|
| サイトマップ | |
||
|
| サイトマップ | |
||
Tecplot では位置情報を XYZ のような直交座標 (Ordered Data) か有限要素 (Finite Element) のいずれかで指定します。
直交座標の場合、データを Tecplot に読み込む際に座標値 (X, Y, Z 等) とは別にインデックス情報 (I, J, K) を指定する必要があります。
まずは 2次元データでインデックス情報 (I, J, K) の指定方法をご説明します。
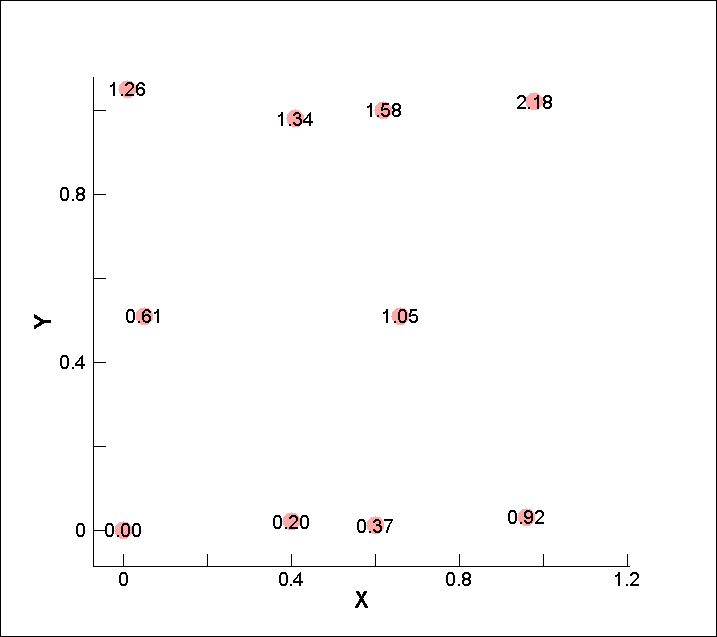
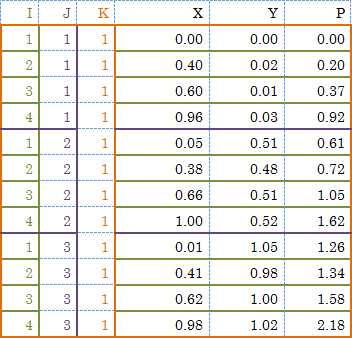
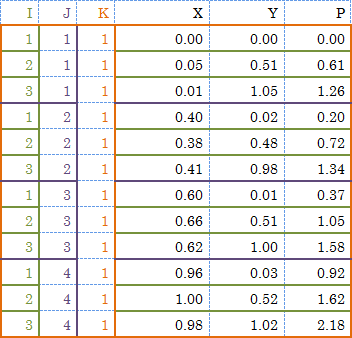
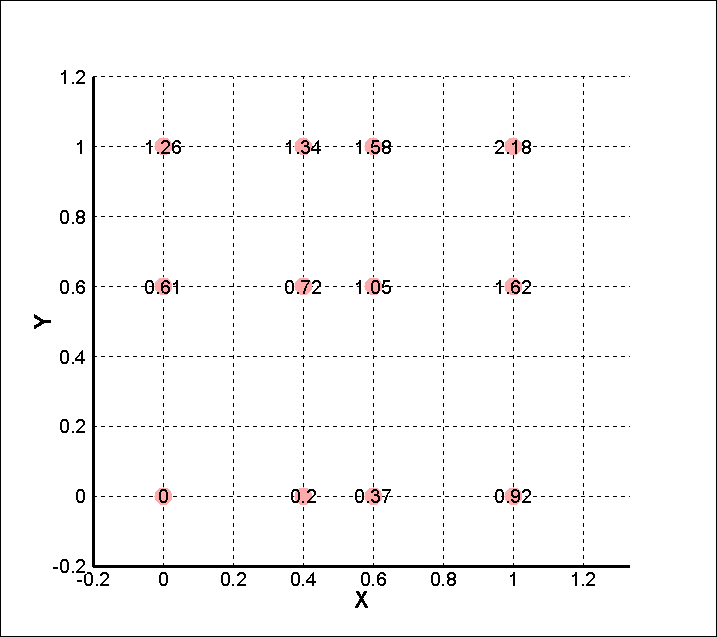
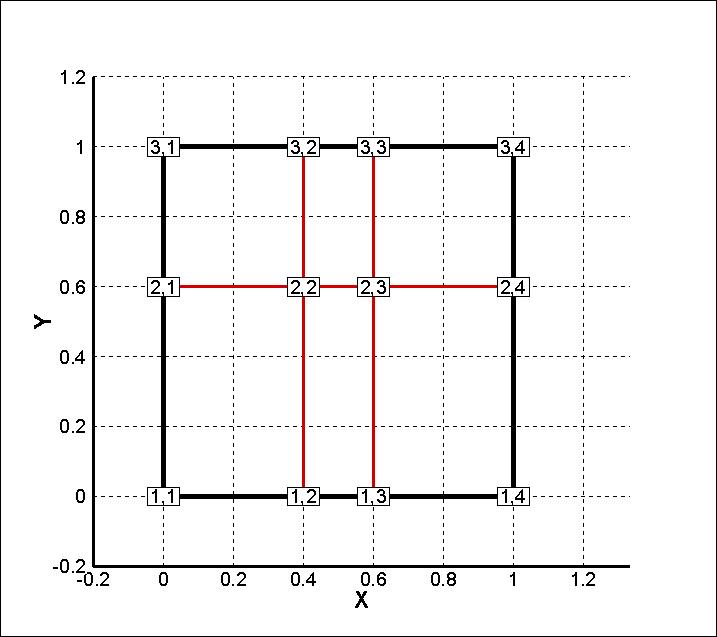
X 軸方向 4点、Y 軸方向 3点、合計 12 点の測定点 (図中の赤丸) と、測定値 P (図中の数値) があります。
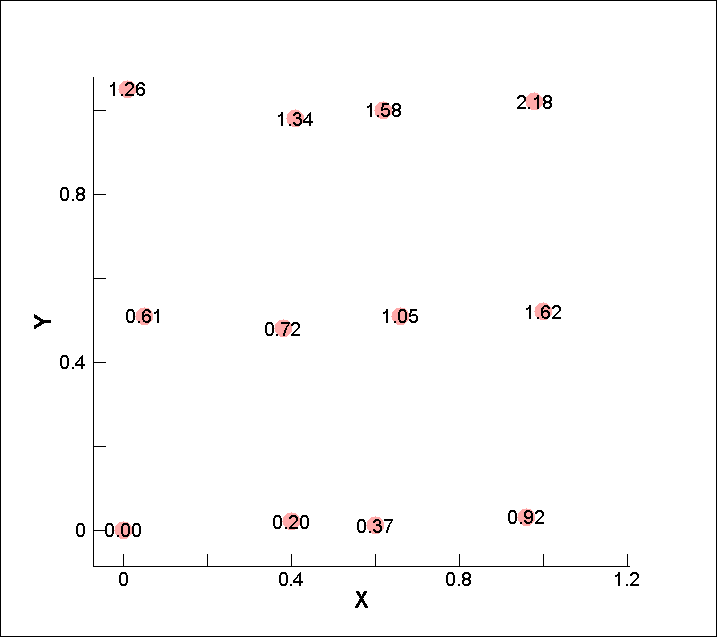
|
このサンプルデータの場合、X 軸方向の測定点の数「4」と、Y 軸方向の測定点の数「3」がインデックス I とインデックス J の値になります。つまりインデックス情報 (I,J,K) として (4,3,1) か (3,4,1) のいずれかを指定します。
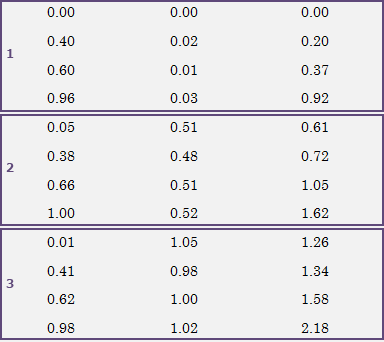
このサンプルデータの場合、テキストデータを次のような行列 (全体を括る括弧は不要です) で表記します。(*1)
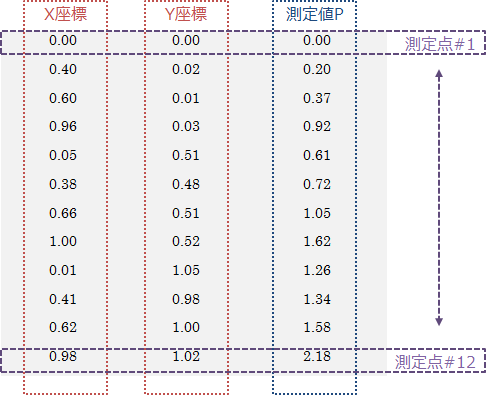
|
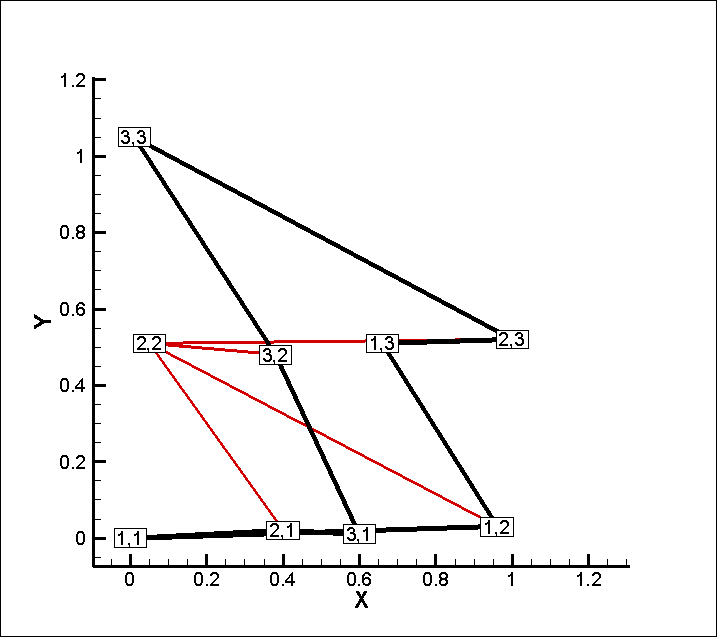
I=4, J=3, K=1 と指定した場合のインデックス割当は以下のようになります。
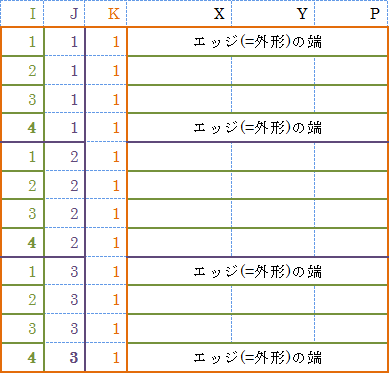
つまりテキストデータ (行列) の行を図中の青い破線の順に並べることになります。
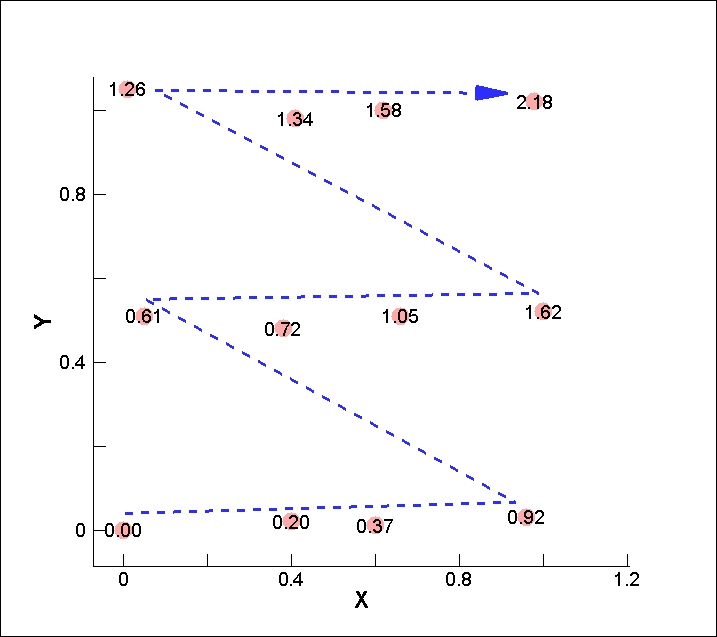
I=4, J=3, K=1 に合わせて青い破線の順に、テキストデータ (行列) の行を並べ替えた結果
0.00 0.00 0.00 0.40 0.02 0.20 0.60 0.01 0.37 0.96 0.03 0.92 0.05 0.51 0.61 0.38 0.48 0.72 0.66 0.51 1.05 1.00 0.52 1.62 0.01 1.05 1.26 0.41 0.98 1.34 0.62 1.00 1.58 0.98 1.02 2.18
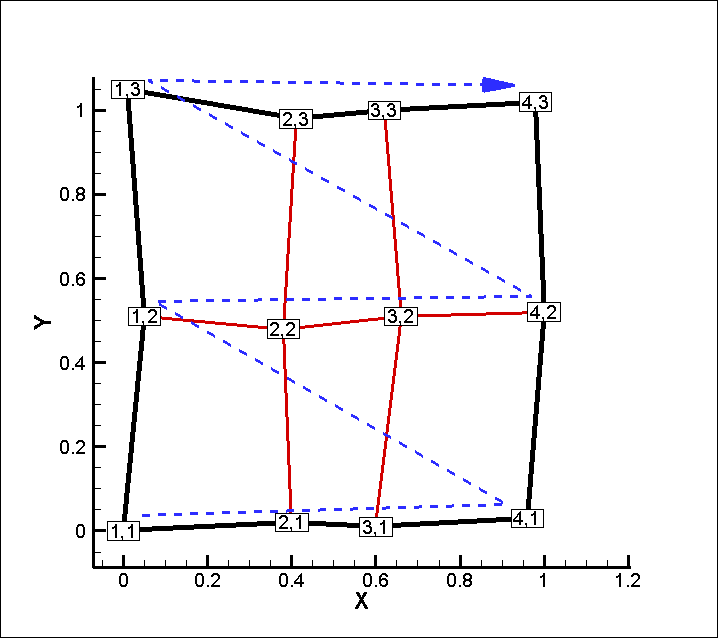
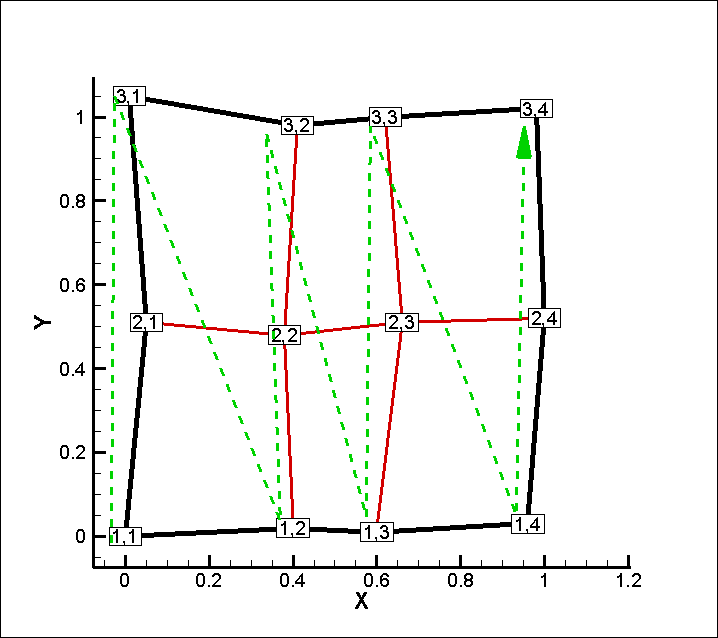
I=3, J=4, K=1 と指定した場合のインデックス割当は以下のようになります。
つまりテキストデータ (行列) の行を図中の緑の破線の順に並べることになります。
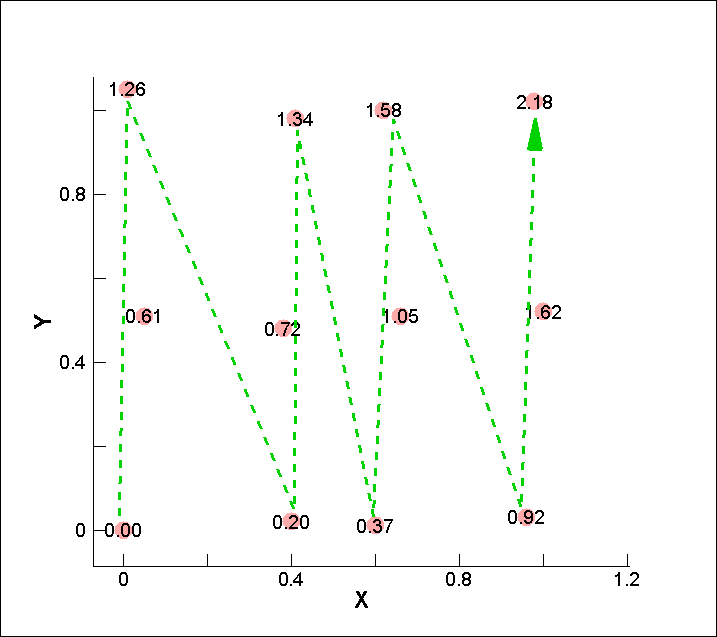
I=3, J=4, K=1 に合わせて緑の破線の順に、テキストデータ (行列) の行を並べ替えた結果
0.00 0.00 0.00 0.05 0.51 0.61 0.01 1.05 1.26 0.40 0.02 0.20 0.38 0.48 0.72 0.41 0.98 1.34 0.60 0.01 0.37 0.66 0.51 1.05 0.62 1.00 1.58 0.96 0.03 0.92 1.00 0.52 1.62 0.98 1.02 2.18
| (*1) |
| これは Tecplot では POINT フォーマットと呼ぶデータフォーマットです。 他にも BLOCK フォーマットがありますが、ここでは説明を割愛させていただきます。 BLOCK フォーマットについてはユーザーマニュアルを参照ください。 |
| (*3) |
| テキストデータ (行列) の行は、インデックス情報 (I,J,K) に従って規則的に並べる必要があります。座標値のソートで並べて問題ない場合もありますが、形状によっては読み込めても正しい形状になりません。 |
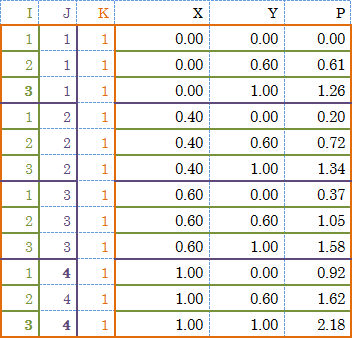
下図のような単純な形状 (長方形メッシュ) ならば、座標値のソートでテキストデータ (行列) の行を並べても問題ありません。
このテキストデータ (行列) を X値、Y値の順にソートし、
I=3, J=4, K=1 と指定した場合のインデックス割当は以下のようになります。
0.00 0.00 0.00 0.00 0.60 0.61 0.00 1.00 1.26 0.40 0.00 0.20 0.40 0.60 0.72 0.40 1.00 1.34 0.60 0.00 0.37 0.60 0.60 1.05 0.60 1.00 1.58 1.00 0.00 0.92 1.00 0.60 1.62 1.00 1.00 2.18
このテキストデータ (行列) を I=3, J=4, K=1 と指定して読み込んだ結果
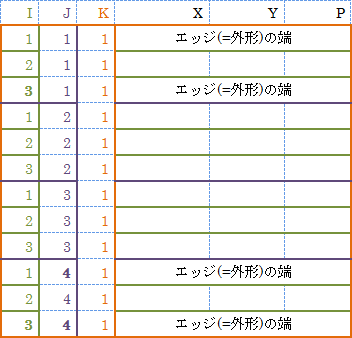
(交点の枠内の数字は I,J 、黒線はエッジ (=外形)、赤線はメッシュ)
しかしサンプルデータのような多角形の場合、座標値のソートでテキストデータ (行列) の行を並べると、内部にある筈の点がエッジ (=外形) からがはみ出す場合があります。
サンプルデータ (2D_sample_I3J4.txt) を X値、Y値の順にソートし、
I=3, J=4, K=1 と指定した場合のインデックス割当
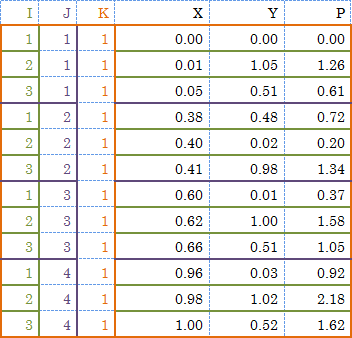
0.00 0.00 0.00 0.01 1.05 1.26 0.05 0.51 0.61 0.38 0.48 0.72 0.40 0.02 0.20 0.41 0.98 1.34 0.60 0.01 0.37 0.62 1.00 1.58 0.66 0.51 1.05 0.96 0.03 0.92 0.98 1.02 2.18 1.00 0.52 1.62
このテキストデータ (行列) を I=3, J=4, K=1 と指定して読み込んだ結果
(交点の枠内の数字は I,J 、黒線はエッジ(=外形)、赤線はメッシュ)
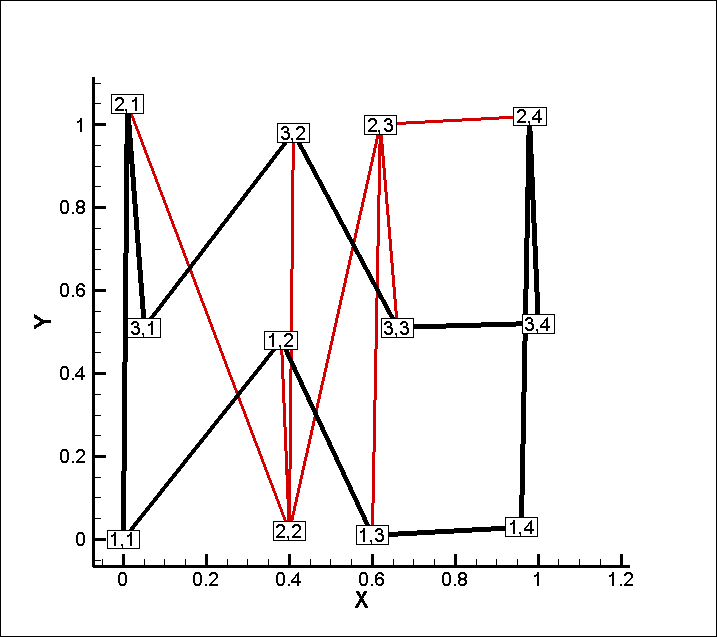
このサンプルデータの場合、ソートでは無く前述の (例1) か (例2) のように行を並べないと正しい形状は表示できません。
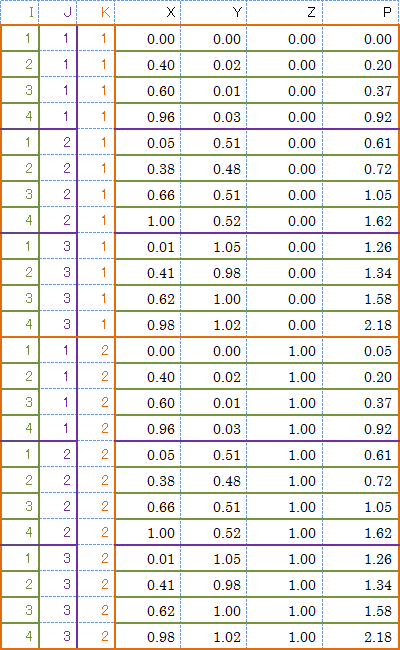
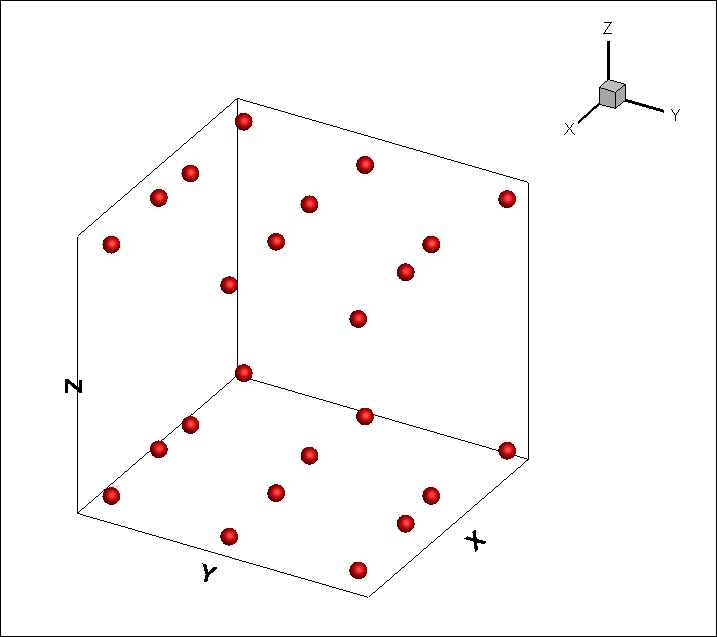
X 軸方向 4点、Y 軸方向 3点、Z 軸方向 2点、合計 24 点の測定点 (図中の赤丸) と、測定値 P があります。
|
このサンプルデータの場合、X 軸方向の測定点の数「4」と、Y 軸方向の測定点の数「3」、Z 軸方向の測定点の数「2」がインデックス I、インデックス J、インデックス K の値になります。
つまりインデックス情報 (I,J,K) として (4,3,2)、(4,2,3)、(3,4,2)、(3,2,4)、(2,4,3)、(2,3,4) のいずれかを指定します。
|
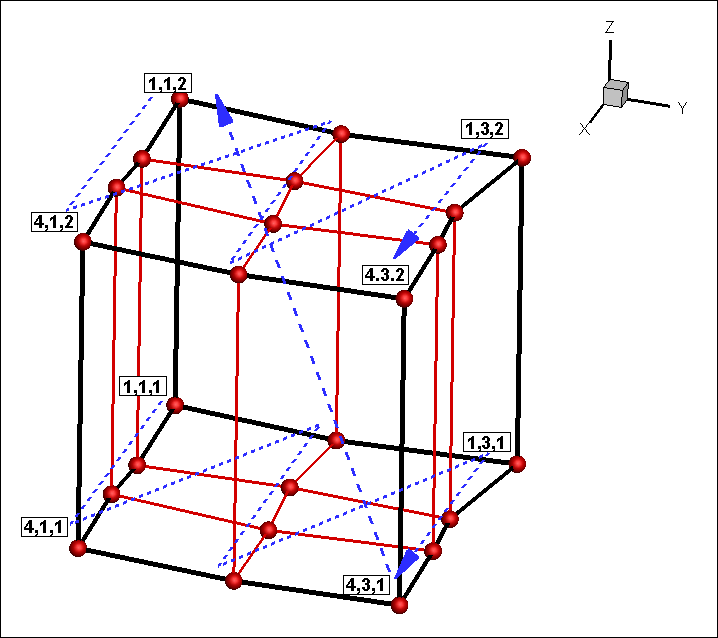
I=4, J=3, K=2 と指定した場合のインデックス割当は以下のようになります。

つまりテキストデータ (行列) の行を図中の青い破線の順に並べる必要があります。
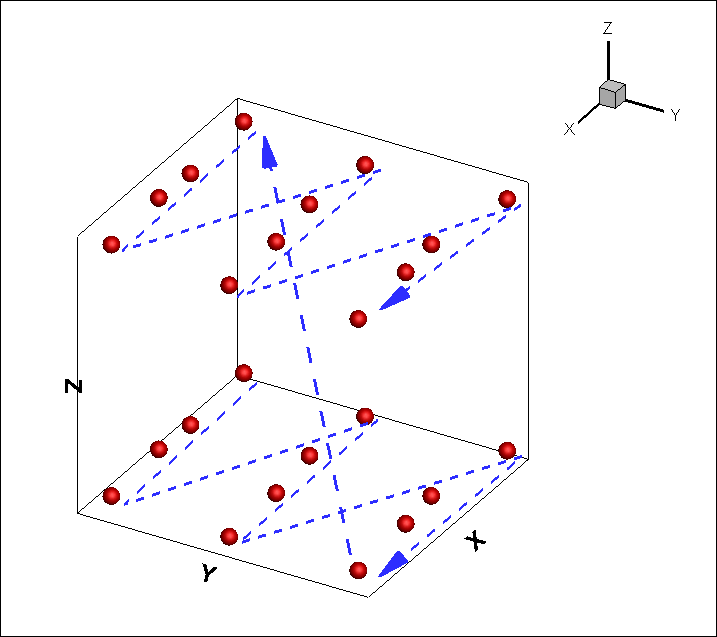
テキストデータ (行列) の行を I=4, J=3, K=2 に合わせて青い破線の順に並べ替えた結果
0 0 0 0 0.4 0.02 0 0.2 0.6 0.01 0 0.37 0.96 0.03 0 0.92 0.05 0.51 0 0.61 0.38 0.48 0 0.72 0.66 0.51 0 1.05 1 0.52 0 1.62 0.01 1.05 0 1.26 0.41 0.98 0 1.34 0.62 1 0 1.58 0.98 1.02 0 2.18 0 0 1 0.05 0.4 0.02 1 0.2 0.6 0.01 1 0.37 0.96 0.03 1 0.92 0.05 0.51 1 0.61 0.38 0.48 1 0.72 0.66 0.51 1 1.05 1 0.52 1 1.62 0.01 1.05 1 1.26 0.41 0.98 1 1.34 0.62 1 1 1.58 0.98 1.02 1 2.18