|
| サイトマップ | |
||
|
| サイトマップ | |
||
グラフ作成を行う前に、基本統計データを見たいという場合がしばしばあります。Grapher はワークシートのデータについて統計情報を計算し、それらをグラフ化することができます。こうすることによって、データの特性を把握することができます。
この事例で使用するデータは、ここ (サンプルデータ) からダウンロードすることができます。統計情報の計算には、さほど時間を要しません。基本統計データからどのようなモデルを作成するか判断し、箱ヒゲ図とヒストグラムを作成した後、QQ プロットを作ってみましょう。
File | Open メニューコマンドをクリックして [random sample.dat] ファイルを開き、開始しましょう。Data | Sort コマンドを使って昇順 (Ascending) に並び替えします。列全体を選択し (反転状態にし) 、Data | Statistics メニューコマンドをクリックします。Statistics ダイアログで、計算したい項目を選択することができます。Minimum、Maximum、Mean、Standard error of the mean、95% confidence interval for the mean、Standard deviation をチェックして下さい。計算結果は、ワークシートに保存するため Copy to worksheet とし Starting in cell の値を C1 に設定します。
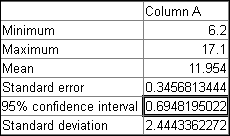 |
ワークシートにコピーされた表から、データの範囲は 6.2 から 17.1 で平均が 11.954 であることがわかります。平均の 95% 信頼区間は約 0.695。したがって、平均に信頼区間を加えるとその幅は 11.259 から 12.649 になります。すなわち、真の平均 (母平均) は 95%の確率でこの範囲にあることを意味します。標準誤差は、別の信頼区間の計算あるいは検定のために使用されます。標準偏差 2.444 は、値のばらつき具合の推定を表します。これらの値は、仮説検定などのさらに高度な統計解析や、グラフに追加上を加えるために使用されます。
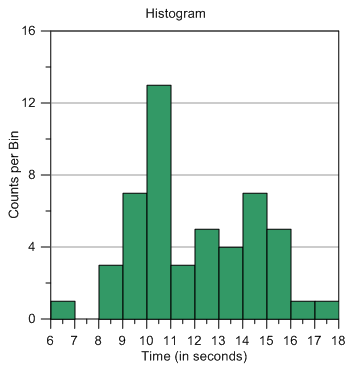
おそらく最初に必要となるグラフは、ヒストグラムでしょう。データ範囲を区分けした各階級のデータポイント数を示すことによって、どのようにデータが分布しているか把握することができます。Grapher では、ビンのサイズは区間幅と同じです。また、ビンの数は任意に設定することができます。
ヒストグラムを作るには、Graph | 2D XY Graphs | Histogram メニューコマンドをクリックします。データファイルを選択して開くボタンを押します。ヒストグラムを作成すると、すべてのデータ (6.2 から 17.1) が含まれる範囲で、ビンのサイズと数が自動的に設定されて表示されます。ビンのサイズと数は、変更することができます。
このグラフに、ガウス曲線あるいは既知の分布曲線を当て嵌めてみましょう。このグラフは、正規分布をしているようには見えません。なぜなら、最大ピークが中央からずれており、全体の形も非対称です。そのため、もう少し確率分布について調べてみる必要があります。
 |
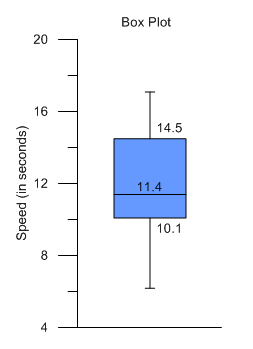
箱ヒゲ図を使うと、生データのばらつきの傾向を素早く把握することができます。箱の本体は中央値の傾向を、そしてヒゲ部分は標準的な値から外れたデータを表します。箱の中の中央値の線を比べることで、データの広がり具合がわかります。
箱ヒゲ図を作るには Graph | Specialty Graphs | Box-Whisker Plot メニューコマンドをクリックします。データファイルを選択し開くボタンを押します。デフォルト設定の箱ヒゲ図が作成されます。箱ヒゲ図は、ラベルや外れ値を追加したり、その他プロパティの値を変更することができます。
ラベルと外れ値を加えます。
 |
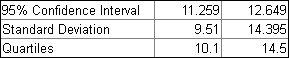
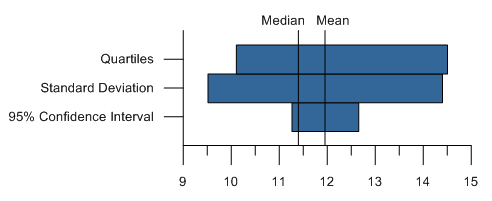
最後に、ワークシートの Data | Statistics メニューコマンドのデータと、箱ヒゲ図の値を比べるグラフを作成します。浮動バーグラフは、データの範囲を表すのに適しています。ワークシートの統計情報をアレンジして、平均値 +95% 信頼区間と平均値 -95% 信頼区間を別々の列に表示させます。さらに以下の表のように、第1四分位と第3四分位の行と、平均値-標準偏差と平均値+標準偏差の行を追加します。
 |
浮動バーグラフを作るには、Graph | 2D XY Graphs | Floating Bar メニューコマンドをクリックします。データを選択して開くコマンドをクリックします。デフォルトの状態では、次のように表示されるはずです。
 |
QQプロットは、正規曲線と実データを比較するためのプロットです。直線のフィッティングが行えるデータは、正規分布だと見なせます。まず、実データセットと同じデータポイント数の正規曲線のデータが必要です。適切な間隔の正規曲線は、次のようして描きます。
 |
QQ プロットを作成するために、Plot ウィンドウをクリックします。
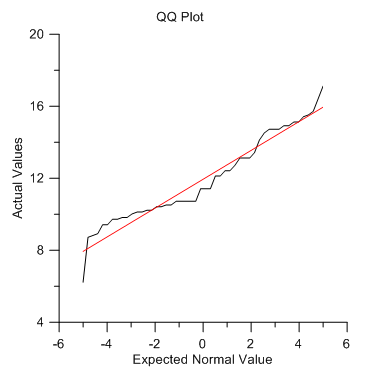 |
線形のフィット曲線にデータがほぼ一致しているため、外れ値はあるもののデータはほぼ正規分布であることがわかります。
基本統計の計算結果とグラフを使って、高度な解析を行うために必要なデータの特性が把握できました。