|
| サイトマップ | |
||
|
| サイトマップ | |
||
それでは、データの分析を始めましょう。画面左側のプログラムのツリーから Analysis の “Score” ノードをクリックします。 Transform オプションがメインウィンドウのツールバーに表示されます。これらのボタンを左から右に順にクリックしながら以降の分析を進めていくことになります。作業はとても簡単です。 Transform 画面には、応答の値を変換する機能が用意されています。これにより分析の統計的特性を向上させることができます。
 |
| ※ 変換 (Transformation) の詳細について: 変換の理論的背景を知りたい場合は、まず TIPS を開いてみてください。詳細が必要な場合は、メインメニューの Help コマンドにアクセスして、検索タブで 「transformations」 と入力してください。 |
今回のデータについては、変換を必要としないため、“Effects” タブをクリックして、デフォルトの None のまま先に進みます。
必然的に、チュートリアルは少し統計的な話になります。理解が難しい場合は、回帰に関する基本的な説明会に参加することをお勧めします。さらに良いのは、Stat-Ease社のDOEワークショップに参加することです。
Design-Expert には、因子 A (Bowler) に関する統計誤差 (statistical error)、すなわち、グリーンの三角形が一列に並んで表示されている正常変動と比較して、突発的な効果を強調する非常に特殊なプロットがポップアップされます。
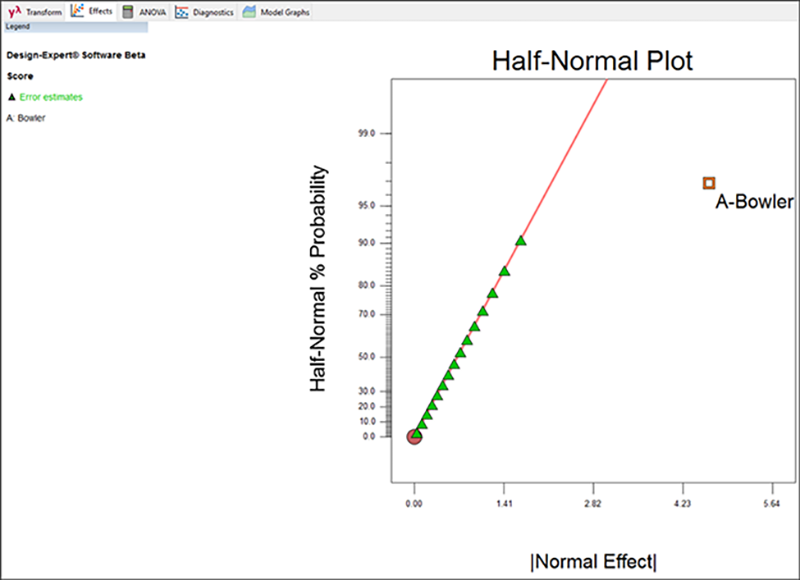 |
これは、良い結果です。生データの結果から明らかな内容が裏づけされます。まさに、ボールを投げた人物こそが重要なのです。
| ※ 半正規化プロットについて: 効果の半正規化プロットについてさらに知りたい場合は「2水準完全実施要因計画」チュートリアルを参照してください。 |
より詳細な統計結果を表示するには、 “ANOVA”(Analysis of Variance)タブに移動します。表の右端に、結果が有意であることが示されています。
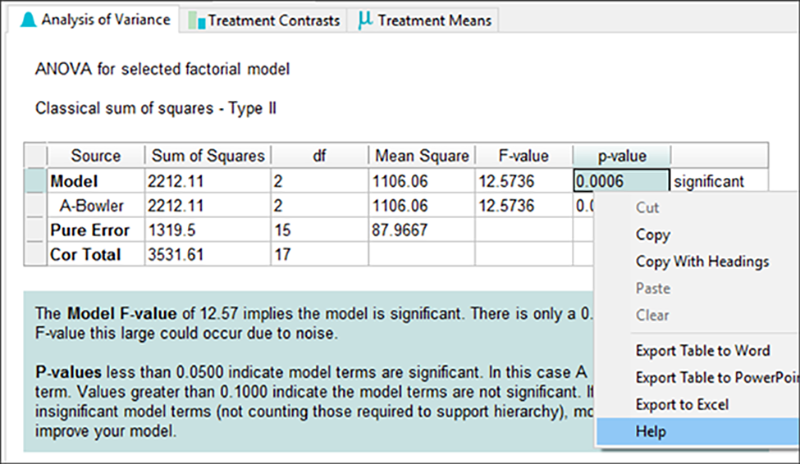 |
※ ANOVA レポートについて:画面上部のメニューから “View” -> “Show Annotation” を選んで、このオプションのチェック (0.0006 に関する TIPS を表示します (ポップアップメニューの一番下の “Help” を選択します) 。簡単なキー操作で豊富な情報が表示されるので、利用してください。 |
画面の右側の “Fit Statistics” を見て、様々な統計サマリーを確認してください。
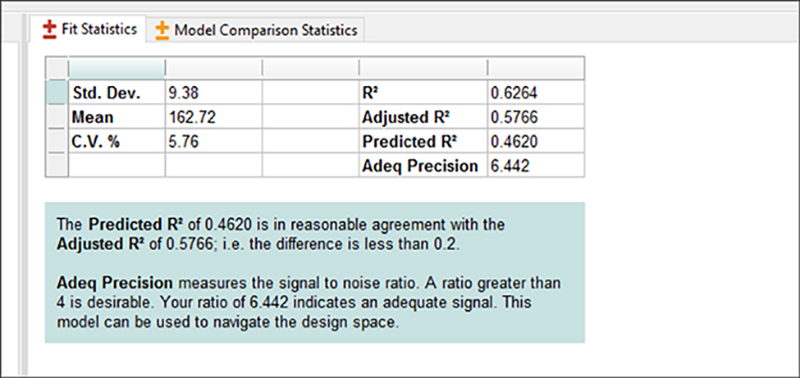 |
| ※ Post-ANOVA 統計について: これらのサマリー注釈には確認すべき内容が表示され、値を右クリック(または F1 キーを押す)してオンラインヘルプを表示することができます。たいていの場合、特定の統計情報についての役に立つアドバイスを読むことができます。 |
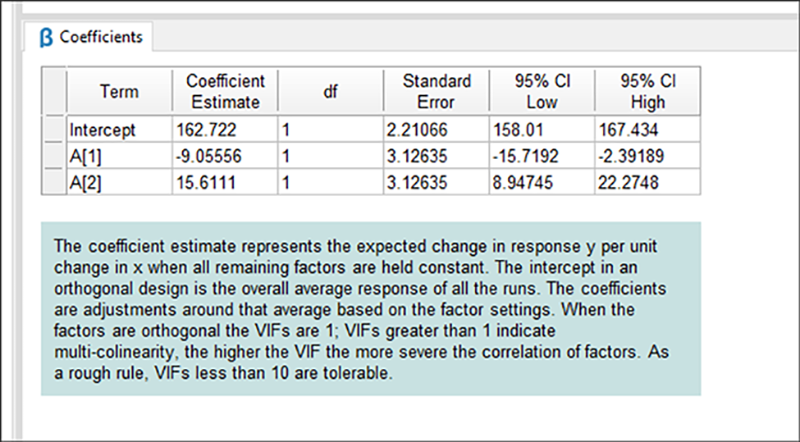
Fit Statistics の下に “Coefficients” ペインがあり、クリックすると次に示すような出力が表示されます。
|
ここでは、各モデル項の係数の算出結果や信頼区間(CI)など統計の詳細を確認できます。1因子を比較するこのような単純な実験では、3人のボウラー全体の単純な平均スコアが切片となります。3人のボウラーに対する予測モデルなのに、A1 と A2 の2つの項しかないのはどうしてか、と不思議に思われる方がいるかもしれません。全体の平均と A3 以外の2人のボウラーの平均値が分かれば、最後のモデル項 A3 はおのずと予測することができるため、これは余分なものとなるのです。
次に、この画面内の次のセクション “Treatment Means” タブに進みましょう。
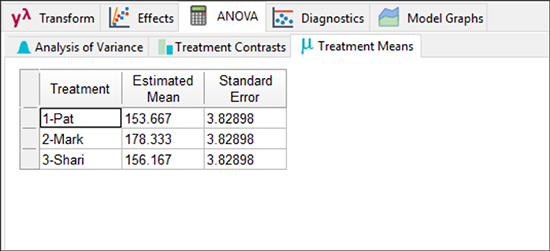 |
ここには、3人のボウラーそれぞれの平均が示されています。次に “Treatment Contrasts” タブをクリックすることで、一対毎に t-検定を使って(pair‐wise t‐tests)比較されます。
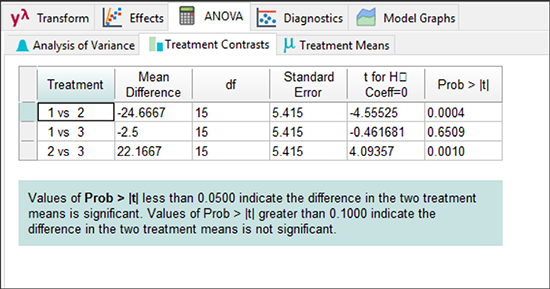 |
この処理の比較から次のような結論を導くことができます:
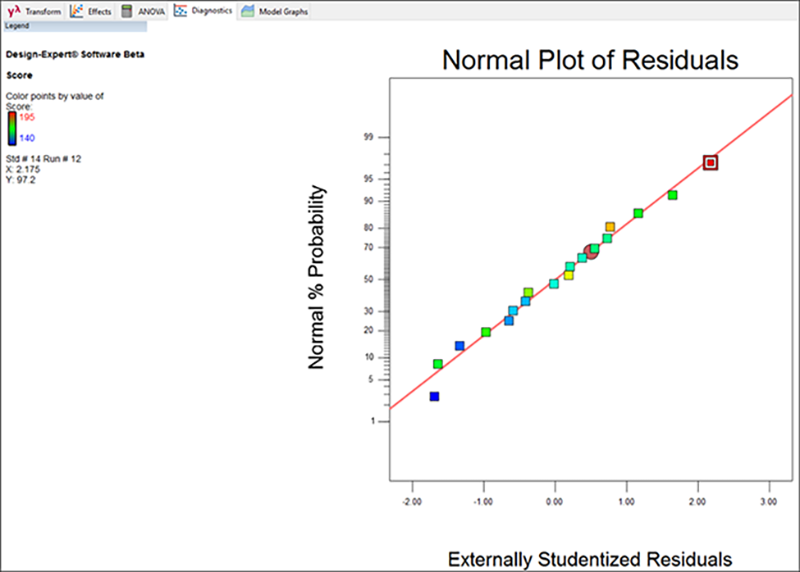
“Diagnostics ” タブをクリックすると、診断プロットが表示されます。レイアウトツールバーで、残差の通常のプロットを最大化するために単一の分割アイコンを選択してください。
 |
このプロットはラインが直線となり、ラインから外れる異常値が一切ないのが理想的です。
| ※ 鉛筆検定について: 手元に鉛筆(あるいはまっすぐなものであれば何でも)があれば、それをグラフにあててみてください。全ての点がだいたい覆われているでしょうか?この事例の場合、答えは Yes となります(正規性を調べる鉛筆検定はこれでクリアです)。赤の細いラインとそのピボット・ポイント(中央の赤い丸)は、マウスをドラッグすることで位置を変更することができます(マウスポインタをライン上に移動して、左ボタンを押しながらマウスを動かします)。ただし、ラインの位置をあえて変更するのはお薦めしません。基本的にプログラムが自動的に理想的な位置にラインを配置してくれるからです。ラインの位置を元に戻したい場合は、マウスの左ボタンをグラフ上でダブルクリックするだけでリセットできます。 |
各点は応答の水準に応じて、色分けされている点に注目してください:青色が最も低い値で、赤が最も高い値です。この例では、赤い点は Mark が最高の 195 ピンを記録したゲームです。ここで、Pat と Shari は、Mark が 195 ピンを獲得したこのゲームは極端に高すぎるので捨てるべきだと考えています。この言い分は正当でしょうか?この赤い点をクリックして、それだけを強調表示させた状態のまま、Diagnostics Tool(Diagnostics タブの上にある青いレイアウトアイコンから、一度に表示されるグラフの数を選択)を使って、残りのグラフを見ていくことにしましょう。
 |
| ※ Diagnostics ツールのドロップダウンリストについて: Diagnostics Tool ではデフォルトで “Studentized” にチェックが入っている点に注意してください。これは、オリジナルの単位(この事例ではボウリングの「ピン」)でレポートされた残差の生データを、標準偏差に基づく無次元数に変換するものです。尺度は、プラスとマイナスになります。スチューデント化の詳細はヘルプをご覧ください。Diagnostics Tool の下に表示されたロックダウンリスト内の選択を外せば残差の生データを表示することができます。実際にお試しください! | |
|
|
| ただし、試行に大きなレバレッジ(また統計用語が出てきたので、ヘルプを参照してください)がある場合は、残差をスチューデント化しなければ有効な診断グラフを得ることはできません。例えば、この事例で仮に Pat と Shari が Mark のハイスコア・ゲームを巧みに排除できたとすれば(実際はそうなりませんので、ご心配なく!)、Pat と Shari の各 6 ゲームのレバレッジはそれぞれ 0.167(1/6)であるのに対して、1ゲーム分排除された Mark の5ゲームのレバレッジはそれぞれ 0.2(1/5)となってしまいます。レバレッジにこうした不均衡が生じることのないよう、スチューデント化機能を常にオン(デフォルト指定のまま)にしておくことをお薦めします。そのため、現在 Residuals を選択している場合はデフォルトで表示される元の選択に戻してください。 | |
| *P.S. デフォルト設定における残差の表示は “外的に(externally)” 行われているという側面もあります。詳細は、「2水準完全実施要因計画」チュートリアルを参照してください。とりあえず今は統計的残差にさらに大きな検出力を提供するためにプログラムはこの形式を選択するということのみの知識で十分です。これにより、さらに Mark のハイスコアに注目せずにはいられなくなります。 |
次に、“Resid. vs. Pred.” タブを選択して、個々のゲームの残差と応答モデルによって予測されたグラフを見てみましょう。
| ※ 真偽の怪しい話について:“residuals” は、恐らく統計学者によって “error” と呼ばれるようになったのでしょうが、品質管理の人々は、これによって生じる誤解が多いことに不満を抱いています。 |
どの残差がどのボウラーであるかを区別しやすくするには、診断ツールの Color By オプションのメニューから “Bowler” を選択します。
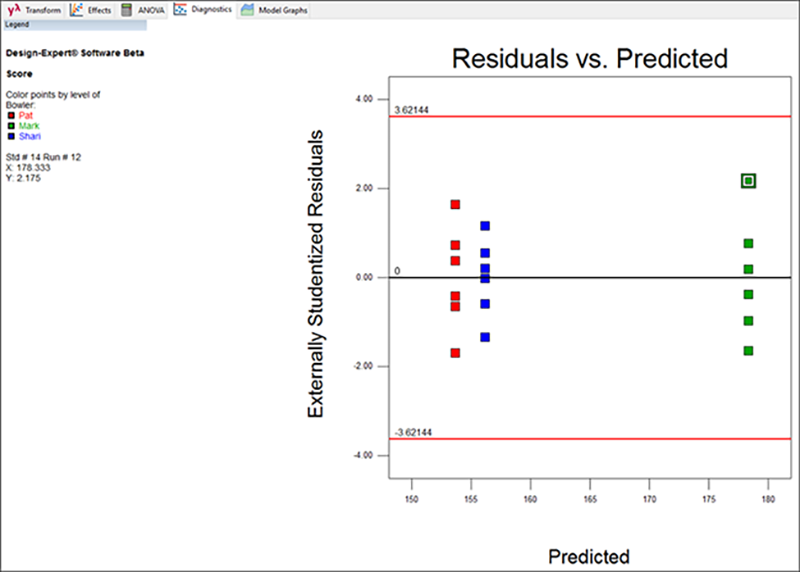 |
スチューデント化された残差は、その予測値とは無関係の大きさになります。言い換えると、スチューデント化された残差の縦方向の幅は各ボウラー間でほぼ等しくなるということです。この事例のプロットを見ると、問題は特になさそうです。Mark のゲームだけ全体として右に離れていますが、これについては驚く必要はありません。最高スコア(強調表示している点)を排除せよという申し立てがありましたが、下から上への縦方向の変動幅は、他の2人のものと比べて特別に突出しているわけではありません。
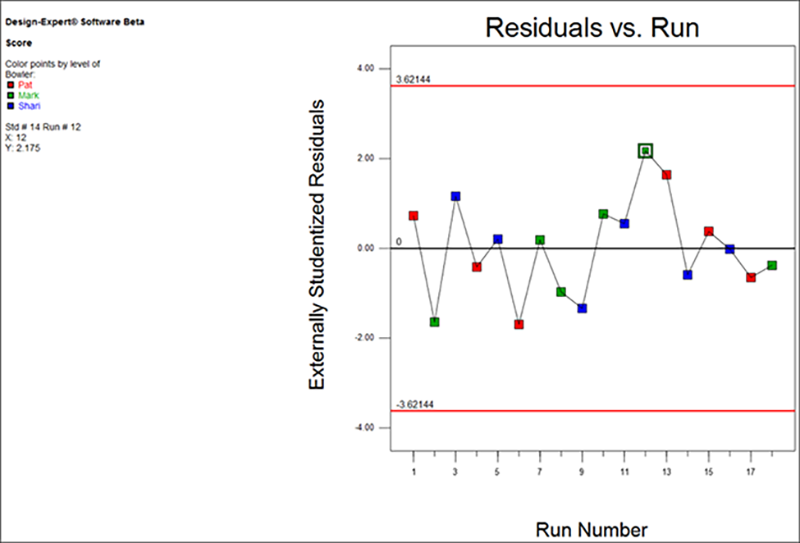
次に、 “Resid. vs. Run” タブのグラフを見てみましょう(注意:実際のグラフは無作為化により異なる場合があります)
|
このグラフでは、ボウリング場の状況(例えば、レーンのワックス塗り直し)、ボウラーの疲労、その他の時間と共に変化する隠れた変数によってもたらされる傾向が読み取れると思います。
| ※ 可能性のあるトレンドの影響について: この事例に関しては、特に問題はなさそうです。仮に極端な変動が上下に確認されたとしても、この実験の試行は完全に無作為化されているため、結果にバイアスがかかることは殆どないはずです。実験が制御されない変数によって妨害されるのを確実に防ぐには、常に無作為化を行うよう心がけてください! |
この場合さらに重要なのは、すべての点が(95 パーセントの信頼水準で計算された)範囲内におさまっていることです。 Mark の最高スコアのゲームの突出は、一般に想定される変動に過ぎないということです。従って、これを特に不適格であると見なす理由はありません。