|
| サイトマップ | |
||
|
| サイトマップ | |
||
| NVivo テクニカルサポート |
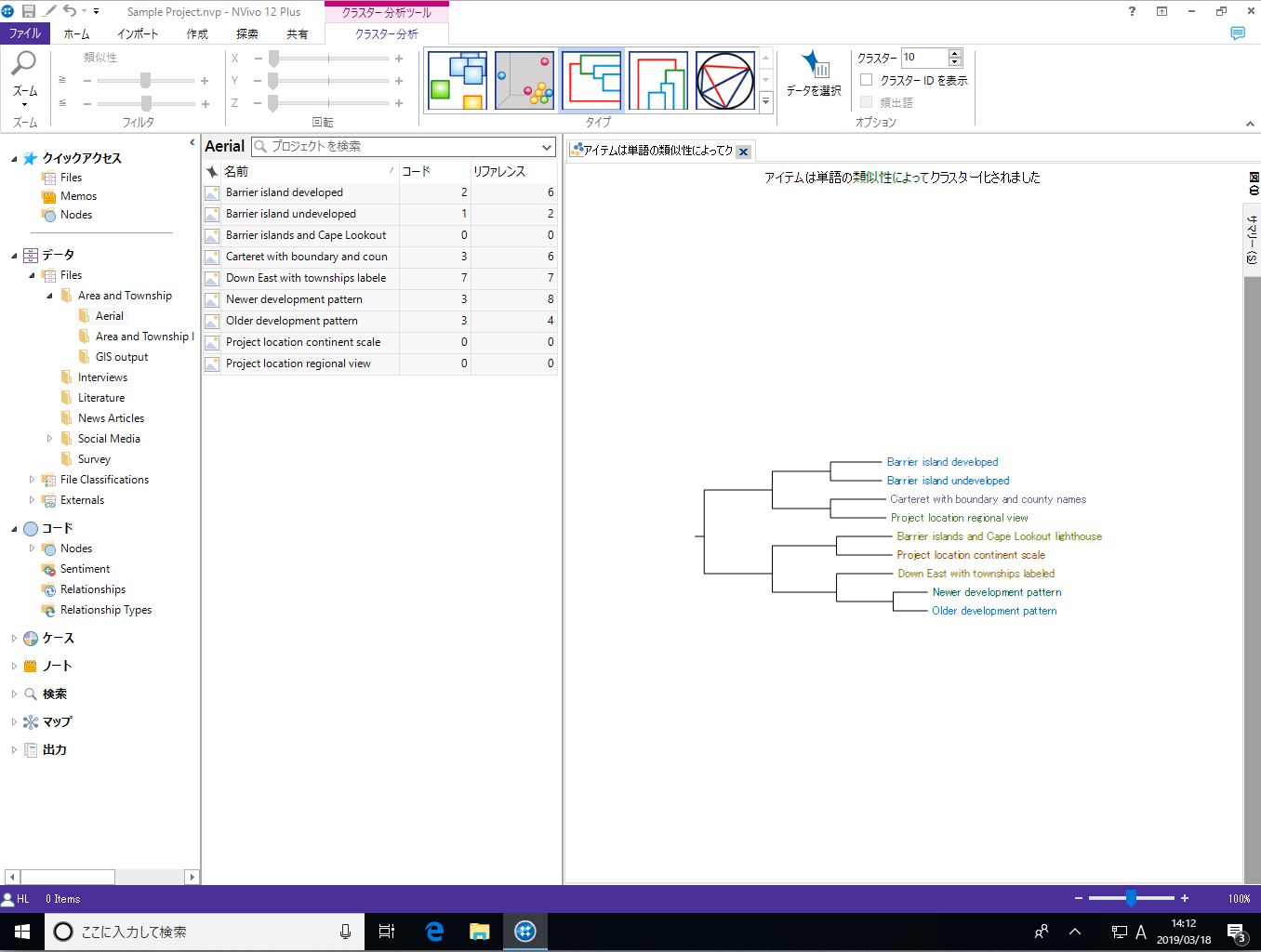
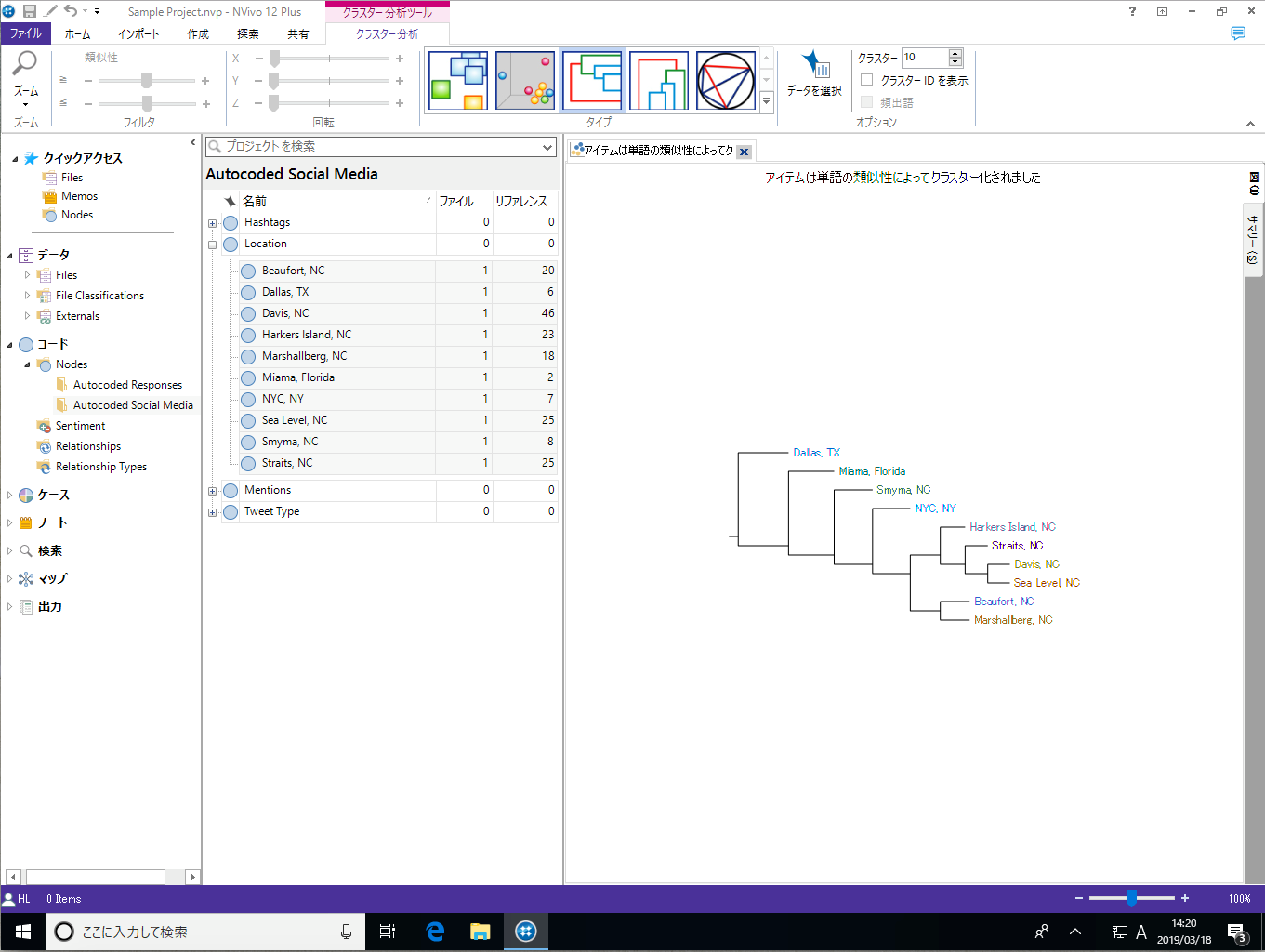
クラスター分析では、語の類似性、属性、コーディングといった条件を使って、ソースやノード/ケース間の類似性や差異を視覚化できます。
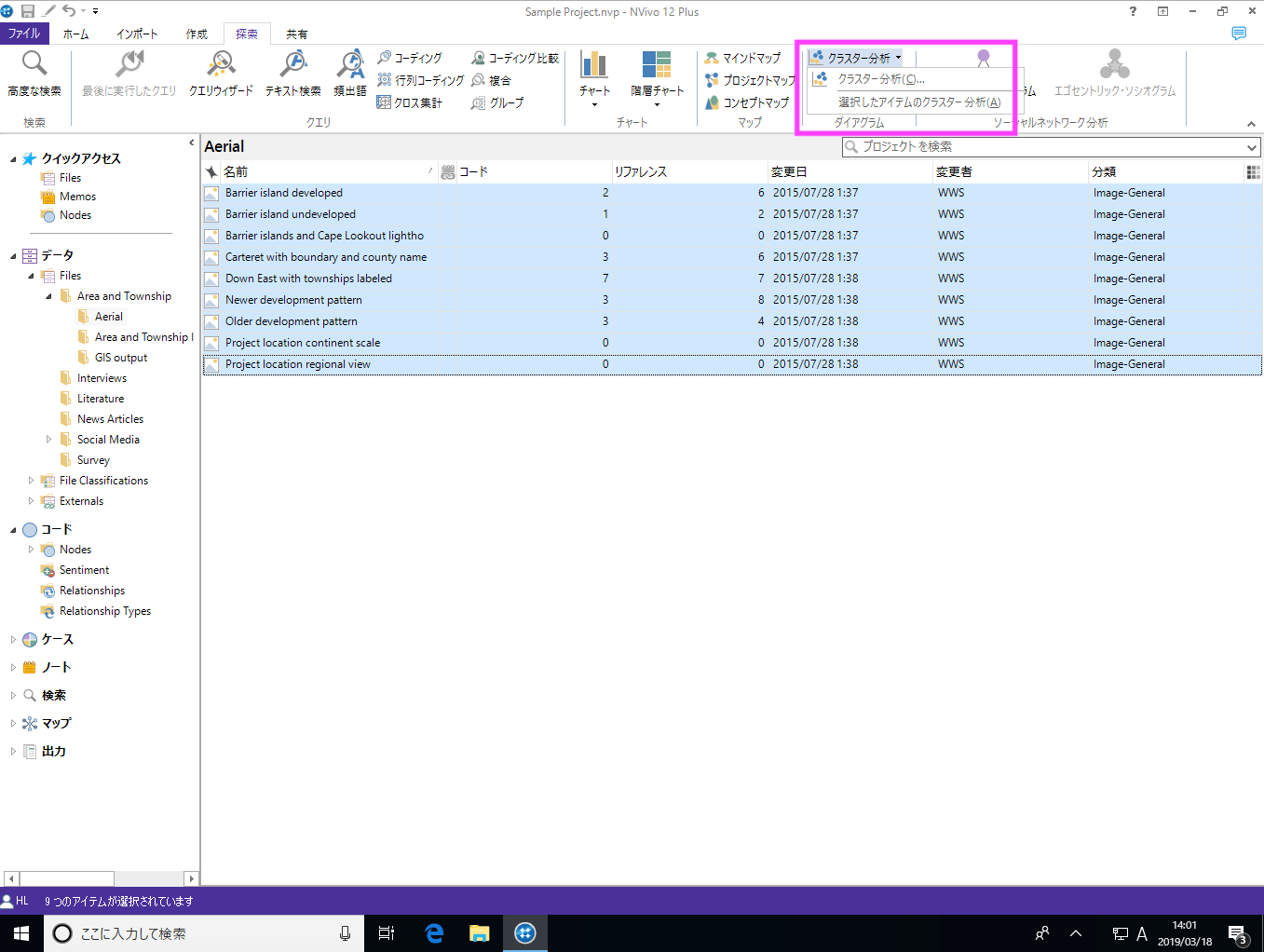
クラスター分析の対象となるアイテムは3種類です。
クラスター分析の分類方法 (クラスター化) には3種類あります
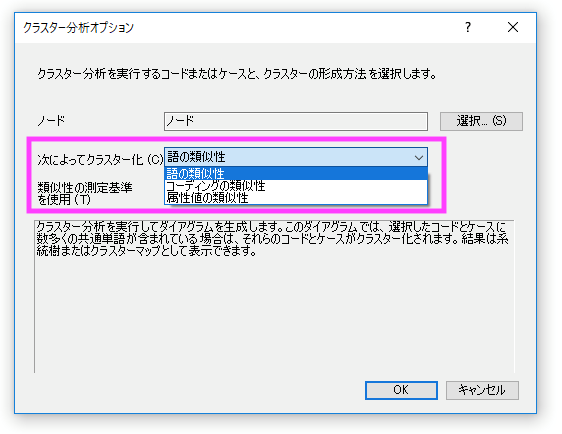
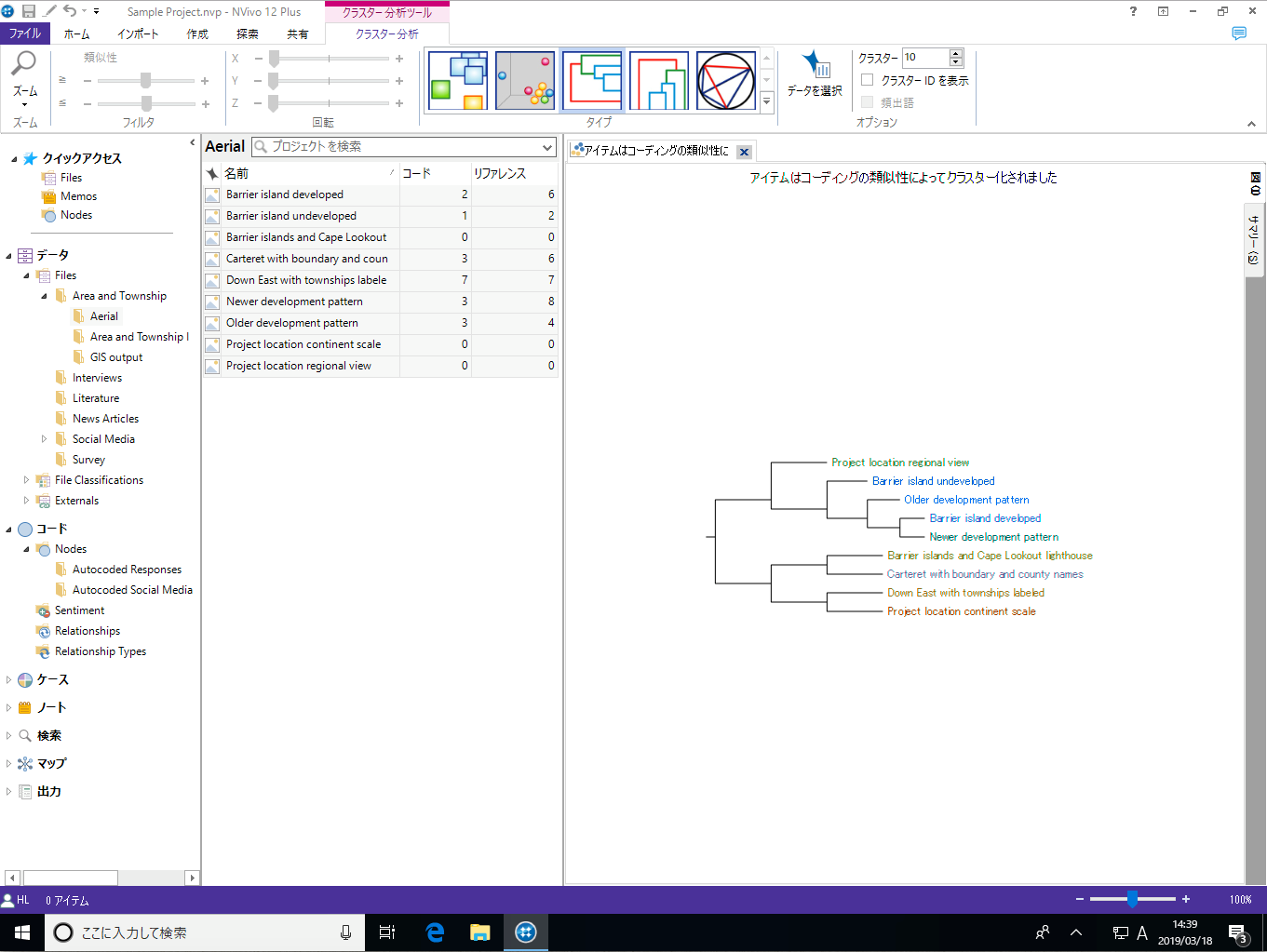
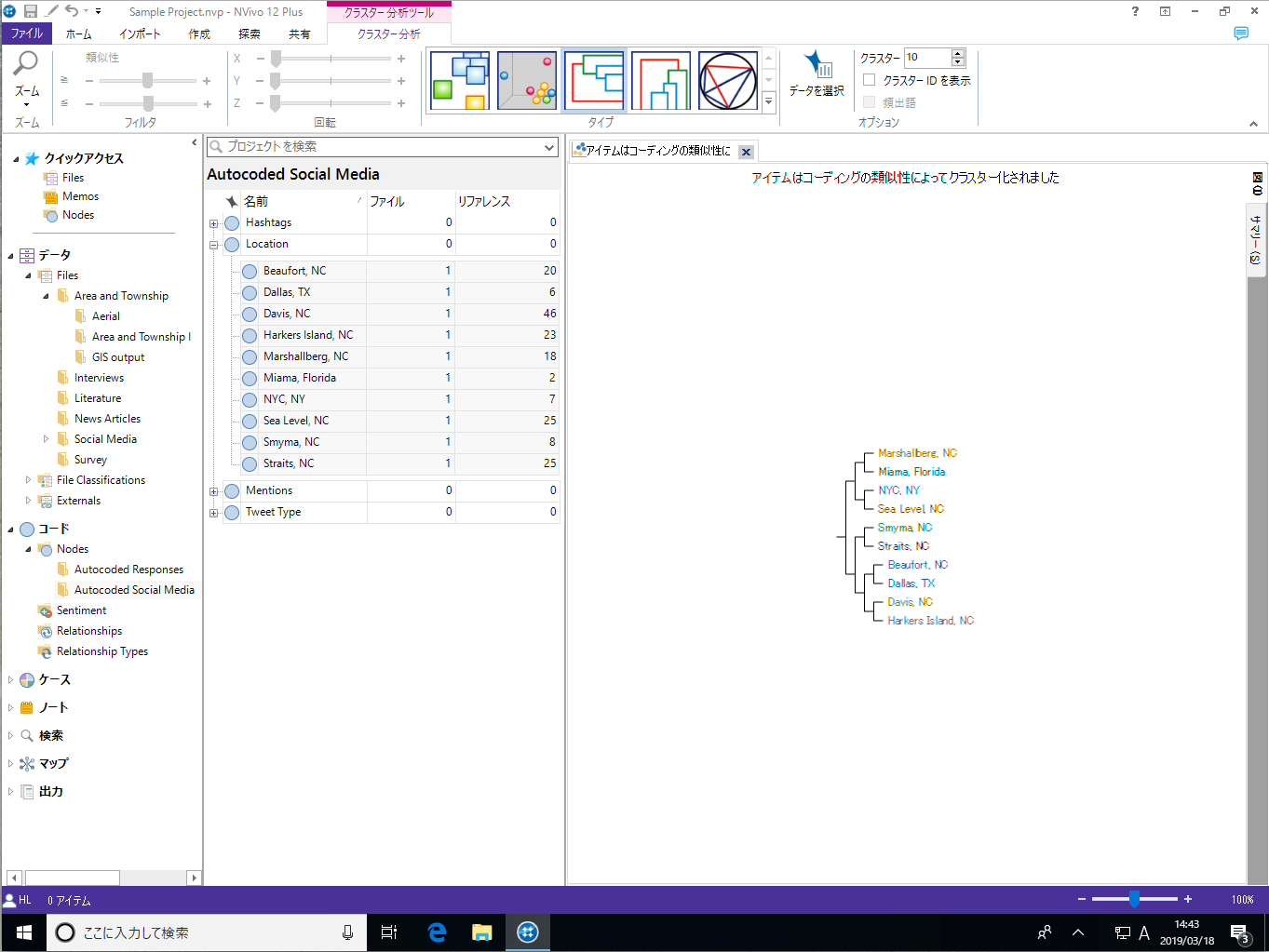
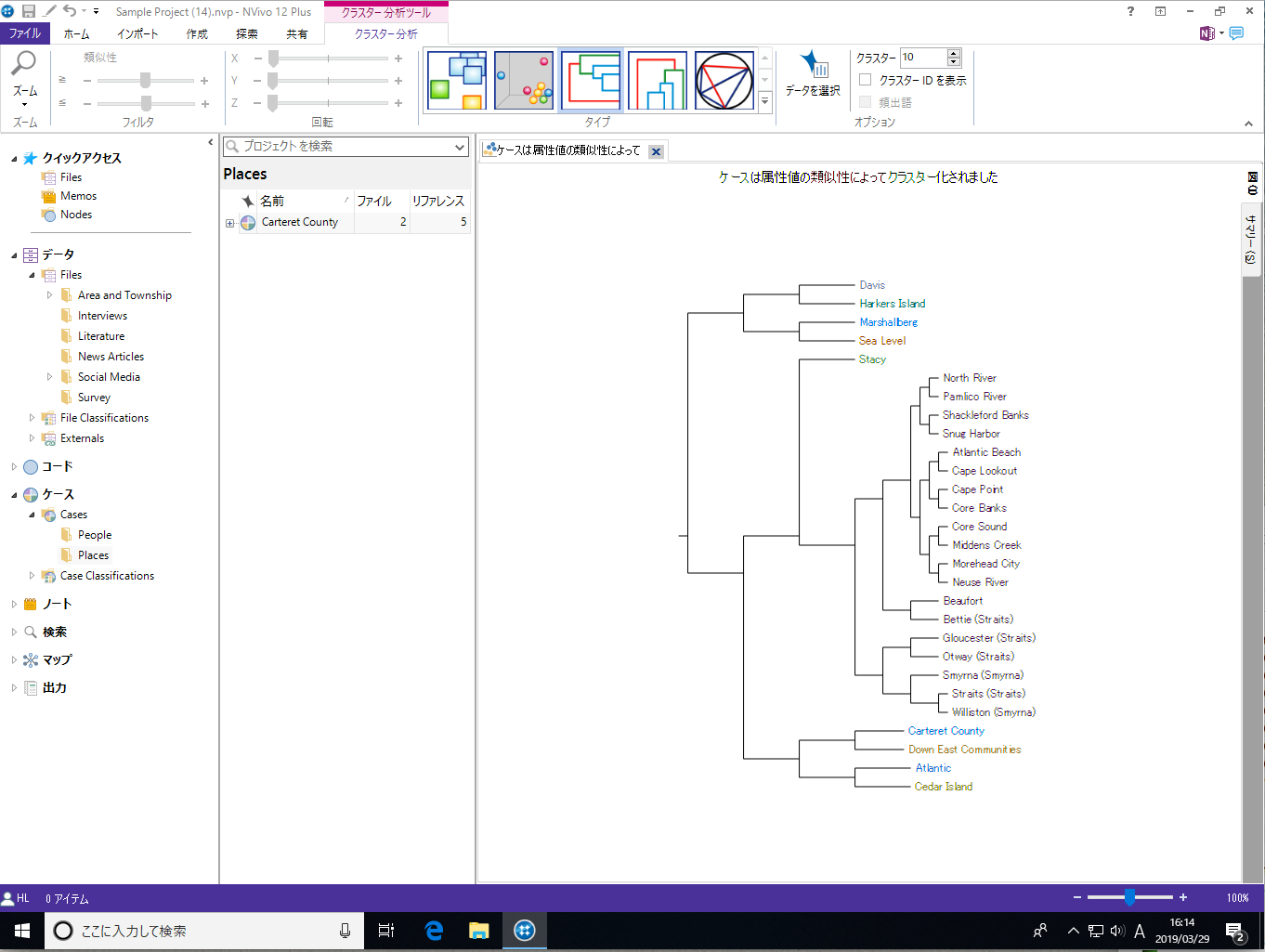
対象アイテム毎に選択可能な分類方法は以下の通りです。
|
語の類似性 | コーディングの類似性 | 属性値の類似性 |
|---|---|---|---|
| ソース | ○ | ○ | ○ |
| ノード | ○ | ○ | ○ |
| 単語 | × | × | × |
| ※ 重要:頻出語クエリを使って検索した単語に対しては、「類似性」を基づくクラスター分析を行うことはできません。頻出語クエリの場合は「同一ソース内で頻繁に登場する単語同士は近く、そうでないものは離れて配置されます」。また、正しくクラスター化するためには、複数のソースを選択する必要があります。 |