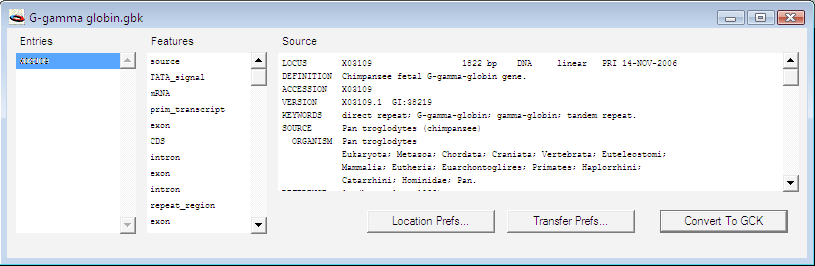
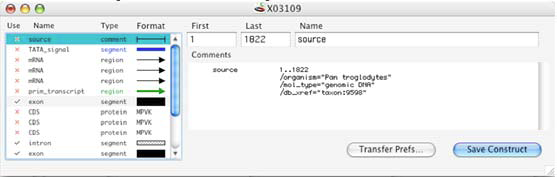
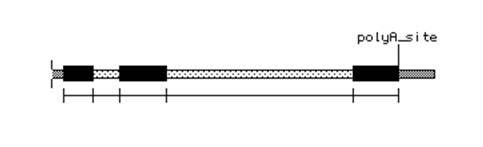
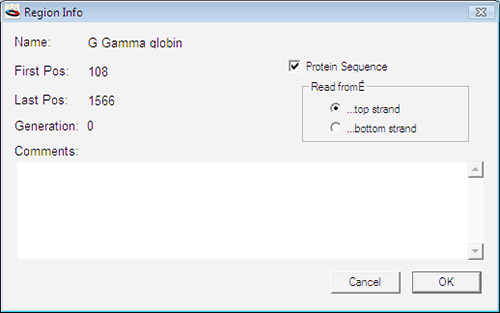
次に、Construct > Features > Make Region を選択します。これにより、選択した塩基配列の翻訳ができるようになります。ダイアログボックスに名称を入力し、Protein Sequence チェックボックスにチェックが入っているかを確認します。図 2.76 のようになっているはずです。このウィンドウで正しい設定を行ったら、OK ボタンをクリックします。これにより、エキソン領域のコドンを読み取り、イントロン領域の塩基配列を読み飛ばすことによって翻訳されたタンパク質を確認できるはずです。エキソン1とエキソン2にまたがるコドンは、実際に2つの部分に分断されている点にご注意ください (agg が ag と g で構成されている)。