重要なステップは、グローバルフィットモデル f がローカルモデル f1, f2, f3 の連結操作を経て構成されている点です。
Nonlinear Regression Wizard でこの事例を実行する場合は、データフォーマットパネルの From Code を使用します。レポートには、Global Fit Wizard のレポートと同様のグローバルフィットの結果 (データセット毎の Residual Sum of Squares と R2 ) が表示されます。Global Fit Wizard レポートにあるような Local の結果についても、この例の実行後に予測値の操作を実行する簡単な User-Defined Transform を記述することで容易にワークシートにアウトプットすることができます。また、Plot Equation ダイアログ (カーブフィットプロットに使用) と Graph Wizard (生データの散布図に使用) を使えば、グローバルフィットの結果をグラフに作成することもできます。この問題用に特別に選択したデータセットの場合、グローバルカーブフィットのグラフは以下のようになります。
 |