|
| サイトマップ | |
||
|
| サイトマップ | |
||
Mathematica による記述統計に関する使用例を説明します。
記述統計 (Descriptive statistics) は、データの特徴を要約し、理解するための方法です。データの欠損値の確認、中心傾向、ばらつき、および分布の形状などの情報を得ることができます。
Mathematica の豊富な関数を使用してデータを簡単に要約することができます。次項から、10 名分の身長の計測データ (表1) を例として、各統計値を評価する手順を示します。
| 身長 |
|---|
| 160 |
| 158 |
| 163 |
| 170 |
| 174 |
| 169 |
| 178 |
| 166 |
| 174 |
| 182 |
身長の例のデータについて Mathematica を使用して計算します。
Mathematica を起動し、新規ノートブックを開いて次のようにデータを入力します。波括弧 { } は、データのリストや範囲の定義に使用します。
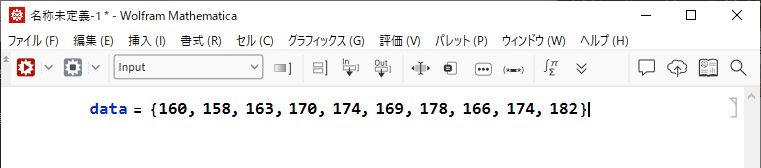 |
| data={160, 158, 163, 170, 174, 169, 178, 166, 174, 182} |
入力したら、変数 data に入力した値のリストを割り当てます。入力したデータのセル内をマウスで選択して、キーボードの Shift + Enter キーで実行します。
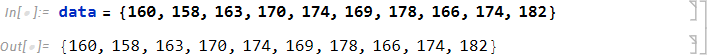 |
値の集合に対して最も一般的に使用される統計量は平均値です。
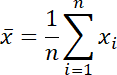
| ※ Σ は i について 1 から n まで合計するという意味です。 |
平均値を求めるには、Mean 関数を使用します。Mean 関数の角括弧内に上記で割り当てた変数 data を入力して実行します。
| Mean[data] |
実行すると次の結果が表示されます。
 |
小数点で表示するには、次のように入力します。
| N[Mean[data]] |
実行すると次の結果が表示されます。
 |
桁数を指定して表示する場合、例えば 6 桁で表記するには次のように入力します。
| N[Mean[data], 6] |
指定した桁数の結果が表示されます。
 |
この値が母集団からサンプリングされたデータの場合は標本平均、母集団のすべてを表す場合は母平均になります。
データを小さい順に並べてちょうど中央にある値が中央値になります。偶数の場合は、データを小さい順に並べて中央部分の 2 つの値の平均値が中央値です。Median 関数を使用します。N 関数を使用して小数点表示にします。
| N[Median[data]] |
計算結果は次のとおりです。
 |
データの個数を求めるには Length 関数、最小値を求めるには Min 関数、最大値を求めるには Max 関数を使用します。
| Length[data] |
| Min[data] |
| Max[data] |
各々の計算結果は次のとおりです。
 |
不偏分散は、分布の散らばりの測度として標準偏差と共に最もよく使用されます。次の式で求められます。
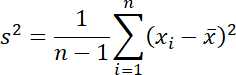
不偏分散を求めるには、Variance 関数を使用します。 N 関数を使用して小数点表示にします。
| N[Variance[data]] |
計算結果は次のとおりです。
 |
標準偏差は分布の散らばりの測度として分散と共に最もよく使用されます。不偏分散の正の平方根を取ることで標準偏差になります。
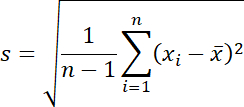
標準偏差を計算するには、StandardDeviation 関数を使用します。この後、標準誤差の計算に標準偏差の結果を使用するため、標準偏差の結果を N 関数を使用して小数点表示にして、変数 sd に割り当てます。
| sd=N[StandardDeviation[data]] |
計算結果は次のとおりです。
 |
標準誤差は、標本統計量のばらつきを示す指標です。標本平均や標本比率などの推定値の精度を表します。標本の標準偏差を標本数の平方根で除算したものです。
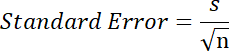
標準偏差を標本数 10 の平方根で除算します。平方根を求める Sqrt 関数と上記の標準偏差で割り当てた変数 sd を使用して次の式で計算します。
| sd/Sqrt[10] |
計算結果は次のとおりです。
 |
歪度は、データの分布が正規分布からどれだけ歪んでいるかを表します。正規分布は、確率論や統計学で用いられる連続的な変数に関する確率分布の一つで、データが平均値の付近に集積するような分布を表します。分布の歪度は次のように定義されます。
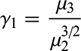
| ※ μr は、r 次の中心モーメントです。中心モーメントは、 |
大まかに左右対称となる分布では歪度はゼロに近くなります。
データが右側に裾が広がっている場合は、歪度は正の値になります。
データが左側に裾が広がっている場合は、歪度は負の値になります。
歪度を計算するには、Skewness 関数を使用します。
| N[Skewness[data]] |
計算結果は次のとおりです。
 |
尖度は、分布が正規分布からどれだけ尖っているかを表します。正規分布は、確率論や統計学で用いられる連続的な変数に関する確率分布の一つで、データが平均値の付近に集積するような分布を表します。理論的な分布の尖度は次のように定義されます。
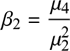
| ※ μrは、r 次の中心モーメントです。中心モーメントは、 |
分布が正規分布に比べて急尖の場合は、尖度が正の値になります。

分布が正規分布に比べて緩尖の場合は、尖度が負の値になります。
尖度を計算するには、Kurtosis 関数を使用します。
| N[Kurtosis[data]] |
計算結果は次のとおりです。
 |
分位数は、データの要約統計量や異常値の検出、データの比較、データの可視化など統計的な目的で使用されます。データの特性を理解するために四分位数 (Quartiles) 、パーセンタイル (Percentiles) 等を選択して分析します。分位数を計算するには、Quantile 関数を使用します。
四分位数 (25% 分位点、75% 分位点) を指定する場合は次のように入力します。
| Quantile[data, {0.25, 0.75}] |
次の結果が得られます。
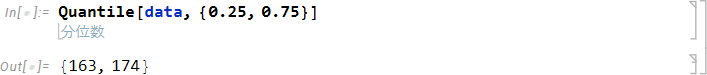 |
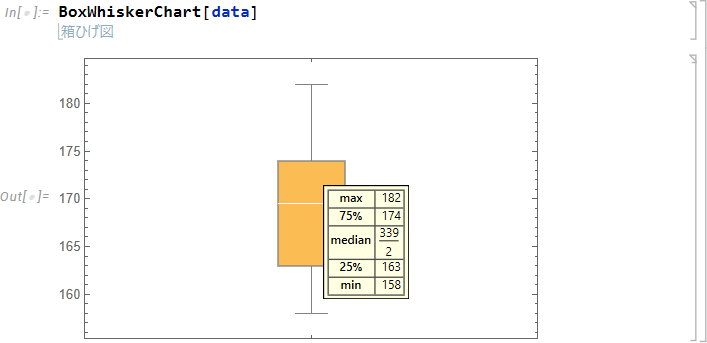
箱ひげ図は、データの分布の様相を視覚的にとらえやすく表すための図です。分布は、箱の中の線が中央値、上辺と下辺が上側ヒンジ (75%)、下側ヒンジ (25%) 、上下のひげの端は最大値、最小値です。
箱ひげ図を表示するには、BoxWhiskerChart 関数を使用します。
| BoxWhiskerChart[data] |
結果は次のとおりです。箱ひげ図をカーソルで選択すると最小値 (min)、第1四分位点 (25%)、中央値 (median)、第3四分位点 (75%)、最大値 (max) の情報が得られます。
 |
正規性は、データが正規分布に従っていることを指します。例として、コルモゴロフ・スミルノフ検定とシャピロ・ウィルク検定を使用して、データが正規分布に従っているか検定します。正規性を求めるには、DistributionFitTest 関数を使用します。
はじめに DistributionFitTest 関数の結果を変数 h に割り当てます。
| h=DistributionFitTest[data, Automatic, "HypothesisTestData"]; |
TestDataTable (検定表) のコルモゴロフ・スミルノフ検定の結果を表示します。
| h["TestDataTable", "KolmogorovSmirnov"] |
実行した結果は次のとおりです。
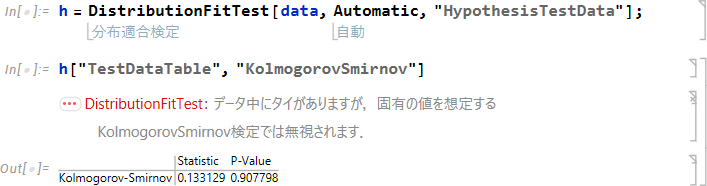 |
| ※ データに同値があると警告「DistributionFitTest: データ中にタイがありますが、固有の値を想定する KolmogorovSmirnov 検定では無視されます.」が表示されます。 |
次に、シャピロ・ウィルク検定の結果を表示します。
| h["TestDataTable", "ShapiroWilk"] |
実行した結果は次のとおりです。
 |
P-Valueで有意差を確認できます。いずれも有意水準 (通常 0.05) よりも大きい値となっています。 帰無仮説は「正規分布に従う」であり、有意水準以上であれば、帰無仮説「正規分布に従う」が採用されます。有意水準以下の場合は、帰無仮説が棄却され対立仮説「正規分布に従わない」が採用されます。
次を実行することですべての検定表が得られます。
| h["TestDataTable", All] |
平均値の信頼区間は、母集団から抽出されるすべての可能な標本の割合について、真の母集団の平均が収まる範囲です。区間の端点は次の式で与えられます。
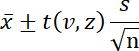
ここで、x バーは平均、 s は標本の標準偏差、 t (v, z) は、自由度 v = n -1 、標準正規パーセンタイル z = 1.96 の t 値です。
平均値の信頼区間は、MeanCI 関数を使用します。MeanCI 関数は、仮説検定パッケージ (HypothesisTesting) に含まれるため、はじめに仮説検定パッケージをロードします。パッケージの読み込みには Needs 関数を使用します。
| h["TestDataTable", All] |
次に、MeanCI 関数を使用します。
| MeanCI[data] |
計算結果は次のとおりです。
 |
ヒストグラムは度数分布を図で表したもので、横軸は区間で分けた変数、縦軸は度数をとります。ヒストグラムを表示するには、Histogram 関数を使用します。
| Histogram[data] |
次の結果が得られます。
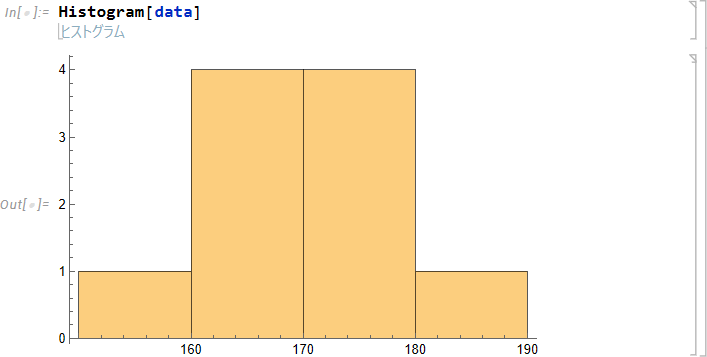 |
ビンの数を指定することもできます。ビンの数を 3 つにする場合は次のように入力します。
| Histogram[data,{"Raw",3}] |
結果は次のとおりです。
 |