|
| サイトマップ | |
||
|
| サイトマップ | |
||
この解析は、DNA シーケンスから指定した長さの回文配列 (inverted repeat) を検索するものです。DNA や転写された RNA から二次構造の可能性のある領域を同定するのにこの解析を利用することができます。図 4.25 に示すのは、この解析のセットアップパネルです。
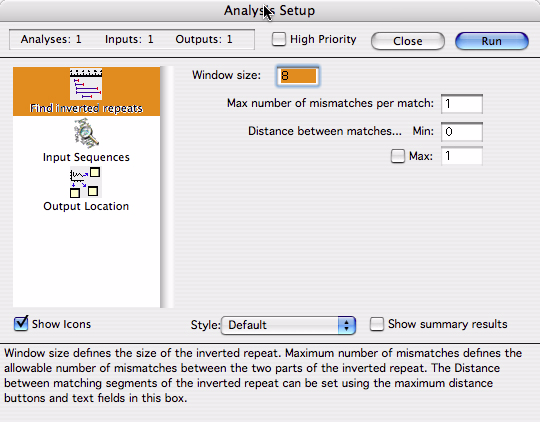 |
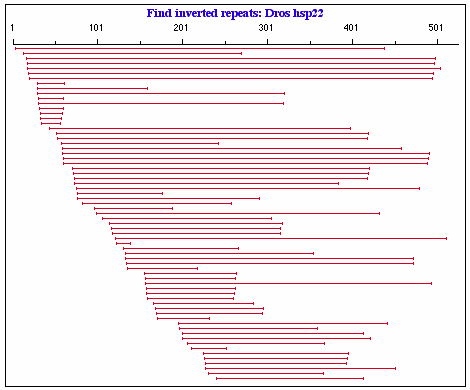
窓サイズ (Window size) は、検索で求める回文配列のセグメント・サイズです。Maximum number of mismatches (ミスマッチの最大数) は、第一セグメントと第二 (逆方向) セグメント間のミスマッチとして許容されるヌクレオチドの最大数です。その下のテキストボックスでは、回文配列を構成する2つのセグメント間に存在するヌクレオチドの最小数と最大数を定義します。出力結果は図 4.26 のようになります。出力オブジェクトには、回文配列のそれぞれが短い水平線で表示されます。その両端は (縦の目盛りで表示)、回文配列の各セグメントの開始点をあらわします。
 |
グラフィックとして出力されたオブジェクトをターゲット状態にして、メニューから Object > View As Table を選択すると、その出力内容をテーブル形式に変更することができます。図 4.27 に示すのはテーブル形式で表示された出力結果です。
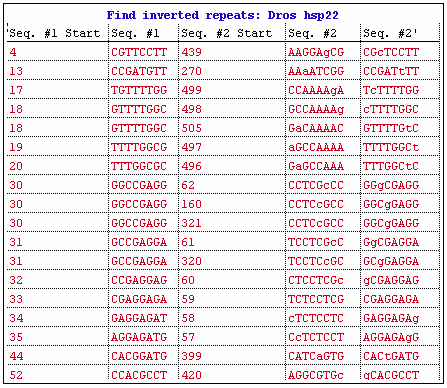 |
テーブル出力には、グラフィカル・ビューでは表示されない情報が含まれています。テーブルの行は、回文配列をそれぞれ表しています。Seq. #1 Start は、回文配列の第一部分 (セグメント) の先頭ヌクレオチドの位置情報を示します。具体的なシーケンスの内容は、Seq. #1 というラベルの付いた2番目の列に表示されます。Seq. #2 Start というラベルの付いた列には、回文配列の開始点となるヌクレオチドの先頭位置が表示されます。この位置情報は、Seq. #1 を含む上鎖の 5' 末端からの位置となります。4番目の列の Seq. #2 は、回文配列に対応する上鎖のヌクレオチド配列です。ミスマッチがあった場合は、一行目の "c" のように小文字で表示されます。反転後の配列を分かり易くするために、Seq. #2’ とラベルの付いた列5に列4の配列を反転したものが表示されます。回文配列の全体像をグラフィカルビューで (図 4.26) 把握することができますが、このテーブルに表示されるミスマッチ情報も解析にとって何らかの役に立つこともあるでしょう。
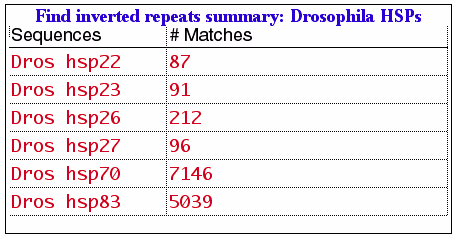
図 4.25 に示す Show summary results チェックボックスにチェックを入れると、選択したすべてのシーケンスに関する回文配列の解析結果をまとめた一つの出力結果が生成されます。図 4.28 に示すのは、回文配列解析の結果をまとめた出力結果です。この解析の場合、サマリー結果はテーブル形式で表示されています。図 4.26 に示すような形式で個々のシーケンスの解析結果を表示させたい場合には、まずはじめに、サマリー出力オブジェクトをターゲット状態にした後、調べたいシーケンス (複数可) を選択状態にして、Object > Search Selected Sequences... を選択します。選択したシーケンスだけの解析セットアップパネルが表示されるはずです。これは、多数のシーケンス解析をひとつの出力オブジェクトで素早く調べたい場合に便利な手段となります。
 |